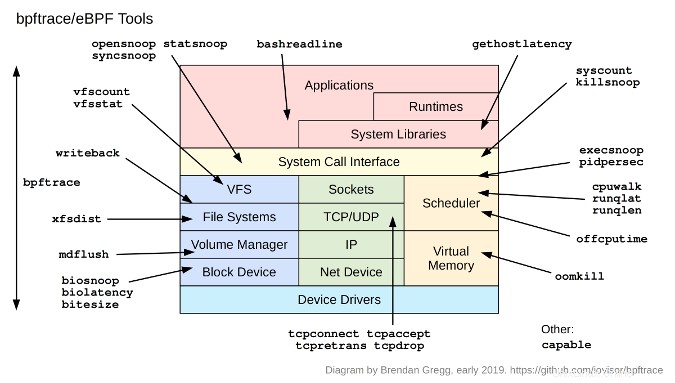
Bpftrace es un nuevo rastreador de código abierto para Linux para analizar problemas de rendimiento de producción y software de solución de problemas. Sus usuarios y colaboradores incluyen Netflix, Facebook, Red Hat, Shopify y otros, y fue creado por Alastair Robertson, un talentoso desarrollador con sede en el Reino Unido que ganó varios concursos de codificación.
Linux ya tiene muchas herramientas de rendimiento, pero a menudo se basan en contadores y tienen una visibilidad limitada. Por ejemplo, iostat(1) o un agente de monitoreo pueden indicarle la latencia de disco promedio, pero no la distribución de esta latencia. Las distribuciones pueden revelar múltiples modos o valores atípicos, cualquiera de los cuales puede ser la causa real de sus problemas de rendimiento. Bpftrace es adecuado para este tipo de análisis:descomposición de métricas en distribuciones o registros por evento y creación de nuevas métricas para la visibilidad de puntos ciegos.
Puede usar bpftrace a través de frases ingeniosas o scripts, y viene con muchas herramientas preescritas. Aquí hay un ejemplo que rastrea la distribución de la latencia de lectura para PID 181 y lo muestra como un histograma de potencia de dos:
# bpftrace -e 'kprobe:vfs_read /pid == 30153/ { @start[tid] = nsecs; }
kretprobe:vfs_read /@start[tid]/ { @ns = hist(nsecs - @start[tid]); delete(@start[tid]); }'
Attaching 2 probes...
^C
@ns:
[256, 512) 10900 |@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@ |
[512, 1k) 18291 |@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@|
[1k, 2k) 4998 |@@@@@@@@@@@@@@ |
[2k, 4k) 57 | |
[4k, 8k) 117 | |
[8k, 16k) 48 | |
[16k, 32k) 109 | |
[32k, 64k) 3 | | Este ejemplo instrumenta un evento de miles disponibles. Si tiene algún problema de rendimiento extraño, probablemente haya alguna frase de bpftrace que pueda aclararlo. Para entornos grandes, esta capacidad puede ayudarlo a ahorrar millones. Para entornos más pequeños, puede ser más útil para ayudar a eliminar los valores atípicos de latencia.
La terminal de Linux
- Los 7 mejores emuladores de terminal para Linux
- 10 herramientas de línea de comandos para el análisis de datos en Linux
- Descargar ahora:hoja de referencia de SSH
- Hoja de trucos de comandos avanzados de Linux
- Tutoriales de línea de comandos de Linux
Anteriormente escribí sobre bpftrace frente a otros rastreadores, incluido BCC (BPF Compiler Collection). BCC es ideal para herramientas y agentes complejos enlatados. Bpftrace es mejor para guiones breves e investigaciones ad hoc. En este artículo, resumiré el lenguaje bpftrace, los tipos de variables, las sondas y las herramientas.
Bpftrace utiliza BPF (Berkeley Packet Filter), un motor de ejecución en el kernel que procesa un conjunto de instrucciones virtuales. BPF se ha ampliado (también conocido como eBPF) en los últimos años para proporcionar una forma segura de ampliar la funcionalidad del núcleo. También se ha convertido en un tema candente en la ingeniería de sistemas, con al menos 24 charlas sobre BPF en la última Linux Plumber's Conference. BPF está en el kernel de Linux y bpftrace es la mejor manera de comenzar a usar BPF para la observabilidad.
Consulte la guía de INSTALACIÓN de bpftrace para saber cómo instalarlo y obtener la última versión; 0.9.2 acaba de ser lanzado. Para los clústeres de Kubernetes, también existe kubectl-trace para ejecutarlo.
Sintaxis
probe[,probe,...] /filter/ { action }La sonda especifica qué eventos instrumentar. El filtro es opcional y puede filtrar los eventos en función de una expresión booleana, y la acción es el miniprograma que se ejecuta.
Aquí está hola mundo:
# bpftrace -e 'BEGIN { printf("Hello eBPF!\n"); }'La sonda es BEGIN , una sonda especial que se ejecuta al principio del programa (como awk). No hay filtro. La acción es un printf() declaración.
Ahora un ejemplo real:
# bpftrace -e 'kretprobe:sys_read /pid == 181/ { @bytes = hist(retval); }'Esto utiliza un kretprobe para instrumentar el retorno de sys_read() función del núcleo. Si el PID es 181, una variable de mapa especial @bytes se rellena con una función de histograma log2 con el valor de retorno retval de sys_read() . Esto produce un histograma del tamaño de lectura devuelto para PID 181. ¿Su aplicación está haciendo muchas lecturas de un byte? Tal vez eso se pueda optimizar.
Tipos de sonda
Estas son bibliotecas de sondas relacionadas. Los tipos admitidos actualmente son (se agregarán más):
| Tipo | Descripción |
|---|---|
| punto de seguimiento | Puntos de instrumentación estática del kernel |
| usdt | Seguimiento definido estáticamente a nivel de usuario |
| kprobe | Instrumentación de funciones dinámicas del kernel |
| kretprobe | Instrumentación de devolución de funciones dinámicas del kernel |
| sondeo | Instrumentación de funciones dinámicas a nivel de usuario |
| uretprobe | Instrumentación de retorno de funciones dinámicas a nivel de usuario |
| software | Eventos basados en software del kernel |
| hardware | Instrumentación basada en contador de hardware |
| punto de vigilancia | Eventos de punto de observación de memoria (en desarrollo) |
| perfil | Muestreo temporizado en todas las CPU |
| intervalo | Informes cronometrados (desde una CPU) |
| COMENZAR | Inicio de bpftrace |
| FIN | Fin de bpftrace |
| Variable | Descripción |
|---|---|
| @nombre | globales |
| @nombre[clave] | hash |
| @nombre[tid] | subproceso local |
| $nombre | rasguño |
| Variable | Descripción |
|---|---|
| pid | identificación del proceso |
| comunicación | Nombre de proceso o comando |
| nsegs | Hora actual en nanosegundos |
| kstack | Seguimiento de la pila del kernel |
| ustack | Seguimiento de pila a nivel de usuario |
| arg0...argN | Argumentos de función |
| argumentos | Argumentos de punto de seguimiento |
| recuperación | Valor de retorno de la función |
| nombre | Nombre completo de la sonda |
| Función | Descripción |
|---|---|
| printf("...") | Imprimir cadena con formato |
| hora("...") | Imprimir hora formateada |
| sistema("...") | Ejecutar comando de shell |
| @ =cuenta() | Contar eventos |
| @ =hist(x) | Histograma potencia de 2 para x |
| @ =lhist(x, min, max, paso) | Histograma lineal para x |
| Lista de sondas | bpftrace -l 'tracepoint:syscalls:sys_enter_*' |
| Hola mundo | bpftrace -e 'COMENZAR { printf("hola mundo\n") }' |
| El archivo se abre | bpftrace -e 'tracepoint:syscalls:sys_enter_open { printf("%s %s\n", comm, str(args->nombre de archivo)) }' |
| Recuentos de Syscall por proceso | bpftrace -e 'tracepoint:raw_syscalls:sys_enter { @[comm] =cuenta() }' |
| Distribución de bytes de lectura() | bpftrace -e 'tracepoint:syscalls:sys_exit_read /pid ==18644/ { @bytes =hist(args->retval) }' |
| Rastreo dinámico del kernel de bytes read() | bpftrace -e 'kretprobe:vfs_read { @bytes =lhist(retval, 0, 2000, 200) }' |
| Tiempos de lectura() | bpftrace -e 'kprobe:vfs_read { @start[tid] =nsecs } kretprobe:vfs_read /@start[tid]/ { @ns[comm] =hist(nsecs - @start[tid]); eliminar(@start[tid]) }' |
| Contar eventos a nivel de proceso | bpftrace -e 'tracepoint:sched:sched* { @[nombre] =cuenta() } intervalo:s:5 { salida() }' |
| Perfil de pilas de kernel en la CPU | bpftrace -e 'perfil:hz:99 { @[pila] =cuenta() }' |
| Seguimiento del programador | bpftrace -e 'tracepoint:sched:sched_switch { @[pila] =cuenta() }' |
| Bloquear E/S | bpftrace -e 'tracepoint:block:block_rq_issue { @ =hist(args->bytes); } |
| Seguimiento de la estructura del kernel (un script, no una sola línea) | Comando: bpftrace path.bt , donde el archivo path.bt es: #include #include kprobe:vfs_open { printf("abrir ruta:%s\n", str(((ruta *)arg0)->entry->d_name .nombre)); } |