Introducción
Este tutorial es el primero de una serie de artículos que se centran en Kubernetes y el concepto de implementación de contenedores. Kubernetes es una herramienta utilizada para administrar clústeres de aplicaciones en contenedores. En informática, este proceso se suele denominar orquestación. .
La analogía con una orquesta de música es, en muchos sentidos, adecuada. Al igual que lo haría un conductor, Kubernetes coordina muchos microservicios que juntos forman una aplicación útil. Kubernetes supervisa el clúster de forma automática y permanente y realiza ajustes en sus componentes.
Comprender la arquitectura de Kubernetes es crucial para implementar y mantener aplicaciones en contenedores.
¿Qué es Kubernetes?
Kubernetes o k8s para abreviar, es un sistema para automatizar la implementación de aplicaciones. Las aplicaciones modernas están dispersas en nubes, máquinas virtuales y servidores. Administrar aplicaciones manualmente ya no es una opción viable.
K8s transforma máquinas virtuales y físicas en una superficie API unificada. Luego, un desarrollador puede usar la API de Kubernetes para implementar, escalar y administrar aplicaciones en contenedores.
Su arquitectura también proporciona un marco flexible para sistemas distribuidos. K8s organiza automáticamente el escalado y las conmutaciones por error para sus aplicaciones y proporciona patrones de implementación.
Ayuda a administrar los contenedores que ejecutan las aplicaciones y garantiza que no haya tiempo de inactividad en un entorno de producción. Por ejemplo, si un contenedor se cae, otro contenedor automáticamente ocupa su lugar sin que el usuario final se dé cuenta.
Kubernetes no es solo un sistema de orquestación. Es un conjunto de procesos de control independientes e interconectados. Su función es trabajar continuamente en el estado actual y mover los procesos en la dirección deseada.
Consulte nuestro artículo sobre Qué es Kubernetes si desea obtener más información sobre la orquestación de contenedores.
Arquitectura y componentes de Kubernetes
Kubernetes tiene una arquitectura descentralizada que no maneja las tareas secuencialmente. Funciona en base a un modelo declarativo e implementa el concepto de un 'estado deseado .’ Estos pasos ilustran el proceso básico de Kubernetes:
- Un administrador crea y coloca el estado deseado de una aplicación en un archivo de manifiesto.
- El archivo se proporciona al servidor API de Kubernetes mediante una CLI o una interfaz de usuario. La herramienta de línea de comandos predeterminada de Kubernetes se llama kubectl . En caso de que necesite una lista completa de los comandos de kubectl, consulte nuestra hoja de trucos de Kubectl.
- Kubernetes almacena el archivo (el estado deseado de una aplicación) en una base de datos llamada Almacén de valores-clave (etcd) .
- Luego, Kubernetes implementa el estado deseado en todas las aplicaciones relevantes dentro del clúster.
- Kubernetes monitorea continuamente los elementos del clúster para asegurarse de que el estado actual de la aplicación no varíe del estado deseado.
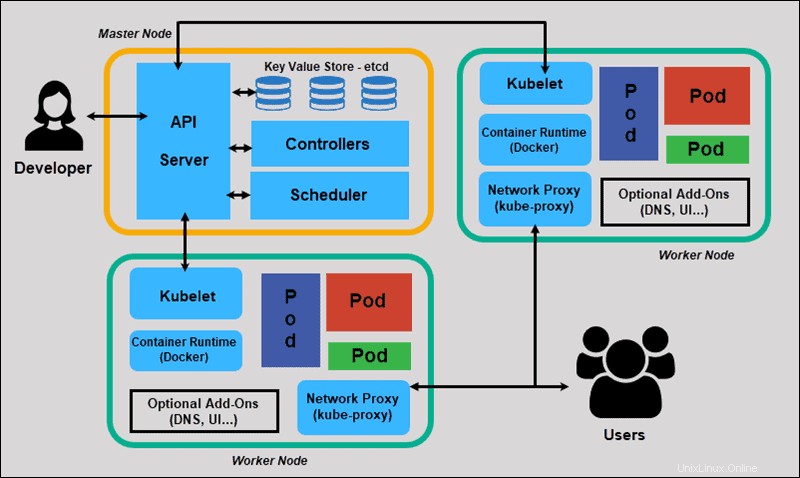
Ahora exploraremos los componentes individuales de un clúster estándar de Kubernetes para comprender el proceso con mayor detalle.
¿Qué es el nodo maestro en la arquitectura de Kubernetes?
El maestro de Kubernetes (nodo maestro) recibe información de una CLI (interfaz de línea de comandos) o una IU (interfaz de usuario) a través de una API. Estos son los comandos que proporciona a Kubernetes.
Usted define los pods, los conjuntos de réplicas y los servicios que desea que mantenga Kubernetes. Por ejemplo, qué imagen de contenedor usar, qué puertos exponer y cuántas réplicas de pod ejecutar.
También proporciona los parámetros del estado deseado para las aplicaciones que se ejecutan en ese clúster.
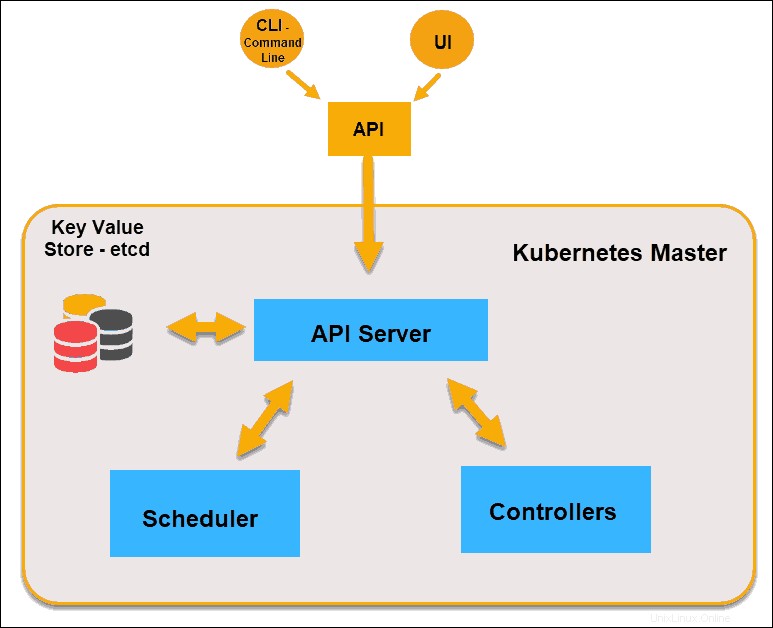
Nodo principal de Kubernetes
Servidor API
El Servidor API es el front-end del plano de control y el único componente en el plano de control con el que interactuamos directamente. Los componentes internos del sistema, así como los componentes externos del usuario, se comunican a través de la misma API.
Almacenamiento de clave-valor (etcd)
El almacén de valores-clave, también llamado etcd , es una base de datos que utiliza Kubernetes para realizar una copia de seguridad de todos los datos del clúster. Almacena toda la configuración y el estado del clúster. El nodo maestro consulta etcd para recuperar parámetros para el estado de los nodos, pods y contenedores.
Controlador
El papel del Controlador es obtener el estado deseado del servidor API. Comprueba el estado actual de los nodos que tiene la tarea de controlar, determina si hay diferencias y las resuelve, si las hay.
Programador
Un programador observa las nuevas solicitudes provenientes del servidor API y las asigna a nodos saludables. Clasifica la calidad de los nodos e implementa pods en el nodo más adecuado. Si no hay nodos adecuados, los pods se ponen en estado pendiente hasta que aparece dicho nodo.
¿Qué es el nodo trabajador en la arquitectura de Kubernetes?
Los nodos de trabajo escuchan el servidor API para nuevas asignaciones de trabajo; ejecutan las asignaciones de trabajo y luego informan los resultados al nodo principal de Kubernetes.
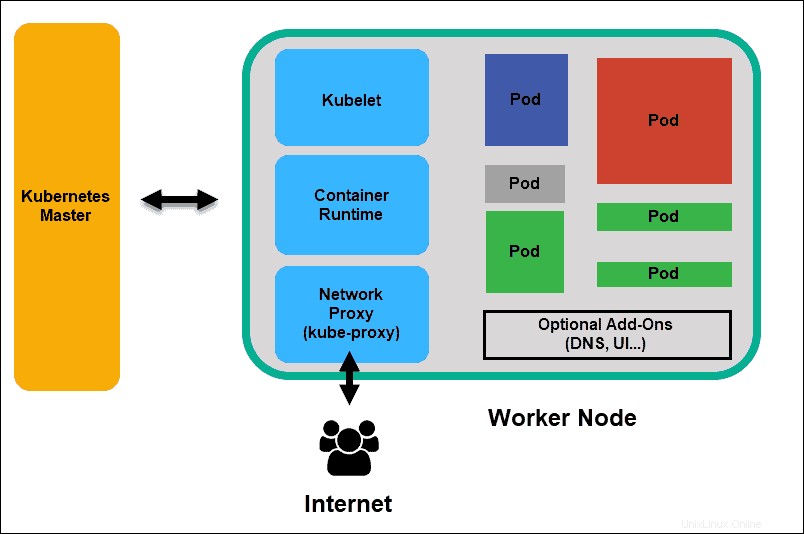
Nodo trabajador de Kubernetes
Cubelet
El kubelet se ejecuta en todos los nodos del clúster. Es el principal agente de Kubernetes. Al instalar kubelet, la CPU, la RAM y el almacenamiento del nodo pasan a formar parte del clúster más amplio. Observa las tareas enviadas desde el servidor API, ejecuta la tarea e informa al Maestro. También supervisa los pods e informa al panel de control si un pod no funciona completamente. Con base en esa información, el maestro puede decidir cómo asignar tareas y recursos para alcanzar el estado deseado.
Tiempo de ejecución del contenedor
El tiempo de ejecución del contenedor extrae imágenes de un registro de imágenes de contenedor y arranca y detiene contenedores. Un software o complemento de terceros, como Docker, generalmente realiza esta función.
Proxy Kube
El proxy kube se asegura de que cada nodo obtenga su dirección IP, implementa iptables locales y reglas para manejar el enrutamiento y el balanceo de carga de tráfico.
Cápsula
Una vaina es el elemento más pequeño de programación en Kubernetes. Sin él, un contenedor no puede ser parte de un clúster. Si necesita escalar su aplicación, solo puede hacerlo agregando o eliminando pods.
El pod sirve como un "envoltorio" para un solo contenedor con el código de la aplicación. En función de la disponibilidad de recursos, el maestro programa el pod en un nodo específico y se coordina con el tiempo de ejecución del contenedor para lanzar el contenedor.
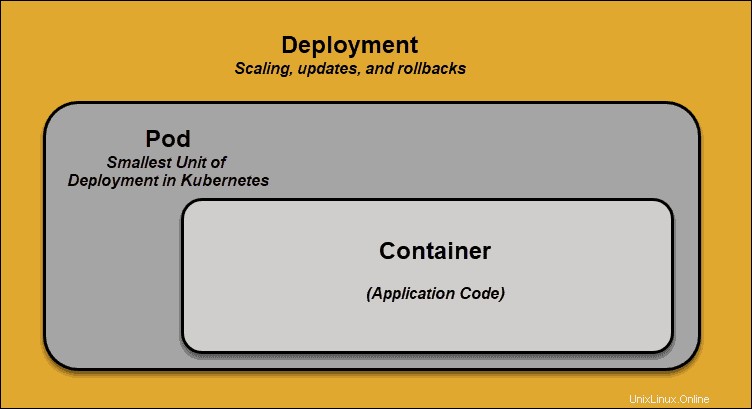
En los casos en que los pods no pueden realizar sus tareas de forma inesperada, Kubernetes no intenta solucionarlos. En su lugar, crea e inicia un nuevo pod en su lugar. Este nuevo pod es una réplica, excepto por el DNS y la dirección IP. Esta característica ha tenido un profundo impacto en la forma en que los desarrolladores diseñan aplicaciones.
Debido a la naturaleza flexible de la arquitectura de Kubernetes, las aplicaciones ya no necesitan estar vinculadas a una instancia particular de un pod. En su lugar, las aplicaciones deben diseñarse de modo que un módulo completamente nuevo, creado en cualquier lugar dentro del clúster, pueda ocupar su lugar sin problemas. Para ayudar con este proceso, Kubernetes utiliza servicios .
Servicios de Kubernetes
Las vainas no son constantes. Una de las mejores características que ofrece Kubernetes es que los pods que no funcionan se reemplazan automáticamente por otros nuevos.
Sin embargo, estos nuevos pods tienen un conjunto diferente de direcciones IP. Puede provocar problemas de procesamiento y la rotación de IP, ya que las IP ya no coinciden. Si no se atiende, esta propiedad haría que los pods fueran muy poco confiables.
Los servicios se introducen para proporcionar redes confiables al traer direcciones IP y nombres DNS estables al mundo inestable de los pods.
Al controlar el tráfico que entra y sale del módulo, un servicio de Kubernetes proporciona un punto final de red estable:una IP, un DNS y un puerto fijos. A través de un servicio, se puede agregar o eliminar cualquier pod sin temor a que la información básica de la red cambie de alguna manera.
¿Cómo funcionan los servicios de Kubernetes?
Los pods se asocian con servicios a través de pares clave-valor llamados etiquetas. y selectores . Un servicio descubre automáticamente un nuevo pod con etiquetas que coinciden con el selector.
Este proceso agrega sin problemas nuevos pods al servicio y, al mismo tiempo, elimina los pods terminados del clúster.
Por ejemplo, si el estado deseado incluye tres réplicas de un pod y un nodo que ejecuta una réplica falla , el estado actual se reduce a dos pods. Kubernetes observa que el estado deseado es tres pods. Luego programa una nueva réplica para tomar el lugar del pod fallido y lo asigna a otro nodo en el clúster.
Lo mismo se aplicaría al actualizar o escalar la aplicación agregando o eliminando pods. Una vez que actualizamos el estado deseado, Kubernetes nota la discrepancia y agrega o elimina pods para que coincidan con el archivo de manifiesto. El panel de control de Kubernetes registra, implementa y ejecuta bucles de reconciliación en segundo plano que verifican continuamente si el entorno cumple con los requisitos definidos por el usuario.
¿Qué es la implementación de contenedores?
Para comprender completamente cómo y qué organiza Kubernetes, debemos explorar el concepto de implementación de contenedores. .
Despliegue tradicional
Inicialmente, los desarrolladores implementaron aplicaciones en servidores físicos individuales. Este tipo de despliegue planteó varios desafíos. El uso compartido de recursos físicos significaba que una aplicación podía ocupar la mayor parte de la potencia de procesamiento, lo que limitaba el rendimiento de otras aplicaciones en la misma máquina.
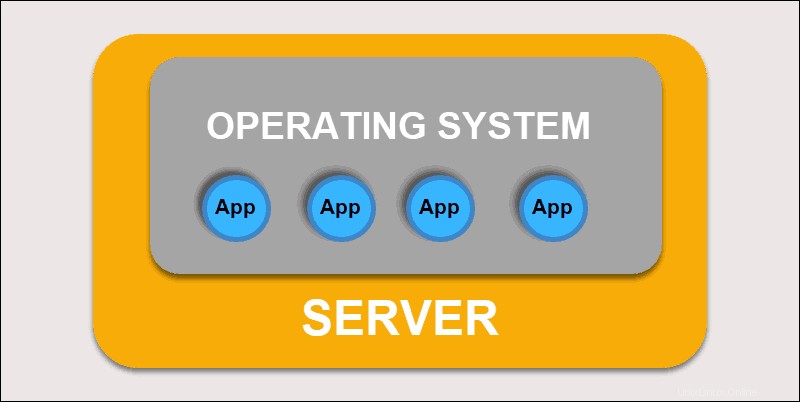
Despliegue tradicional
Lleva mucho tiempo expandir la capacidad del hardware, lo que a su vez aumenta los costos. Para resolver las limitaciones de hardware, las organizaciones comenzaron a virtualizar máquinas físicas.
Implementación virtualizada
La implementación virtualizada le permite crear entornos virtuales aislados, máquinas virtuales (VM) , en un único servidor físico. Esta solución aísla las aplicaciones dentro de una máquina virtual, limita el uso de recursos y aumenta la seguridad. Una aplicación ya no puede acceder libremente a la información procesada por otra aplicación.
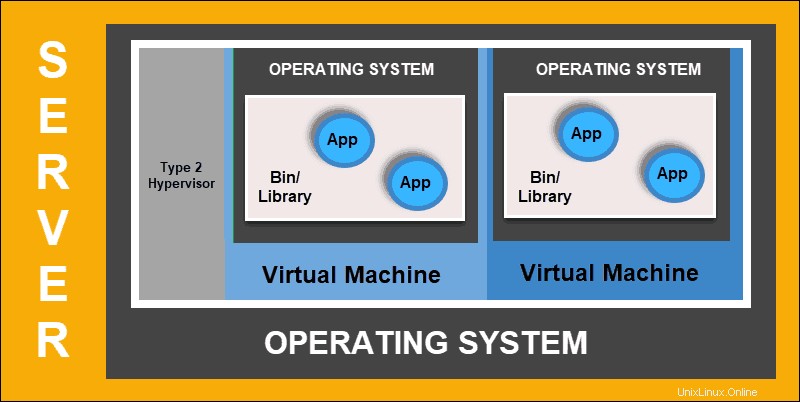
Implementación virtualizada
Las implementaciones virtualizadas le permiten escalar rápidamente y distribuir los recursos de un solo servidor físico, actualizar a voluntad y mantener los costos de hardware bajo control. Cada máquina virtual tiene su sistema operativo y puede ejecutar todos los sistemas necesarios sobre el hardware virtualizado.
Despliegue de contenedores
La implementación de contenedores es el siguiente paso en el camino para crear un modelo más flexible y eficiente. Al igual que las máquinas virtuales, los contenedores tienen memoria individual, archivos de sistema y espacio de procesamiento. Sin embargo, el aislamiento estricto ya no es un factor limitante.
Varias aplicaciones ahora pueden compartir el mismo sistema operativo subyacente. Esta característica hace que los contenedores sean mucho más eficientes que las máquinas virtuales completas. Son portátiles a través de nubes, diferentes dispositivos y casi cualquier distribución de sistema operativo.
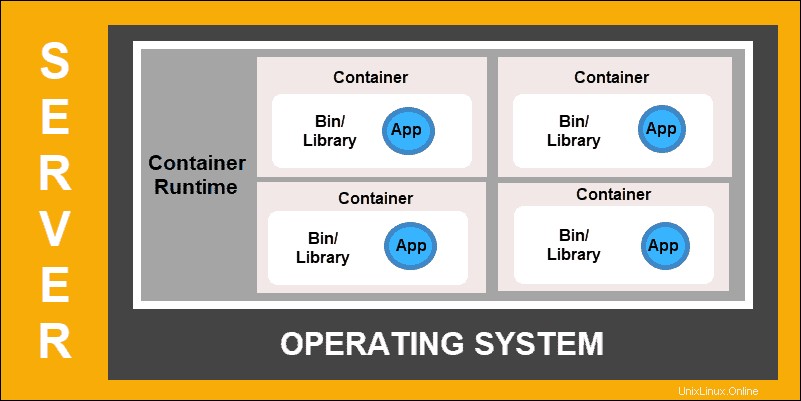
Despliegue de contenedores
La estructura del contenedor también permite que las aplicaciones se ejecuten como partes más pequeñas e independientes. Luego, estas partes se pueden implementar y administrar dinámicamente en varias máquinas. La estructura elaborada y la segmentación de tareas son demasiado complejas para gestionarlas manualmente.
Se requiere una solución de automatización, como Kubernetes, para administrar de manera efectiva todas las partes móviles involucradas en este proceso.