Apache Kafka es una plataforma de transmisión distribuida. Con su rico conjunto de API (interfaz de programación de aplicaciones), podemos conectar casi cualquier cosa a Kafka como fuente de datos y, por otro lado, podemos configurar una gran cantidad de consumidores que recibirán el flujo de registros para su procesamiento. Kafka es altamente escalable y almacena los flujos de datos de manera confiable y tolerante a fallas. Desde la perspectiva de la conectividad, Kafka puede servir como puente entre muchos sistemas heterogéneos, que a su vez pueden confiar en sus capacidades para transferir y conservar los datos proporcionados.
En este tutorial instalaremos Apache Kafka en un Red Hat Enterprise Linux 8, crearemos el systemd unit para facilitar la administración y pruebe la funcionalidad con las herramientas de línea de comandos incluidas.
En este tutorial aprenderás:
- Cómo instalar Apache Kafka
- Cómo crear servicios systemd para Kafka y Zookeeper
- Cómo probar Kafka con clientes de línea de comandos
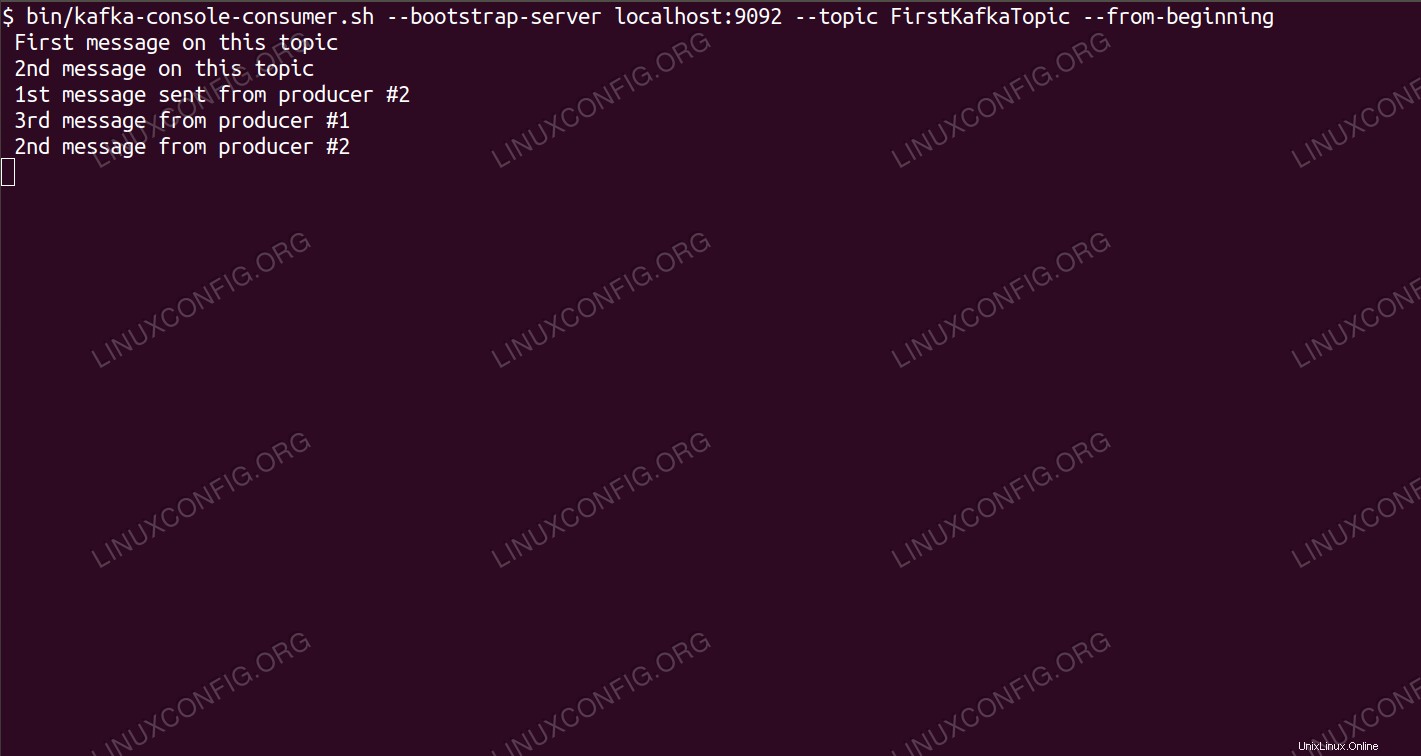
Consumo de mensajes sobre el tema de Kafka desde la línea de comandos.
Requisitos de software y convenciones utilizadas
Requisitos de software y convenciones de la línea de comandos de Linux | Categoría | Requisitos, convenciones o versión de software utilizada |
|---|
| Sistema | Red Hat Enterprise Linux 8 |
| Software | Apache Kafka 2.11 |
| Otro | Acceso privilegiado a su sistema Linux como root o a través de sudo comando. |
| Convenciones | # – requiere que los comandos de Linux dados se ejecuten con privilegios de root, ya sea directamente como usuario root o mediante el uso de sudo comando
$ – requiere que los comandos de Linux dados se ejecuten como un usuario normal sin privilegios |
Cómo instalar kafka en Redhat 8 instrucciones paso a paso
Apache Kafka está escrito en Java, por lo que todo lo que necesitamos es OpenJDK 8 instalado para continuar con la instalación. Kafka se basa en Apache Zookeeper, un servicio de coordinación distribuido, que también está escrito en Java y se envía con el paquete que descargaremos. Si bien la instalación de servicios HA (alta disponibilidad) en un solo nodo elimina su propósito, instalaremos y ejecutaremos Zookeeper por el bien de Kafka.
- Para descargar Kafka desde el espejo más cercano, debemos consultar el sitio de descarga oficial. Podemos copiar la URL del
.tar.gz archivo desde allí. Usaremos wget y la URL pegada para descargar el paquete en la máquina de destino:# wget https://www-eu.apache.org/dist/kafka/2.1.0/kafka_2.11-2.1.0.tgz -O /opt/kafka_2.11-2.1.0.tgz
- Ingresamos el
/opt y extraiga el archivo:# cd /opt
# tar -xvf kafka_2.11-2.1.0.tgz
Y crea un enlace simbólico llamado /opt/kafka que apunta al /opt/kafka_2_11-2.1.0 ahora creado directorio para hacernos la vida más fácil.
ln -s /opt/kafka_2.11-2.1.0 /opt/kafka
- Creamos un usuario sin privilegios que ejecutará tanto
zookeeper y kafka servicio.# useradd kafka
- Y establezca al nuevo usuario como propietario de todo el directorio que extrajimos, recursivamente:
# chown -R kafka:kafka /opt/kafka*
- Creamos el archivo de unidad
/etc/systemd/system/zookeeper.service con el siguiente contenido:
[Unit]
Description=zookeeper
After=syslog.target network.target
[Service]
Type=simple
User=kafka
Group=kafka
ExecStart=/opt/kafka/bin/zookeeper-server-start.sh /opt/kafka/config/zookeeper.properties
ExecStop=/opt/kafka/bin/zookeeper-server-stop.sh
[Install]
WantedBy=multi-user.target
Tenga en cuenta que no necesitamos escribir el número de versión tres veces debido al enlace simbólico que creamos. Lo mismo se aplica al siguiente archivo de unidad para Kafka, /etc/systemd/system/kafka.service , que contiene las siguientes líneas de configuración:
[Unit]
Description=Apache Kafka
Requires=zookeeper.service
After=zookeeper.service
[Service]
Type=simple
User=kafka
Group=kafka
ExecStart=/opt/kafka/bin/kafka-server-start.sh /opt/kafka/config/server.properties
ExecStop=/opt/kafka/bin/kafka-server-stop.sh
[Install]
WantedBy=multi-user.target
- Necesitamos recargar
systemd para obtenerlo, lea los archivos de la nueva unidad:
# systemctl daemon-reload
- Ahora podemos iniciar nuestros nuevos servicios (en este orden):
# systemctl start zookeeper
# systemctl start kafka
Si todo va bien, systemd debe informar el estado de ejecución en el estado de ambos servicios, similar a los resultados a continuación:
# systemctl status zookeeper.service
zookeeper.service - zookeeper
Loaded: loaded (/etc/systemd/system/zookeeper.service; disabled; vendor preset: disabled)
Active: active (running) since Thu 2019-01-10 20:44:37 CET; 6s ago
Main PID: 11628 (java)
Tasks: 23 (limit: 12544)
Memory: 57.0M
CGroup: /system.slice/zookeeper.service
11628 java -Xmx512M -Xms512M -server [...]
# systemctl status kafka.service
kafka.service - Apache Kafka
Loaded: loaded (/etc/systemd/system/kafka.service; disabled; vendor preset: disabled)
Active: active (running) since Thu 2019-01-10 20:45:11 CET; 11s ago
Main PID: 11949 (java)
Tasks: 64 (limit: 12544)
Memory: 322.2M
CGroup: /system.slice/kafka.service
11949 java -Xmx1G -Xms1G -server [...]
- Opcionalmente, podemos habilitar el inicio automático en el arranque para ambos servicios:
# systemctl enable zookeeper.service
# systemctl enable kafka.service
- Para probar la funcionalidad, nos conectaremos a Kafka con un productor y un cliente consumidor. Los mensajes proporcionados por el productor deben aparecer en la consola del consumidor. Pero antes de esto necesitamos un medio en el que estos dos intercambien mensajes. Creamos un nuevo canal de datos llamado
topic en los términos de Kafka, dónde publicará el proveedor y dónde se suscribirá el consumidor. Llamaremos al tema
FirstKafkaTopic . Usaremos el kafka usuario para crear el tema: $ /opt/kafka/bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic FirstKafkaTopic
- Iniciamos un cliente consumidor desde la línea de comando que se suscribirá al tema (en este momento vacío) creado en el paso anterior:
$ /opt/kafka/bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic FirstKafkaTopic --from-beginning
Dejamos abierta la consola y el cliente que corre en ella. Esta consola es donde recibiremos el mensaje que publiquemos con el cliente productor.
- En otra terminal, iniciamos un cliente productor y publicamos algunos mensajes en el tema que creamos. Podemos consultar Kafka sobre los temas disponibles:
$ /opt/kafka/bin/kafka-topics.sh --list --zookeeper localhost:2181
FirstKafkaTopic
Y conéctese al que está suscrito el consumidor, luego envíe un mensaje:
$ /opt/kafka/bin/kafka-console-producer.sh --broker-list localhost:9092 --topic FirstKafkaTopic
> new message published by producer from console #2
En la terminal del consumidor, el mensaje debería aparecer en breve:
$ /opt/kafka/bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic FirstKafkaTopic --from-beginning
new message published by producer from console #2
Si aparece el mensaje, nuestra prueba es exitosa y nuestra instalación de Kafka funciona según lo previsto. Muchos clientes podrían proporcionar y consumir uno o más registros de temas de la misma manera, incluso con la configuración de un solo nodo que creamos en este tutorial.