Introducción
MySQL es una popular aplicación de base de datos de código abierto que almacena y estructura datos de una manera significativa y de fácil acceso. Con aplicaciones grandes, la gran cantidad de datos puede provocar problemas de rendimiento.
Esta guía proporciona varios consejos de ajuste sobre cómo mejorar el rendimiento de una base de datos MySQL .

Requisitos previos
- Un sistema Linux con MySQL instalado y funcionando, Centos o Ubuntu
- Una base de datos existente
- Credenciales de administrador para el sistema operativo y la base de datos
Ajuste del rendimiento de MySQL del sistema
A nivel del sistema, ajustará las opciones de hardware y software para mejorar el rendimiento de MySQL.
1. Equilibre los cuatro principales recursos de hardware

Almacenamiento
Tómese un momento para evaluar su almacenamiento. Si usa unidades de disco duro (HDD) tradicionales, puede actualizar a unidades de estado sólido (SSD) para mejorar el rendimiento.
Usa una herramienta como iotop o sar desde el sysstat paquete para monitorear las tasas de entrada/salida de su disco. Si el uso del disco es mucho mayor que el uso de otros recursos, considere agregar más almacenamiento o actualizar a un almacenamiento más rápido.
Procesador
Los procesadores generalmente se consideran la medida de qué tan rápido es su sistema. Usa la parte superior de Linux comando para obtener un desglose de cómo se utilizan sus recursos. Preste atención a los procesos de MySQL y el porcentaje de uso del procesador que requieren.
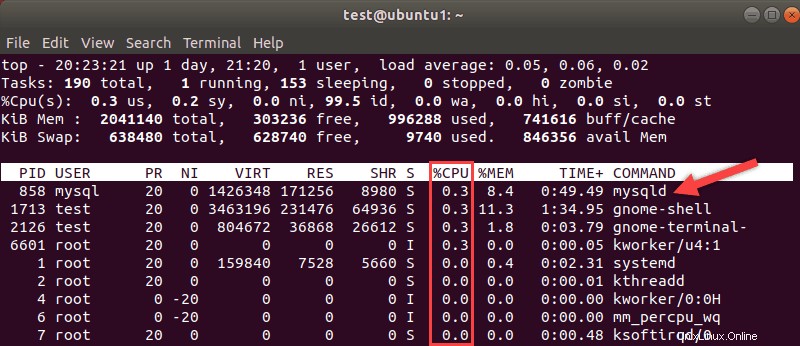
Los procesadores son más costosos de actualizar, pero si su CPU es un cuello de botella, es posible que sea necesaria una actualización.
Memoria
La memoria representa la cantidad total de RAM en su servidor de almacenamiento de base de datos MySQL. Puede ajustar la memoria caché (más sobre esto más adelante) para mejorar el rendimiento . Si no tiene suficiente memoria o si la memoria existente no está optimizada, puede terminar dañando su rendimiento en lugar de mejorarlo.
Al igual que otros cuellos de botella, si su servidor se queda constantemente sin memoria, puede actualizar agregando más. Si se queda sin memoria, su servidor almacenará en caché el almacenamiento de datos (como un disco duro) para que actúe como memoria. El almacenamiento en caché de la base de datos ralentiza su rendimiento.
Red
Es importante monitorear el tráfico de la red para asegurarse de tener suficiente infraestructura para administrar la carga.
La sobrecarga de su red puede provocar latencia, caída de paquetes e incluso interrupciones del servidor. Asegúrese de tener suficiente ancho de banda de red para acomodar sus niveles normales de tráfico de base de datos.
2. Utilice InnoDB, no MyISAM
MiISAM es un estilo de base de datos más antiguo utilizado para algunas bases de datos MySQL. Es un diseño de base de datos menos eficiente. El InnoDB más nuevo admite funciones más avanzadas y tiene mecanismos de optimización incorporados.
InnoDB utiliza un índice agrupado y mantiene los datos en páginas, que se almacenan en bloques físicos consecutivos. Si un valor es demasiado grande para una página, InnoDB lo mueve a otra ubicación y luego indexa el valor. Esta función ayuda a mantener los datos relevantes en el mismo lugar en el dispositivo de almacenamiento, lo que significa que el disco duro físico tarda menos tiempo en acceder a los datos.
3. Utilice la última versión de MySQL
El uso de la última versión no siempre es factible para bases de datos antiguas y heredadas. Pero siempre que sea posible, debe verificar la versión de MySQL en uso y actualizar a la última.
Una parte del desarrollo en curso incluye mejoras de rendimiento. Algunos ajustes de rendimiento comunes pueden quedar obsoletos con las versiones más recientes de MySQL. En general, siempre es mejor usar la mejora de rendimiento de MySQL nativo en lugar de scripts y archivos de configuración.
Ajuste del rendimiento de MySQL del software
El ajuste del rendimiento de SQL es el proceso de maximizar las velocidades de consulta en una base de datos relacional. La tarea generalmente involucra múltiples herramientas y técnicas.
Estos métodos implican:
- Ajustando los archivos de configuración de MySQL.
- Escribiendo consultas de bases de datos más eficientes.
- Estructurar la base de datos para recuperar datos de manera más eficiente.
4. Considere el uso de una herramienta automática de mejora del rendimiento
Como ocurre con la mayoría del software, no todas las herramientas funcionan en todas las versiones de MySQL. Examinaremos tres utilidades para evaluar su base de datos MySQL y recomendaremos cambios para mejorar el rendimiento.
El primero es tuning-primer. Esta herramienta es un poco más antigua, diseñada para MySQL 5.5 – 5.7. Puede analizar su base de datos y sugerir configuraciones para mejorar el rendimiento. Por ejemplo, puede sugerirle que aumente el query_cache_size parámetro si parece que su sistema no puede procesar las consultas lo suficientemente rápido como para mantener el caché limpio.
La segunda herramienta de ajuste, útil para la mayoría de las bases de datos SQL modernas, es MySQLTuner. Este script (mysqltuner.pl ) está escrito en Perl. Al igual que tuning-primer, analiza la configuración de su base de datos en busca de cuellos de botella e ineficiencias. El resultado muestra métricas y recomendaciones:
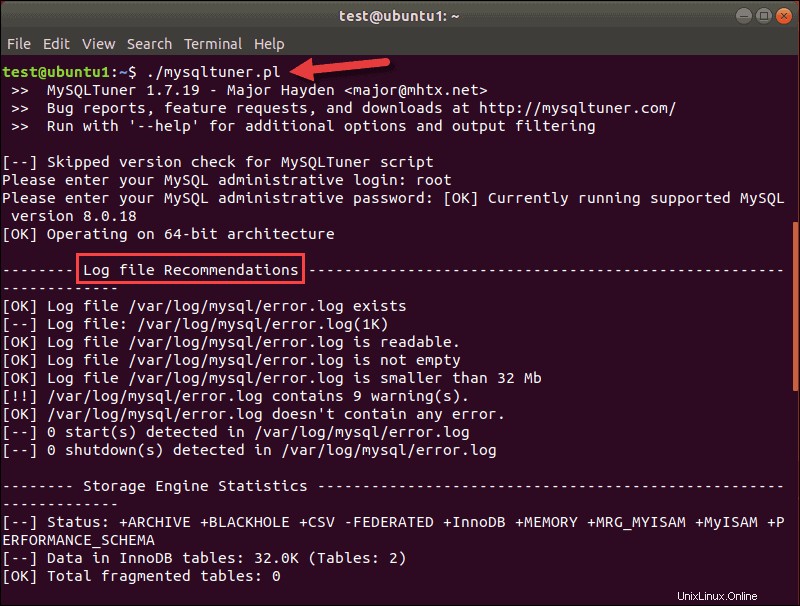
En la parte superior de la salida, puede ver la versión de la herramienta MySQLTuner y su base de datos.
El script funciona con MySQL 8.x. Las recomendaciones de archivos de registro son las primeras de la lista, pero si se desplaza hasta el final, puede ver recomendaciones generales para mejorar el rendimiento de MySQL.
La tercera utilidad, que quizás ya tenga, es el phpMyAdmin Advisor . Al igual que las otras dos utilidades, evalúa su base de datos y recomienda ajustes. Si ya está usando phpMyAdmin, el Asesor es una herramienta útil que puede usar dentro de la GUI.
5. Optimizar consultas
Una consulta es una solicitud codificada para buscar en la base de datos datos que coincidan con un determinado valor. Hay algunos operadores de consulta que, por su propia naturaleza, tardan mucho tiempo en ejecutarse. Las técnicas de ajuste del rendimiento de SQL ayudan a optimizar las consultas para mejorar los tiempos de ejecución.
La detección de consultas con poco tiempo de ejecución es una de las principales tareas de optimización del rendimiento. Las consultas comúnmente implementadas en grandes conjuntos de datos son lentas y ocupan bases de datos. Por lo tanto, las tablas no están disponibles para ninguna otra tarea.
Por ejemplo, una base de datos OLTP requiere transacciones rápidas y un procesamiento de consultas efectivo. Ejecutar una consulta ineficiente bloquea el uso de la base de datos y detiene las actualizaciones de información.
Si su entorno se basa en consultas automatizadas, como activadores, es posible que afecten al rendimiento. Verifique y finalice los procesos de MySQL que pueden acumularse en el tiempo.
6. Utilice índices cuando corresponda
Muchas consultas de bases de datos usan una estructura similar a esta:
SELECT … WHEREEstas consultas implican evaluar, filtrar y recuperar resultados. Puede reestructurarlos agregando un pequeño conjunto de índices para las tablas relacionadas. La consulta se puede dirigir al índice para acelerar la consulta.
7. Funciones en Predicados
Evite usar una función en el predicado de una consulta. Por ejemplo:
SELECT * FROM MYTABLE WHERE UPPER(COL1)='123'Copy
El UPPER notación crea una función, que debe operar durante el SELECT operación. Esto duplica el trabajo que está haciendo la consulta y debe evitarlo si es posible.
8. Evitar % comodín en un predicado
Al buscar a través de datos textuales, los comodines ayudan a realizar una búsqueda más amplia. Por ejemplo, para seleccionar todos los nombres que comienzan con ch , cree un índice en la columna de nombre y ejecute:
SELECT * FROM person WHERE name LIKE "ch%"La consulta escanea los índices, lo que reduce el costo de la consulta:

Sin embargo, hacer una búsqueda de nombres usando los comodines al principio aumenta significativamente el costo de la consulta porque un escaneo de indexación no se aplica a los extremos de las cadenas:
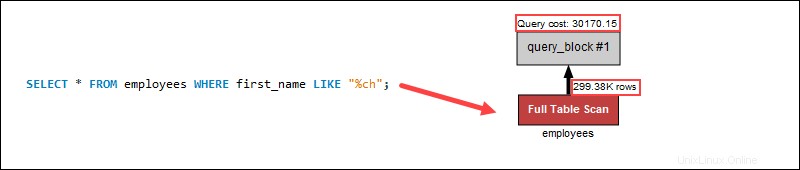
Un comodín al comienzo de una búsqueda no aplica la indexación. En su lugar, un escaneo completo de la tabla busca en cada fila individualmente, lo que aumenta el costo de la consulta en el proceso. En la consulta de ejemplo, usar un comodín al final ayuda a reducir el costo de la consulta debido a que pasa por menos filas de la tabla.
Una forma de buscar los extremos de las cadenas es invertir la cadena, indexar las cadenas invertidas y observar los caracteres iniciales. Al colocar el comodín al final, ahora se busca el comienzo de la cadena invertida, lo que hace que la búsqueda sea más eficiente.
9. Especificar columnas en la función SELECCIONAR
Una expresión de uso común para consultas analíticas y exploratorias es SELECT * . Seleccionar más de lo que necesita da como resultado una pérdida de rendimiento y una redundancia innecesarias. Si especifica las columnas que necesita, su consulta no necesitará escanear columnas irrelevantes.
Si se necesitan todas las columnas, no hay otra forma de hacerlo. Sin embargo, la mayoría de los requisitos comerciales no necesitan que todas las columnas estén disponibles dentro de un conjunto de datos. Considere seleccionar columnas específicas en su lugar.
Para resumir, evite usar:
SELECT * FROM tableEn su lugar, intente:
SELECT column1, column2 FROM table10. Utilice ORDER BY adecuadamente
El ORDER BY expresión ordena los resultados por la columna especificada. Se puede utilizar para ordenar por dos columnas a la vez. Estos deben ordenarse en el mismo orden, ascendente o descendente.
Si intenta clasificar diferentes columnas en un orden diferente, se ralentizará el rendimiento. Puede combinar esto con un índice para acelerar la clasificación.
11. AGRUPAR POR En lugar de SELECCIONAR DISTINTO
El SELECCIONE DISTINTO consulta es útil cuando se trata de deshacerse de los valores duplicados. Sin embargo, la declaración requiere una gran cantidad de poder de procesamiento.
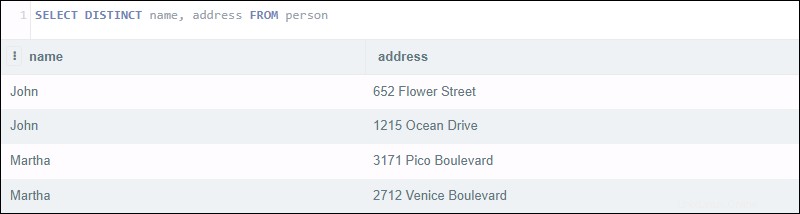
Siempre que sea posible, evite usar SELECT DISTINCT , ya que es muy ineficiente y, a veces, confuso. Por ejemplo, si una tabla enumera información sobre clientes con la siguiente estructura:
| id | nombre | apellido | dirección | ciudad | estado | zip |
|---|---|---|---|---|---|---|
| 0 | Juan | Smith | Calle de las Flores 652 | Los Ángeles | CA | 90017 |
| 1 | Juan | Smith | 1215 Ocean Boulevard | Los Ángeles | CA | 90802 |
| 2 | Marta | Mateo | 3104 Pico Bulevar | Los Ángeles | CA | 90019 |
| 3 | Marta | Jones | 2712 Bulevar de Venecia | Los Ángeles | CA | 90019 |