Apache Spark se ejecuta en JVM (Java Virtual Machine), por lo que se requiere una instalación de Java 8 en funcionamiento para que se ejecuten las aplicaciones. Aparte de eso, hay varios shells enviados dentro del paquete, uno de ellos es pyspark , un shell basado en Python. Para trabajar con eso, también necesitará Python 2 instalado y configurado.
- Para obtener la URL del paquete más reciente de Spark, debemos visitar el sitio de descargas de Spark. Necesitamos elegir el espejo más cercano a nuestra ubicación y copiar la URL proporcionada por el sitio de descarga. Esto también significa que su URL puede ser diferente del ejemplo a continuación. Instalaremos el paquete en
/opt/ , entonces ingresamos al directorio como root :# cd /opt
Y alimente la URL adquirida a wget para obtener el paquete:
# wget https://www-eu.apache.org/dist/spark/spark-2.4.0/spark-2.4.0-bin-hadoop2.7.tgz
- Descomprimiremos el tarball:
# tar -xvf spark-2.4.0-bin-hadoop2.7.tgz
- Y crea un enlace simbólico para que nuestras rutas sean más fáciles de recordar en los próximos pasos:
# ln -s /opt/spark-2.4.0-bin-hadoop2.7 /opt/spark
- Creamos un usuario sin privilegios que ejecutará ambas aplicaciones, maestra y esclava:
# useradd spark
Y configúrelo como propietario de todo /opt/spark directorio, recursivamente:
# chown -R spark:spark /opt/spark*
- Creamos un
systemd archivo de unidad /etc/systemd/system/spark-master.service para el servicio maestro con el siguiente contenido:[Unit]
Description=Apache Spark Master
After=network.target
[Service]
Type=forking
User=spark
Group=spark
ExecStart=/opt/spark/sbin/start-master.sh
ExecStop=/opt/spark/sbin/stop-master.sh
[Install]
WantedBy=multi-user.target
Y también uno para el servicio esclavo que será /etc/systemd/system/spark-slave.service.service con el siguiente contenido:
[Unit]
Description=Apache Spark Slave
After=network.target
[Service]
Type=forking
User=spark
Group=spark
ExecStart=/opt/spark/sbin/start-slave.sh spark://rhel8lab.linuxconfig.org:7077
ExecStop=/opt/spark/sbin/stop-slave.sh
[Install]
WantedBy=multi-user.target
Tenga en cuenta la URL de chispa resaltada. Esto se construye con spark://<hostname-or-ip-address-of-the-master>:7077 , en este caso, la máquina de laboratorio que ejecutará el maestro tiene el nombre de host rhel8lab.linuxconfig.org . El nombre de tu maestro será diferente. Todos los esclavos deben poder resolver este nombre de host y comunicarse con el maestro en el puerto especificado, que es el puerto 7077 por defecto.
- Con los archivos de servicio en su lugar, debemos preguntarle a
systemd para volver a leerlos:# systemctl daemon-reload
- Podemos iniciar nuestro maestro Spark con
systemd :# systemctl start spark-master.service
- Para verificar que nuestro maestro se está ejecutando y funciona, podemos usar systemd status:
# systemctl status spark-master.service
spark-master.service - Apache Spark Master
Loaded: loaded (/etc/systemd/system/spark-master.service; disabled; vendor preset: disabled)
Active: active (running) since Fri 2019-01-11 16:30:03 CET; 53min ago
Process: 3308 ExecStop=/opt/spark/sbin/stop-master.sh (code=exited, status=0/SUCCESS)
Process: 3339 ExecStart=/opt/spark/sbin/start-master.sh (code=exited, status=0/SUCCESS)
Main PID: 3359 (java)
Tasks: 27 (limit: 12544)
Memory: 219.3M
CGroup: /system.slice/spark-master.service
3359 /usr/lib/jvm/java-1.8.0-openjdk-1.8.0.181.b13-9.el8.x86_64/jre/bin/java -cp /opt/spark/conf/:/opt/spark/jars/* -Xmx1g org.apache.spark.deploy.master.Master --host [...]
Jan 11 16:30:00 rhel8lab.linuxconfig.org systemd[1]: Starting Apache Spark Master...
Jan 11 16:30:00 rhel8lab.linuxconfig.org start-master.sh[3339]: starting org.apache.spark.deploy.master.Master, logging to /opt/spark/logs/spark-spark-org.apache.spark.deploy.master.Master-1[...]
La última línea también indica el archivo de registro principal del maestro, que se encuentra en los logs directorio bajo el directorio base de Spark, /opt/spark en nuestro caso. Al examinar este archivo, deberíamos ver una línea al final similar al siguiente ejemplo:
2019-01-11 14:45:28 INFO Master:54 - I have been elected leader! New state: ALIVE
También deberíamos encontrar una línea que nos diga dónde está escuchando la interfaz maestra:
2019-01-11 16:30:03 INFO Utils:54 - Successfully started service 'MasterUI' on port 8080
Si apuntamos un navegador al puerto de la máquina host 8080 , deberíamos ver la página de estado del maestro, sin trabajadores adjuntos en este momento.
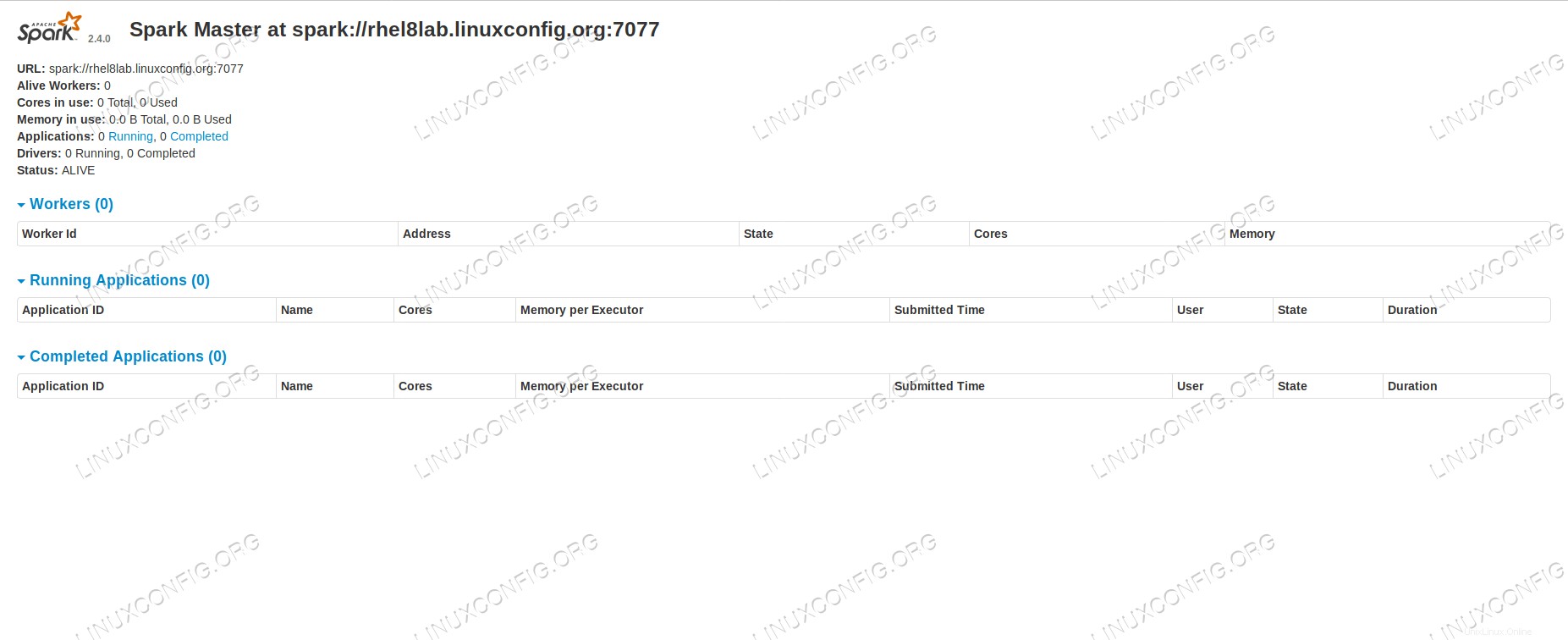 Página de estado principal de Spark sin trabajadores adjuntos.
Página de estado principal de Spark sin trabajadores adjuntos.
Tenga en cuenta la línea de URL en la página de estado del maestro de Spark. Esta es la misma URL que necesitamos usar para cada archivo de unidad de esclavo que creamos en step 5 .
Si recibimos un mensaje de error de "conexión rechazada" en el navegador, probablemente necesitemos abrir el puerto en el firewall:
# firewall-cmd --zone=public --add-port=8080/tcp --permanent
success
# firewall-cmd --reload
success
- Nuestro maestro se está ejecutando, le adjuntaremos un esclavo. Iniciamos el servicio esclavo:
# systemctl start spark-slave.service
- Podemos verificar que nuestro esclavo se está ejecutando con systemd:
# systemctl status spark-slave.service
spark-slave.service - Apache Spark Slave
Loaded: loaded (/etc/systemd/system/spark-slave.service; disabled; vendor preset: disabled)
Active: active (running) since Fri 2019-01-11 16:31:41 CET; 1h 3min ago
Process: 3515 ExecStop=/opt/spark/sbin/stop-slave.sh (code=exited, status=0/SUCCESS)
Process: 3537 ExecStart=/opt/spark/sbin/start-slave.sh spark://rhel8lab.linuxconfig.org:7077 (code=exited, status=0/SUCCESS)
Main PID: 3554 (java)
Tasks: 26 (limit: 12544)
Memory: 176.1M
CGroup: /system.slice/spark-slave.service
3554 /usr/lib/jvm/java-1.8.0-openjdk-1.8.0.181.b13-9.el8.x86_64/jre/bin/java -cp /opt/spark/conf/:/opt/spark/jars/* -Xmx1g org.apache.spark.deploy.worker.Worker [...]
Jan 11 16:31:39 rhel8lab.linuxconfig.org systemd[1]: Starting Apache Spark Slave...
Jan 11 16:31:39 rhel8lab.linuxconfig.org start-slave.sh[3537]: starting org.apache.spark.deploy.worker.Worker, logging to /opt/spark/logs/spark-spar[...]
Esta salida también proporciona la ruta al archivo de registro del esclavo (o trabajador), que estará en el mismo directorio, con "trabajador" en su nombre. Al revisar este archivo, deberíamos ver algo similar al siguiente resultado:
2019-01-11 14:52:23 INFO Worker:54 - Connecting to master rhel8lab.linuxconfig.org:7077...
2019-01-11 14:52:23 INFO ContextHandler:781 - Started o.s.j.s.ServletContextHandler@62059f4a{/metrics/json,null,AVAILABLE,@Spark}
2019-01-11 14:52:23 INFO TransportClientFactory:267 - Successfully created connection to rhel8lab.linuxconfig.org/10.0.2.15:7077 after 58 ms (0 ms spent in bootstraps)
2019-01-11 14:52:24 INFO Worker:54 - Successfully registered with master spark://rhel8lab.linuxconfig.org:7077
Esto indica que el trabajador está correctamente conectado al maestro. En este mismo archivo de registro encontraremos una línea que nos dice la URL que está escuchando el trabajador:
2019-01-11 14:52:23 INFO WorkerWebUI:54 - Bound WorkerWebUI to 0.0.0.0, and started at http://rhel8lab.linuxconfig.org:8081
Podemos dirigir nuestro navegador a la página de estado del trabajador, donde aparece su maestro.
 Página de estado del trabajador de Spark, conectada al maestro.
Página de estado del trabajador de Spark, conectada al maestro.
En el archivo de registro del maestro, debería aparecer una línea de verificación:
2019-01-11 14:52:24 INFO Master:54 - Registering worker 10.0.2.15:40815 with 2 cores, 1024.0 MB RAM
Si volvemos a cargar la página de estado del maestro ahora, el trabajador también debería aparecer allí, con un enlace a su página de estado.
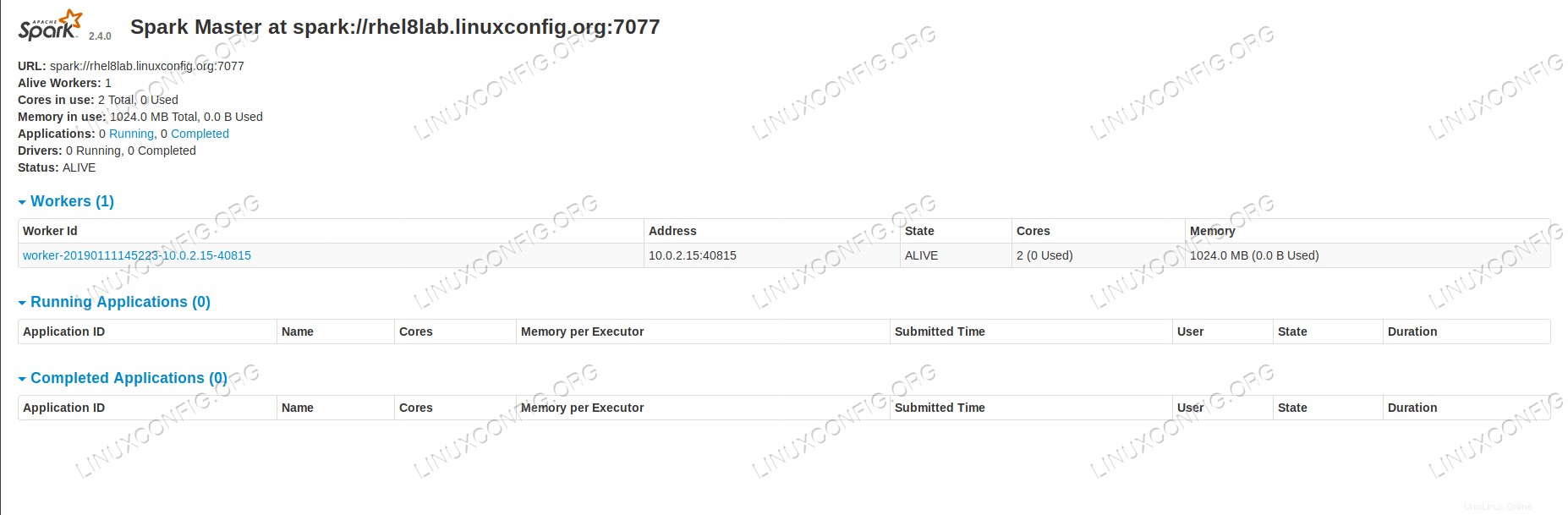 Página de estado principal de Spark con un trabajador adjunto.
Página de estado principal de Spark con un trabajador adjunto.
Estas fuentes verifican que nuestro clúster esté conectado y listo para funcionar.
- Para ejecutar una tarea simple en el clúster, ejecutamos uno de los ejemplos enviados con el paquete que descargamos. Considere el siguiente archivo de texto simple
/opt/spark/test.file :line1 word1 word2 word3
line2 word1
line3 word1 word2 word3 word4
Ejecutaremos el wordcount.py ejemplo en él que contará la ocurrencia de cada palabra en el archivo. Podemos usar la spark usuario, sin root privilegios necesarios.
$ /opt/spark/bin/spark-submit /opt/spark/examples/src/main/python/wordcount.py /opt/spark/test.file
2019-01-11 15:56:57 INFO SparkContext:54 - Submitted application: PythonWordCount
2019-01-11 15:56:57 INFO SecurityManager:54 - Changing view acls to: spark
2019-01-11 15:56:57 INFO SecurityManager:54 - Changing modify acls to: spark
[...]
A medida que se ejecuta la tarea, se proporciona una salida larga. Cerca del final de la salida, se muestra el resultado, el clúster calcula la información necesaria:
2019-01-11 15:57:05 INFO DAGScheduler:54 - Job 0 finished: collect at /opt/spark/examples/src/main/python/wordcount.py:40, took 1.619928 s
line3: 1
line2: 1
line1: 1
word4: 1
word1: 3
word3: 2
word2: 2
[...]
Con esto hemos visto nuestro Apache Spark en acción. Se pueden instalar y conectar nodos esclavos adicionales para escalar la potencia informática de nuestro clúster.
 Caparazón de chispa con pyspark.
Caparazón de chispa con pyspark.