Este artículo es un extracto del capítulo 13 del libro Linux en acción, publicado por Manning.
¿El rendimiento de su máquina Linux ha sido errático o inusualmente lento? ¿Sospecha que la creciente demanda podría estar superando sus recursos disponibles? Aquí hay algunas preguntas que deberías hacerte:
- ¿Qué tan cerca está de agotar sus recursos de CPU y memoria?
- ¿Hay algo funcionando innecesariamente que podría cerrarse?
- ¿Hay algo que se ha estado ejecutando sin su conocimiento?
Más recursos de Linux
- Hoja de trucos de los comandos de Linux
- Hoja de trucos de comandos avanzados de Linux
- Curso en línea gratuito:Descripción general técnica de RHEL
- Hoja de trucos de red de Linux
- Hoja de trucos de SELinux
- Hoja de trucos de los comandos comunes de Linux
- ¿Qué son los contenedores de Linux?
- Nuestros últimos artículos sobre Linux
¿Dónde debe buscar respuestas? La parte superior programa es un gran lugar para comenzar. Puede brindarle una visión general rica y autoactualizada de los procesos que se ejecutan en su sistema.
La siguiente figura muestra una pantalla típica de top datos. La primera línea proporciona la hora actual, el tiempo transcurrido desde el inicio del sistema más reciente, la cantidad de usuarios conectados actualmente y los promedios de carga para el último minuto, cinco minutos y 15 minutos. Esta información también se puede devolver ejecutando uptime .
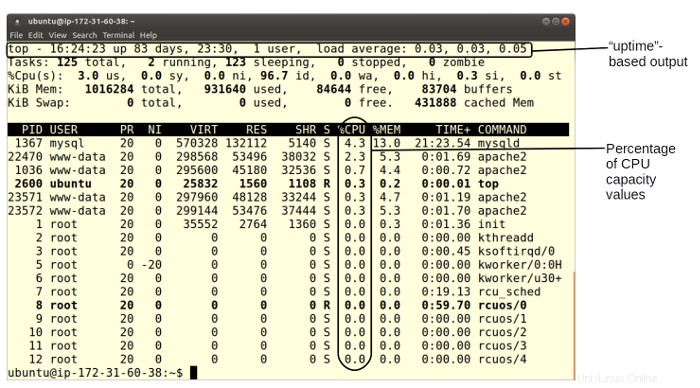
Dado que estamos tratando de resolver problemas de rendimiento, las columnas de datos que más nos deberían interesar son %CPU (porcentaje de la capacidad de la CPU utilizada actualmente por un proceso dado) y %MEM (porcentaje de capacidad de memoria). En especial, querrá tener en cuenta los procesos que aparecen en la parte superior de la lista.
En este caso, puede ver que el demonio MySQL está utilizando el 4,3 % de la CPU del servidor y, en la siguiente columna, el 13 % de su memoria. Si sigue esa fila hacia la izquierda, verá que el ID del proceso (PID) es 1367 y el proceso es "propiedad" de mysql usuario.
Tal vez llegue a la conclusión de que este proceso estaba consumiendo más recursos de los que se pueden justificar y tendrá que ser sacrificado (por el bien mayor, ¿comprende?). Ese top display te dio todo lo que necesitarás para matarlo. Dado que MySQL es un servicio administrado por systemd (en aquellas distribuciones que usan systemd), su primera opción debería ser usar systemctl para detener el proceso suavemente sin poner en riesgo ningún dato de la aplicación.
systemctl stop mysqld
Si systemd no administra el proceso que desea cerrar, o si algo salió mal y systemctl no pudo detenerlo, entonces puede usar kill o killall para eliminar su proceso. Algunos sistemas requieren que instales killall como parte del psmisc paquete. Pasas el PID a kill de esta manera:
kill 1367
killall , por otro lado, usa el nombre del proceso en lugar de su ID.
killall mysqld
Matar o matar a todos, esa es la cuestión . En realidad, la respuesta es algo obvia. killall cerrará un solo proceso, basado en el PID, mientras que killall matará tantas instancias de un programa en particular como se estén ejecutando. Entonces, si hubiera dos o tres instancias de MySQL separadas, tal vez pertenecientes a usuarios separados, todas se detendrían. Antes de ejecutar killall , asegúrese de que no haya ningún proceso con un nombre similar que desee ejecutar y que pueda convertirse en "daños colaterales".
Por supuesto, también deberá ejecutar systemctl disable para asegurarse de que el proceso no se reinicie la próxima vez que arranque.
systemctl disable mysqld Top de descifrado
En caso de que los necesite, la tercera línea de top la salida que vio un poco antes nos da valores de tiempo (como porcentajes) para una serie de otras métricas de CPU. Aquí hay un resumen rápido de la maraña de acrónimos que verá allí:
| Métrica | Significado |
|---|---|
us | Tiempo de ejecución de procesos de alta prioridad (no autorizados) |
sy | Tiempo de ejecución de los procesos del kernel |
ni | Tiempo de ejecución de procesos de baja prioridad (buenos) |
id | Tiempo inactivo |
wa | Tiempo de espera para que se completen los eventos de E/S |
hi | Tiempo dedicado a administrar interrupciones de hardware |
si | Tiempo dedicado a gestionar interrupciones de software |
st | Tiempo robado de esta máquina virtual por su hipervisor (host) |