ELK stack también se conoce como Elastic stack y consta de cuatro proyectos de código abierto:Elasticsearch, Logstash, Kibana y Beats. Le ayuda a tener todos sus registros almacenados en un solo lugar y brinda la capacidad de analizar y visualizar datos o problemas al correlacionar los eventos en un momento determinado.
Esta guía lo ayuda a instalar la pila ELK en RHEL 8.
Elasticsearch:un motor de búsqueda de texto completo de código abierto. Almacena registros entrantes de Logstash y ofrece la posibilidad de buscar registros/datos en tiempo real
Logstash:realiza el procesamiento de datos (recopilar, enriquecer y transformar) de los registros entrantes enviados por beats (reenviador) y los envía a Elasticsearch
Kibana:proporciona visualización de datos o registros de Elasticsearch.
Beats:instalado en las máquinas cliente, recopila y envía registros a Logstash a través del protocolo beats.
Para tener una pila ELK con todas las funciones, necesitaríamos dos máquinas para probar la recopilación de registros.
| Nombre de host | SO | Dirección IP | Propósito |
|---|
| elk.itzgeek.local | RHEL 8 | 192.168.1.10 | Pila ELK |
| cliente.itzgeek.local | CentOS 7 | 192.168.1.20 | Máquina cliente (Filebeat) |
Requisitos
Instalar Java
Dado que Elasticsearch se basa en Java, debemos tener OpenJDK u Oracle JDK instalado en su máquina.
LEER: Cómo instalar Java en RHEL 8
Aquí, estoy usando OpenJDK 1.8.
yum -y install java
Verifique la versión de Java.
java -version
Salida:
openjdk version "1.8.0_212"
OpenJDK Runtime Environment (build 1.8.0_212-b04)
OpenJDK 64-Bit Server VM (build 25.212-b04, mixed mode)
Configurar repositorio ELK
Importe la clave de firma de Elastic.
rpm --import https://artifacts.elastic.co/GPG-KEY-elasticsearch
Configure el repositorio de Elasticsearch tanto en el servidor ELK como en el cliente.
cat << EOF > /etc/yum.repos.d/elastic.repo
[elasticsearch-7.x]
name=Elasticsearch repository for 7.x packages
baseurl=https://artifacts.elastic.co/packages/oss-7.x/yum
gpgcheck=1
gpgkey=https://artifacts.elastic.co/GPG-KEY-elasticsearch
enabled=1
autorefresh=1
type=rpm-md
EOF
Instalar y configurar Elasticsearch
Elasticsearch es un motor de búsqueda de texto completo de código abierto que ofrece análisis y búsqueda distribuida en tiempo real con la interfaz web RESTful. Elasticsearch almacena todos los datos enviados por Logstash y se muestran a través de la interfaz web (Kibana) a pedido de los usuarios.
Instala Elasticsearch.
yum install -y elasticsearch-oss
Edite el archivo de configuración de Elasticsearch para
vi /etc/elasticsearch/elasticsearch.yml
Establezca el nombre del clúster, el nombre del nodo y la dirección IP de escucha según su entorno.
cluster.name: elkstack
node.name: elk.itzgeek.local
network.host: 192.168.1.10
Si configura la dirección IP de escucha, debe definir los hosts iniciales y los nodos maestros iniciales.
discovery.seed_hosts: ["elk.itzgeek.local"]
cluster.initial_master_nodes: ["elk.itzgeek.local"]
Configure Elasticsearch para que se inicie durante el inicio del sistema.
systemctl daemon-reload
systemctl enable elasticsearch
systemctl start elasticsearch
Use CURL para verificar si Elasticsearch está respondiendo a las consultas.
curl -X GET http://192.168.1.10:9200
Salida:
{
"name" : "elk.itzgeek.local",
"cluster_name" : "elkstack",
"cluster_uuid" : "yws_6oYKS965bZ7GTh0e6g",
"version" : {
"number" : "7.2.0",
"build_flavor" : "oss",
"build_type" : "rpm",
"build_hash" : "508c38a",
"build_date" : "2019-06-20T15:54:18.811730Z",
"build_snapshot" : false,
"lucene_version" : "8.0.0",
"minimum_wire_compatibility_version" : "6.8.0",
"minimum_index_compatibility_version" : "6.0.0-beta1"
},
"tagline" : "You Know, for Search"
}
Verifique el estado del clúster ejecutando el siguiente comando.
curl -XGET '192.168.1.10:9200/_cluster/health?pretty'
Resultado:el estado del clúster debe ser verde.
{
"cluster_name" : "elkstack",
"status" : "green",
"timed_out" : false,
"number_of_nodes" : 1,
"number_of_data_nodes" : 1,
"active_primary_shards" : 0,
"active_shards" : 0,
"relocating_shards" : 0,
"initializing_shards" : 0,
"unassigned_shards" : 0,
"delayed_unassigned_shards" : 0,
"number_of_pending_tasks" : 0,
"number_of_in_flight_fetch" : 0,
"task_max_waiting_in_queue_millis" : 0,
"active_shards_percent_as_number" : 100.0
}
Instalar y configurar Logstash
Logstash es una herramienta de código abierto para administrar registros. Recopila los registros, los analiza y los almacena en Elasticsearch. Hay más de 160 complementos disponibles para Logstash, que ofrece la capacidad de procesar diferentes tipos de eventos sin trabajo adicional.
Instale el paquete Logstash.
yum -y install logstash-oss
La configuración de Logstash se puede encontrar en /etc/logstash/conf.d/ .
El archivo de configuración de Logstash consta de tres secciones:entrada, filtro y salida. Las tres secciones se pueden encontrar en un solo archivo o en archivos separados que terminan en .conf.
Le recomiendo que use un solo archivo para colocar las secciones de entrada, filtro y salida.
vi /etc/logstash/conf.d/beats.conf
En la sección de entrada, configuraremos Logstash para escuchar en el puerto 5044 los registros entrantes de los beats (reenviador) que está instalado en las máquinas cliente.
input {
beats {
port => 5044
}
}
En la sección de filtros, usaremos Grok para analizar los registros antes de enviarlos a Elasticsearch.
El siguiente filtro grok buscará el syslog registros etiquetados e intenta analizarlos para crear un índice estructurado. Este filtro es bastante útil solo para monitorear los mensajes de syslog (/var/log/messages).
filter {
if [type] == "syslog" {
grok {
match => { "message" => "%{SYSLOGLINE}" }
}
date {
match => [ "timestamp", "MMM d HH:mm:ss", "MMM dd HH:mm:ss" ]
}
}
}
Para obtener más patrones de filtro, visite la página de grokdebugger.
En la sección de salida, definiremos la ubicación donde se almacenarán los registros, obviamente, un nodo de Elasticsearch.
output {
elasticsearch {
hosts => ["192.168.1.10:9200"]
index => "%{[@metadata][beat]}-%{+YYYY.MM.dd}"
}
}
Ahora inicie y habilite el servicio Logstash.
systemctl start logstash
systemctl enable logstash
Espere un minuto para permitir que Logstash se inicie y luego ejecute el siguiente comando para verificar si está escuchando en el puerto 5044.
netstat -antup | grep -i 5044
Salida:
tcp6 0 0 :::5044 :::* LISTEN 31014/java
Puede solucionar los problemas de Logstash con la ayuda de los registros.
cat /var/log/logstash/logstash-plain.log
Instalar y configurar Kibana
Kibana proporciona visualización de registros almacenados en Elasticsearch. Instale Kibana usando el siguiente comando.
yum -y install kibana-oss
Edite el archivo kibana.yml.
vi /etc/kibana/kibana.yml
De forma predeterminada, Kibana escucha en localhost, lo que significa que no puede acceder a Kibana desde máquinas externas. Para permitirlo, edite la siguiente línea y mencione la IP de su servidor ELK.
server.host: "0.0.0.0"
Quite el comentario de la siguiente línea y actualícela con la URL de la instancia de Elasticsearch.
elasticsearch.hosts: ["http://192.168.1.10:9200"]
Inicie y habilite kibana al iniciar el sistema.
systemctl start kibana
systemctl enable kibana
Compruebe si Kibana está escuchando en el puerto 5601.
netstat -antup | grep -i 5601
Salida:
tcp 0 0 0.0.0.0:5601 0.0.0.0:* LISTEN 3631/node
Cortafuegos
Configure un firewall en el servidor ELK para recibir los registros de las máquinas cliente.
5044 – Para que Logstash reciba los registros
5061 – Para acceder a Kibana desde máquinas externas.
firewall-cmd --permanent --add-port=5044/tcp
firewall-cmd --permanent --add-port=5601/tcp
firewall-cmd --reload
A continuación, configuraremos beats para enviar los registros al servidor de Logstash.
Instalar y configurar Filebeat
Hay cuatro beats disponibles
- Packetbeat – Analizar datos de paquetes de red.
- Filebeat – Información en tiempo real sobre los datos de registro.
- Mejores ritmos – Obtenga información de los datos de la infraestructura.
- Metricbeat – Enviar métricas a Elasticsearch.
Configure el repositorio de Elastic en la máquina cliente para obtener el paquete Filebeat.
Instale Filebeat usando el siguiente comando.
yum -y install filebeat
El archivo de configuración de Filebeat está en formato YAML, lo que significa que la sangría es muy importante. Asegúrese de utilizar la misma cantidad de espacios utilizados en la guía.
Edite el archivo de configuración de filebeat.
vi /etc/filebeat/filebeat.yml
Comente la sección output.elasticsearch: ya que no vamos a almacenar registros directamente en Elasticsearch.
#-------------------------- Elasticsearch output ------------------------------
#output.elasticsearch:
# Array of hosts to connect to.
#hosts: ["localhost:9200"]
# Optional protocol and basic auth credentials.
#protocol: "https"
#username: "elastic"
#password: "changeme"
Ahora, busque la línea output.logstash y modifique las entradas como a continuación. Esta sección define filebeat para enviar registros al servidor de Logstash 192.168.1.10 en el puerto 5044 .
. . .
#----------------------------- Logstash output --------------------------------
output.logstash:
# The Logstash hosts
hosts: ["192.168.1.10:5044"]
. . .
Sobre /etc/filebeat/filebeat.yml , vería la sección de prospectores. Aquí, debe especificar qué registros deben enviarse a Logstash.
Cada prospector comienza con un – personaje.
Aquí, configuraremos filebeat para enviar registros del sistema /var/log/messages al servidor de Logstash. Para ello, modifique el prospector existente en rutas sección como se muestra a continuación.
. . .
filebeat.inputs:
# Each - is an input. Most options can be set at the input level, so
# you can use different inputs for various configurations.
# Below are the input specific configurations.
- type: log
# Change to true to enable this input configuration.
enabled: true
# Paths that should be crawled and fetched. Glob based paths.
paths:
- /var/log/messages
#- c:\programdata\elasticsearch\logs\*
. . .
Reinicie el servicio.
systemctl restart filebeat
systemctl enable filebeat
Acceder a Kibana
Acceda a Kibana utilizando la siguiente URL.
http://su-dirección-ip-ess:5601/
Obtendrías la página de inicio de Kibana. Haz clic en Explorar por mi cuenta .

En su primer acceso, debe mapear el índice de filebeat. Ir a Administración>> Patrones de índice>> Crear patrón de índice .
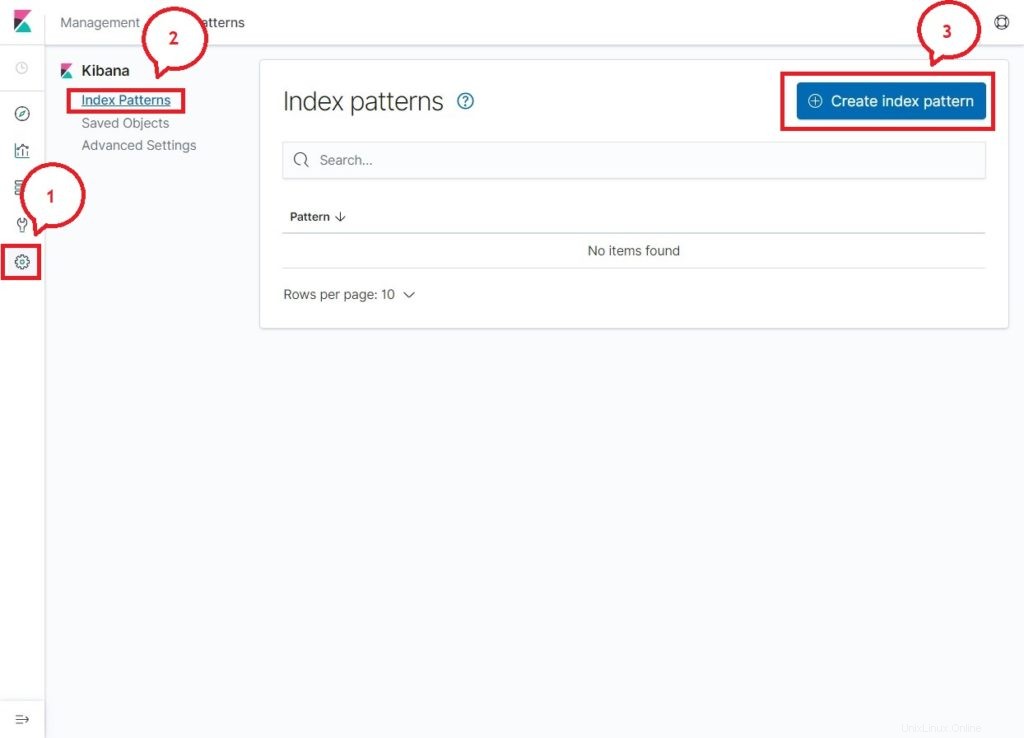
Escriba lo siguiente en el Patrón de índice caja.
filebeat-*
Debería ver al menos un índice de latido de archivo similar al siguiente. Haz clic en Siguiente paso . 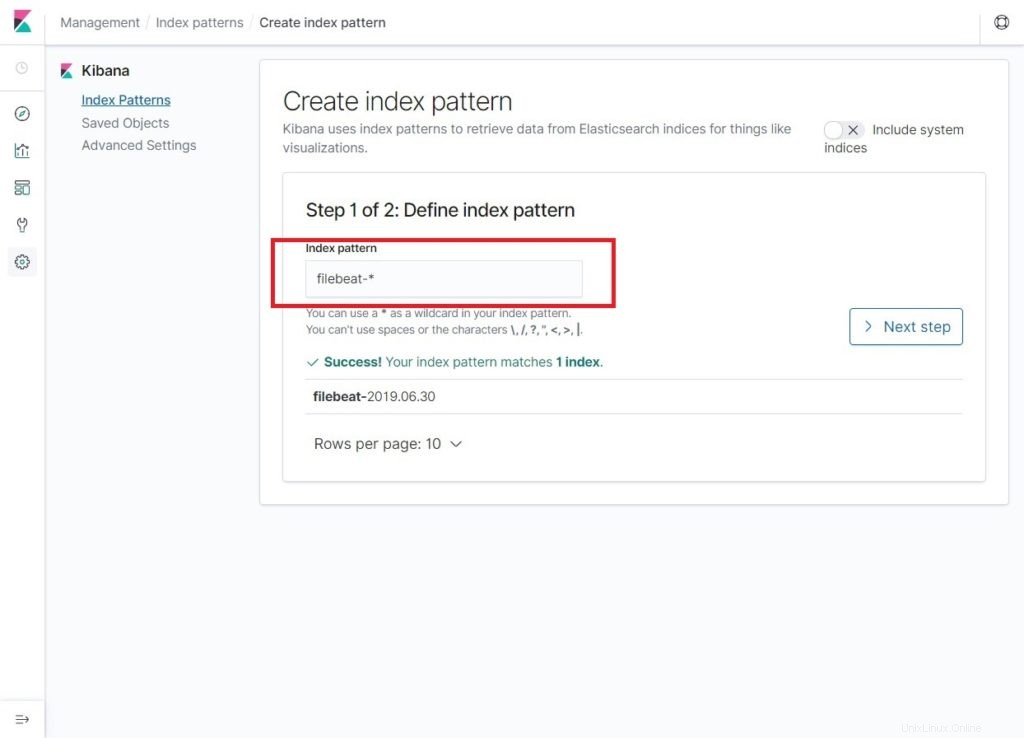
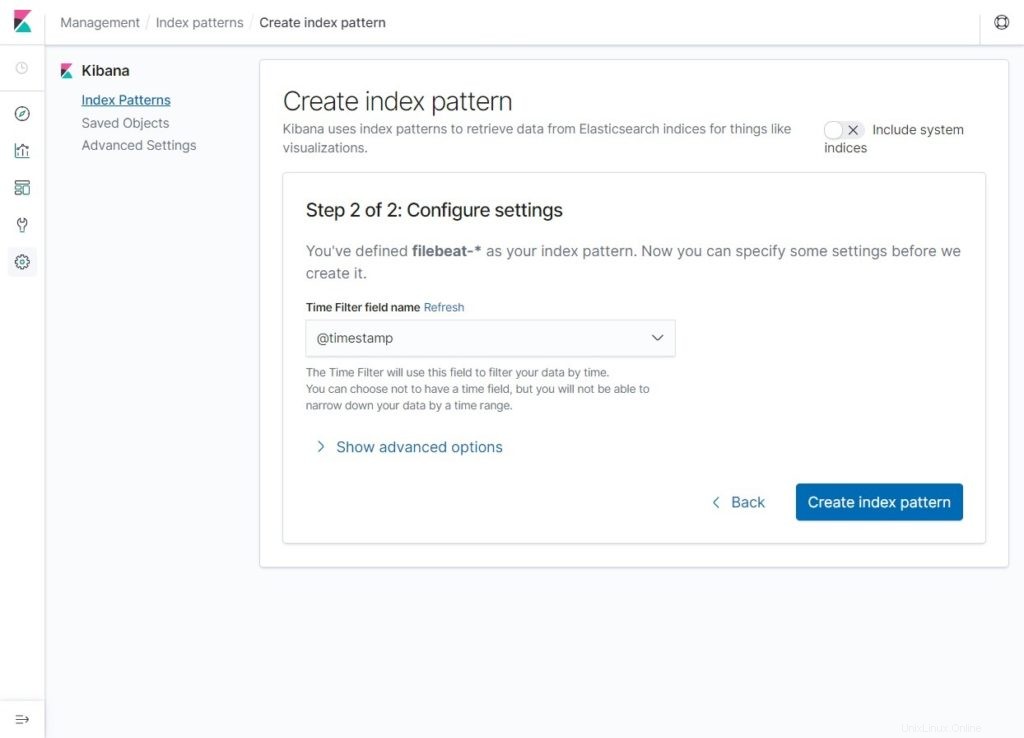
Seleccione @timestamp y luego haga clic en Crear patrón de índice .
@timestamp
Verifique sus patrones de índice y sus asignaciones.
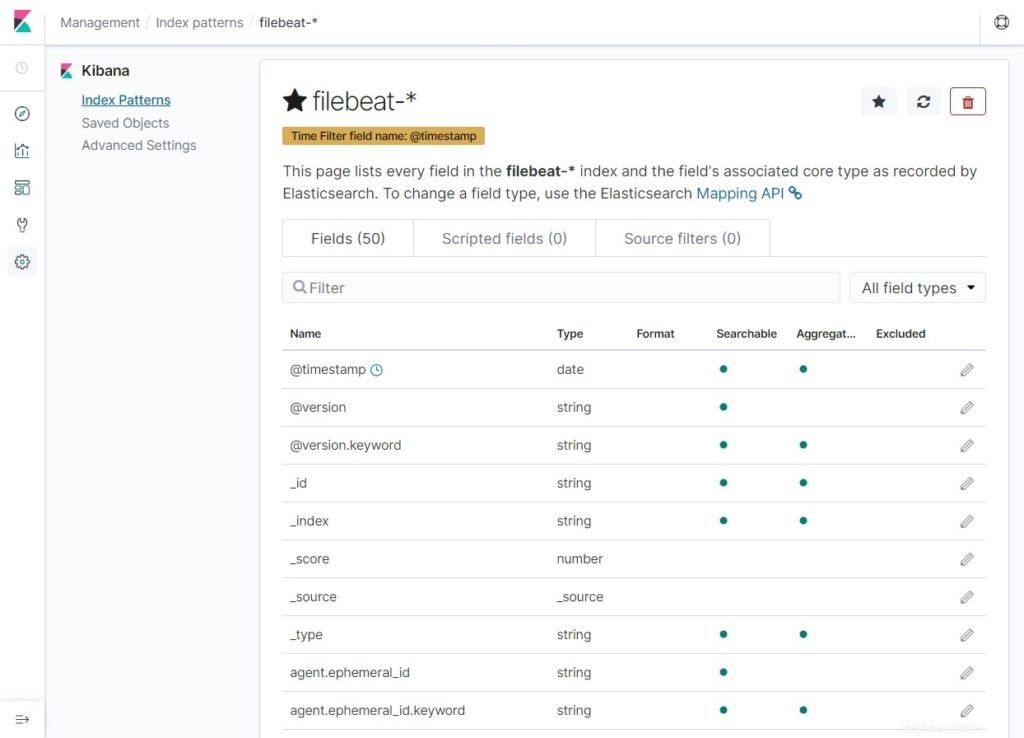
Ahora, haz clic en Descubrir para ver los registros y realizar consultas de búsqueda.
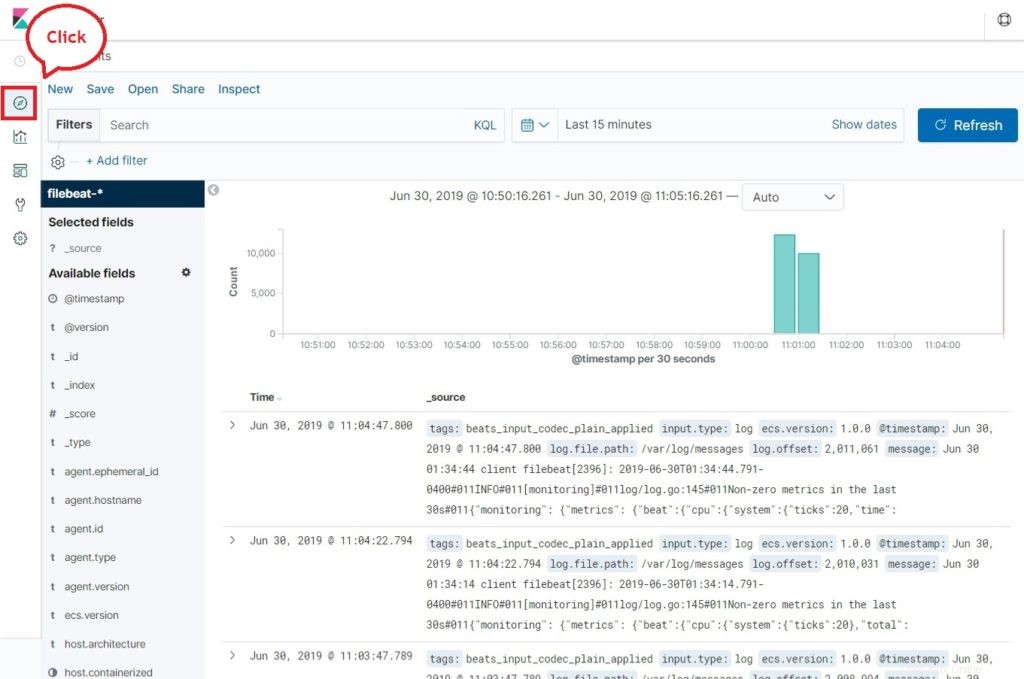
Conclusión
Eso es todo. Ha aprendido con éxito cómo instalar ELK Stack en RHEL 8. Comparta sus comentarios en la sección de comentarios.