Búsqueda elástica es un motor de análisis y búsqueda de texto completo de código abierto altamente escalable . Por lo general, es el motor o la tecnología subyacente el que impulsa las aplicaciones con características y requisitos de búsqueda complejos. El software admite operaciones RESTful que le permiten almacenar, buscar y analizar volúmenes significativos de datos rápidamente y casi en tiempo real. Elasticsearch es apreciado y popular entre los administradores de sistemas y los desarrolladores, ya que es un potente motor de búsqueda basado en la biblioteca de Lucene.
En el siguiente tutorial, aprenderá a cómo instalar Elastic Search en openSUSE Leap 15 .
Requisitos
- SO recomendado: salto de openSUSE – 15.x
- Cuenta de usuario: Una cuenta de usuario con sudo o acceso root.
Actualizar Sistema Operativo
Actualice su openSUSE sistema operativo para asegurarse de que todos los paquetes existentes estén actualizados:
sudo zypper refreshEl tutorial usará el comando sudo y asumiendo que tiene estado sudo .
Para verificar el estado de sudo en su cuenta:
sudo whoamiEjemplo de salida que muestra el estado de sudo:
[joshua@opensuse ~]$ sudo whoami
rootPara configurar una cuenta Sudo existente o nueva, visite nuestro tutorial sobre agregar un usuario a Sudoers en openSUSE .
Para usar la cuenta raíz , use el siguiente comando con la contraseña de root para iniciar sesión.
suInstalar paquete CURL
El CURL Se necesita el comando para algunas partes de esta guía. Para instalar este paquete, escriba el siguiente comando:
sudo zyper install curlInstalar paquete Java
Para instalar correctamente y, lo que es más importante, utilizar Elasticsearch , necesitas instalar Java . El proceso es relativamente fácil.
Escriba el siguiente comando para instalar OpenJDK paquete:
sudo zypper install java-11-openjdk-develInstalar Elasticsearch
Elasticsearch no está disponible en el repositorio estándar de openSUSE , por lo que debe instalarlo desde el repositorio de Elasticsearch .
Antes de agregar el repositorio, importa la clave GPG con el siguiente comando:
sudo rpm --import https://artifacts.elastic.co/GPG-KEY-elasticsearchEl siguiente paso es crear un archivo de repositorio de Elasticsearch de la siguiente manera:
sudo zypper ar https://artifacts.elastic.co/packages/7.x/yum elasticsearchAhora instale Elasticsearch usando el siguiente comando:
sudo zypper install elasticsearchEjemplo de salida:
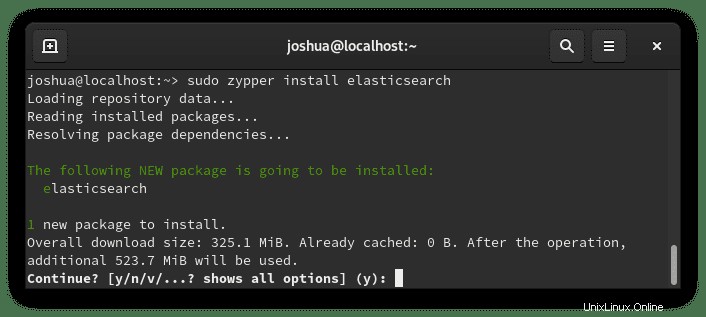
Escribe “Y,” luego presione la “TECLA ENTER” para continuar con la instalación
Para habilitar Elasticsearch de forma predeterminada, deberá instalar paquete insserv .
sudo zypper install insservDe manera predeterminada, el servicio de Elasticsearch está deshabilitado en el arranque y no está activo. Para iniciar el servicio y habilitarlo en el arranque del sistema, escriba lo siguiente (systemctl) comando:
sudo systemctl enable elasticsearch.service --nowEjemplo de salida:
Synchronizing state of elasticsearch.service with SysV service script with /usr/lib/systemd/systemd-sysv-install.
Executing: /usr/lib/systemd/systemd-sysv-install enable elasticsearchVerifique que Elasticsearch se esté ejecutando correctamente usando el comando curl para enviar una solicitud HTTP al puerto 9200 en localhost de la siguiente manera:
sudo curl http://localhost:9200?prettyEjemplo de salida:
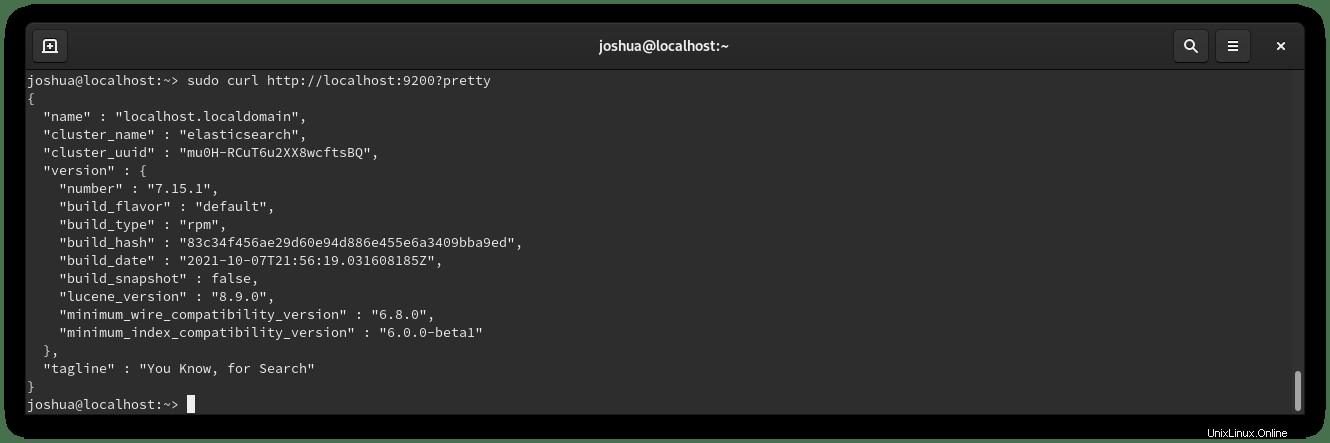
Cómo configurar Elasticsearch
Los datos de Elasticsearch se almacenan en la ubicación del directorio predeterminado (/var/lib/elasticsearch) . Para ver o editar los archivos de configuración, puede encontrarlos en la ubicación del directorio (/etc/elasticsearch) y las opciones de inicio de Java se pueden configurar en (/etc/default/elasticsearch) archivo de configuración.
La configuración predeterminada está bien principalmente para servidores operativos únicos, ya que Elasticsearch se ejecuta en localhost solamente. Sin embargo, si va a configurar un clúster, deberá modificar el archivo de configuración para permitir conexiones remotas.
Configurar el acceso remoto (opcional)
De forma predeterminada, Elasticsearch solo escucha localhost. Para cambiar esto, abra el archivo de configuración de la siguiente manera:
sudo nano /etc/elasticsearch/elasticsearch.ymlDesplácese hacia abajo hasta la línea 56 y busca la sección Red y elimina el comentario (#) la siguiente línea y reemplácela con la dirección IP privada interna o la dirección IP externa de la siguiente manera:
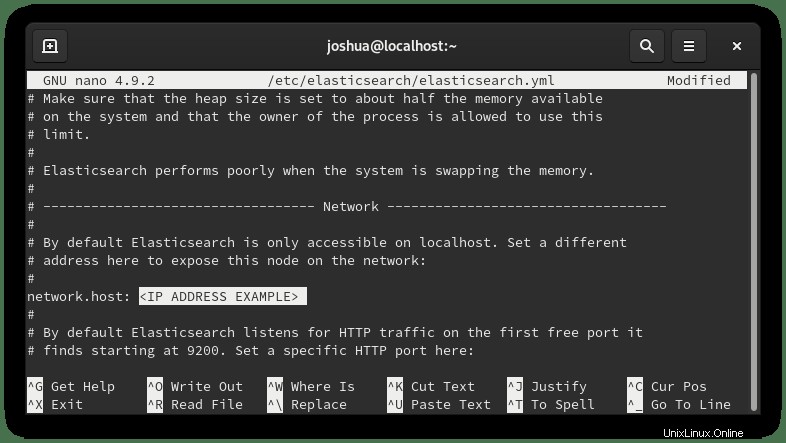
En el ejemplo, descomentamos (#) el (red.host) y la cambió a una dirección IP privada interna como se indica arriba.
Por motivos de seguridad, es ideal para especificar direcciones; sin embargo, si tiene varias direcciones IP internas o externas que acceden al servidor, cambie la interfaz de red para escuchar todas ingresando (0.0.0.0) de la siguiente manera:
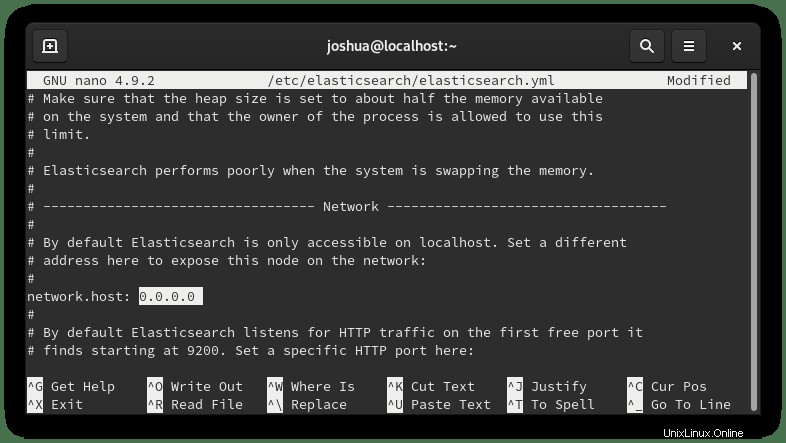
Guarde el archivo de configuración (CTRL+O), luego salga (CLTR+X) .
Deberá reiniciar el servicio Elasticsearch con el siguiente comando para que los cambios surtan efecto:
sudo systemctl restart elasticsearchConfigurar Firewalld para Elasticsearch
De manera predeterminada, no se configuran reglas para Elasticsearch, lo que puede causar problemas en el futuro.
Primero, agregue una nueva zona dedicada para la política de firewalld de Elasticsearch:
sudo firewall-cmd --permanent --new-zone=elasticsearchA continuación, especifique las direcciones IP permitidas que pueden acceder a Memcached.
sudo firewall-cmd --permanent --zone=elasticsearch --add-source=1.2.3.4Reemplace 1.2.3.4 con la IP dirección que se agregará a la lista de permitidos.
Una vez que haya terminado de agregar las direcciones IP, abra el puerto de Memcached.
Por ejemplo, puerto TCP 11211 .
sudo firewall-cmd --permanent --zone=elasticsearch --add-port=9200/tcpTenga en cuenta que puede cambiar el puerto predeterminado en su archivo de configuración si cambia la regla de apertura del puerto del cortafuegos anterior al nuevo valor.
Después de ejecutar esos comandos, vuelva a cargar el firewall para implementar las nuevas reglas:
sudo firewall-cmd --reloadEjemplo de salida si tiene éxito:
successCómo usar Elasticsearch
Para usar Elasticsearch usando el comando curl es un proceso sencillo. A continuación se muestran algunos de los más utilizados:
Borrar índice
Debajo del índice se denomina muestras .
curl -X DELETE 'http://localhost:9200/samples'Lista de todos los índices
curl -X GET 'http://localhost:9200/_cat/indices?v'Lista de todos los documentos en el índice
curl -X GET 'http://localhost:9200/sample/_search'Consulta usando parámetros de URL
Aquí usamos el formato de consulta de Lucene para escribir q=escuela:Harvard.
curl -X GET http://localhost:9200/samples/_search?q=school:HarvardConsulta con JSON, también conocido como Elasticsearch Query DSL
Puede consultar usando parámetros en la URL. Pero también puede usar JSON, como se muestra en el siguiente ejemplo. JSON sería más fácil de leer y depurar cuando tiene una consulta compleja que una cadena gigante de parámetros de URL.
curl -XGET --header 'Content-Type: application/json' http://localhost:9200/samples/_search -d '{
"query" : {
"match" : { "school": "Harvard" }
}
}'Asignación de índice de lista
Todos los campos de Elasticsearch son índices. Esto enumera todos los campos y sus tipos en un índice.
curl -X GET http://localhost:9200/samplesAñadir datos
curl -XPUT --header 'Content-Type: application/json' http://localhost:9200/samples/_doc/1 -d '{
"school" : "Harvard"
}'Actualizar documento
Aquí se explica cómo agregar campos a un documento existente. Primero, creamos uno nuevo. Luego lo actualizamos.
curl -XPUT --header 'Content-Type: application/json' http://localhost:9200/samples/_doc/2 -d '
{
"school": "Clemson"
}'
curl -XPOST --header 'Content-Type: application/json' http://localhost:9200/samples/_doc/2/_update -d '{
"doc" : {
"students": 50000}
}'Índice de copia de seguridad
curl -XPOST --header 'Content-Type: application/json' http://localhost:9200/_reindex -d '{
"source": {
"index": "samples"
},
"dest": {
"index": "samples_backup"
}
}'
Carga masiva de datos en formato JSON
export pwd="elastic:"
curl --user $pwd -H 'Content-Type: application/x-ndjson' -XPOST 'https://58571402f5464923883e7be42a037917.eu-central-1.aws.cloud.es.io:9243/0/_bulk?pretty' --data-binary @<file>Mostrar estado del clúster
curl --user $pwd -H 'Content-Type: application/json' -XGET https://58571402f5464923883e7be42a037917.eu-central-1.aws.cloud.es.io:9243/_cluster/health?prettyAgregación y Agregación de cubos
Para un servidor web Nginx, esto produce recuentos de visitas web por ciudad de usuario:
curl -XGET --user $pwd --header 'Content-Type: application/json' https://58571402f5464923883e7be42a037917.eu-central-1.aws.cloud.es.io:9243/logstash/_search?pretty -d '{
"aggs": {
"cityName": {
"terms": {
"field": "geoip.city_name.keyword",
"size": 50
}
}
}
}
'Esto lo amplía al número de códigos de respuesta del producto de la ciudad en un registro del servidor web Nginx
curl -XGET --user $pwd --header 'Content-Type: application/json' https://58571402f5464923883e7be42a037917.eu-central-1.aws.cloud.es.io:9243/logstash/_search?pretty -d '{
"aggs": {
"city": {
"terms": {
"field": "geoip.city_name.keyword"
},
"aggs": {
"responses": {
"terms": {
"field": "response"
}
}
}
},
"responses": {
"terms": {
"field": "response"
}
}
}
}'Uso de ElasticSearch con autenticación básica
Si ha activado la seguridad con ElasticSearch, debe proporcionar el usuario y la contraseña como se muestra a continuación para cada comando curl:
curl -X GET 'http://localhost:9200/_cat/indices?v' -u elastic:(password)Impresión bonita
Agregue ?pretty=true a cualquier búsqueda para imprimir bastante el JSON. Así:
curl -X GET 'http://localhost:9200/(index)/_search'?pretty=truePara consultar y devolver solo ciertos campos
Para devolver solo ciertos campos, colóquelos en la matriz _source:
GET filebeat-7.6.2-2020.05.05-000001/_search
{
"_source": ["suricata.eve.timestamp","source.geo.region_name","event.created"],
"query": {
"match" : { "source.geo.country_iso_code": "GR" }
}
}Para consultar por fecha
Cuando el campo es de tipo fecha, puede usar matemáticas de fecha, así:
GET filebeat-7.6.2-2020.05.05-000001/_search
{
"query": {
"range" : {
"event.created": {
"gte" : "now-7d/d"
}
}
}
}Cómo quitar (desinstalar) Elasticsearch
Si ya no necesita Elasticsearch, puede eliminar el software con el siguiente comando:
sudo zypper remove elasticsearchEjemplo de salida:
Escribe “Y,” luego presione la “TECLA ENTER” para continuar con la eliminación de Elasticsearch.