Introducción
HDFS (Hadoop Distributed File System) es un componente vital del proyecto Apache Hadoop. Hadoop es un ecosistema de software que funciona en conjunto para ayudarlo a administrar big data. Los dos elementos principales de Hadoop son:
- MapaReducir – responsable de ejecutar tareas
- HDFS – responsable de mantener los datos
En este artículo hablaremos del segundo de los dos módulos. aprenderás qué es HDFS, cómo funciona y la terminología básica de HDFS .

¿Qué es HDFS?
Hadoop Distributed File System es un sistema de archivos de almacenamiento de datos tolerante a fallas que se ejecuta en hardware básico. Fue diseñado para superar los desafíos que las bases de datos tradicionales no podían. Por lo tanto, todo su potencial solo se utiliza cuando se manejan grandes datos.
Los principales problemas que tuvo que resolver el sistema de archivos Hadoop fueron la velocidad , costo y fiabilidad .
¿Cuáles son los beneficios de HDFS?
Los beneficios de HDFS son, de hecho, soluciones que proporciona el sistema de archivos para los desafíos mencionados anteriormente:
- Es rápido. Puede entregar más de 2 GB de datos por segundo gracias a su arquitectura de clúster.
- Es gratis. HDFS es un software de código abierto que viene sin costo de licencia o soporte.
- Es fiable. El sistema de archivos almacena múltiples copias de datos en sistemas separados para garantizar que siempre se pueda acceder a ellos.
Estas ventajas son especialmente significativas cuando se trata de big data y fueron posibles gracias a la forma particular en que HDFS maneja los datos.
¿Cómo almacena HDFS los datos?
HDFS divide los archivos en bloques y almacena cada bloque en un DataNode. Varios DataNodes están vinculados al nodo maestro en el clúster, el NameNode. El nodo principal distribuye réplicas de estos bloques de datos en todo el clúster. También indica al usuario dónde encontrar la información deseada.
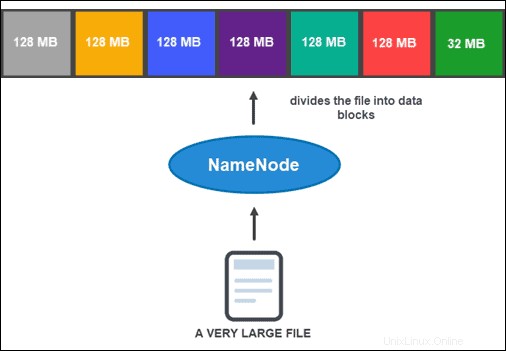
Sin embargo, antes de que NameNode pueda ayudarlo a almacenar y administrar los datos, primero debe particionar el archivo en bloques de datos más pequeños y manejables. Este proceso se llama división de bloques de datos .
División de bloques de datos
De forma predeterminada, un bloque no puede tener más de 128 MB de tamaño. El número de bloques depende del tamaño inicial del archivo. Todos menos el último bloque tienen el mismo tamaño (128 MB), mientras que el último es lo que queda del archivo.
Por ejemplo, un archivo de 800 MB se divide en siete bloques de datos. Seis de los siete bloques son de 128 MB, mientras que el séptimo bloque de datos son los 32 MB restantes.
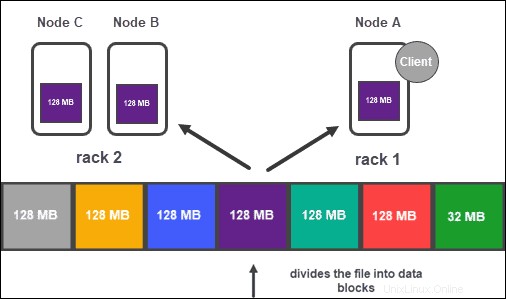
Luego, cada bloque se replica en varias copias.
Replicación de datos
Según la configuración del clúster, NameNode crea una cantidad de copias de cada bloque de datos mediante el método de replicación. .
Se recomienda tener al menos tres réplicas, que también es la configuración predeterminada. El nodo maestro los almacena en DataNodes separados del clúster. El estado de los nodos se supervisa de cerca para garantizar que los datos estén siempre disponibles.
Para garantizar una alta accesibilidad, confiabilidad y tolerancia a fallas, los desarrolladores recomiendan configurar las tres réplicas utilizando la siguiente topología:
- Almacenar la primera réplica en el nodo donde se encuentra el cliente.
- Luego, almacene la segunda réplica en un estante diferente.
- Finalmente, guarde la tercera réplica en el mismo bastidor que la segunda réplica, pero en un nodo diferente.
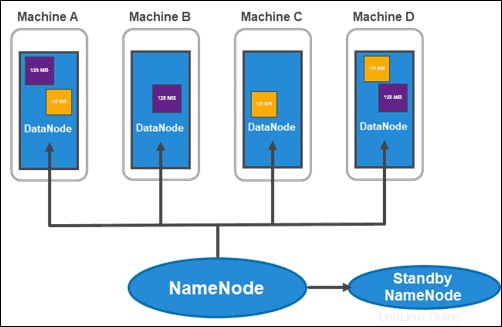
Arquitectura HDFS:NameNodes y DataNodes
HDFS tiene una arquitectura maestro-esclavo. El nodo maestro es el NameNode , que gestiona varios nodos esclavos dentro del clúster, conocidos como DataNodes .
Nodos de nombre
Hadoop 2.x introdujo la posibilidad de tener múltiples NameNodes por rack. Esta novedad era bastante significativa ya que tener un único nodo maestro con toda la información dentro del clúster suponía una gran vulnerabilidad.
El clúster habitual consta de dos NameNodes:
- un NameNode activo
- y un NameNode en espera
Mientras que el primero se ocupa de todas las operaciones del cliente dentro del clúster, el segundo se mantiene sincronizado con todo su trabajo si es necesario realizar una conmutación por error.
El NameNode activo realiza un seguimiento de los metadatos de cada bloque de datos y sus réplicas. Esto incluye el nombre del archivo, el permiso, la ID, la ubicación y el número de réplicas. Guarda toda la información en una fsimage , una imagen de espacio de nombres almacenada en la memoria local del sistema de archivos. Además, mantiene registros de transacciones llamados EditLogs , que registran todos los cambios realizados en el sistema.
El propósito principal del Nombre Standby es resolver el problema del punto único de falla. Lee cualquier cambio realizado en EditLogs y lo aplica a su NameSpace (los archivos y los directorios en los datos). Si el nodo principal falla, el servicio Zookeeper lleva a cabo la conmutación por error y permite que el nodo en espera mantenga una sesión activa.
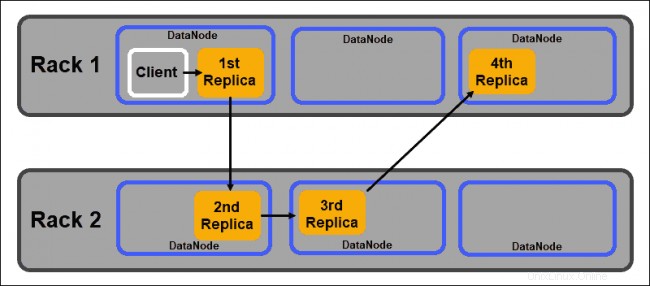
Nodos de datos
Los DataNodes son demonios esclavos que almacenan bloques de datos asignados por NameNode. Como se mencionó anteriormente, la configuración predeterminada garantiza que cada bloque de datos tenga tres réplicas. Puede cambiar el número de réplicas, sin embargo, no es recomendable bajar de tres.
Las réplicas deben distribuirse de acuerdo con el Conocimiento de bastidores de Hadoop. política que señala que:
- El número de réplicas debe ser mayor que el número de bastidores.
- Un DataNode puede almacenar solo una réplica de un bloque de datos.
- Un rack no puede almacenar más de dos réplicas de un bloque de datos.
Siguiendo estas pautas, puede:
- Maximice el ancho de banda de la red.
- Proteja contra la pérdida de datos.
- Mejore el rendimiento y la confiabilidad.
Características clave de HDFS
Estas son las principales características del Sistema de Archivos Distribuidos de Hadoop:
Uso de HDFS en la vida real
Las empresas que manejan grandes volúmenes de datos comenzaron hace mucho tiempo a migrar a Hadoop, una de las soluciones líderes para procesar big data debido a sus capacidades de almacenamiento y análisis.
Servicios financieros. El sistema de archivos distribuidos de Hadoop está diseñado para admitir datos que se espera que crezcan exponencialmente. El sistema es escalable sin el peligro de ralentizar el procesamiento de datos complejos.
Minorista. Dado que conocer a sus clientes es un componente fundamental para el éxito en la industria minorista, muchas empresas conservan grandes cantidades de datos de clientes estructurados y no estructurados. Utilizan Hadoop para realizar un seguimiento y analizar los datos recopilados para ayudar a planificar futuros inventarios, precios, campañas de marketing y otros proyectos.
Telecomunicaciones. La industria de las telecomunicaciones gestiona enormes cantidades de datos y tiene que procesarlos en una escala de petabytes. Utiliza análisis de Hadoop para administrar registros de datos de llamadas, análisis de tráfico de red y otros procesos relacionados con las telecomunicaciones.
Industria energética. La industria energética siempre está buscando formas de mejorar la eficiencia energética. Se basa en sistemas como Hadoop y su sistema de archivos para ayudar a analizar y comprender los patrones y prácticas de consumo.
Seguro. Las compañías de seguros médicos dependen del análisis de datos. Estos resultados sirven como base para la forma en que formulan e implementan políticas. Para las compañías de seguros, la información sobre el historial del cliente es invaluable. Tener la capacidad de mantener una base de datos de fácil acceso mientras crece continuamente es la razón por la que tantos han recurrido a Apache Hadoop.