Kubernetes es una plataforma de código abierto para administrar cargas de trabajo y servicios en contenedores que facilita la configuración y la automatización declarativas. El nombre Kubernetes se originó del griego y significa timonel o piloto. Es portátil y extensible y tiene un ecosistema en rápido crecimiento. Los servicios y herramientas de Kubernetes están ampliamente disponibles.
En este artículo, analizaremos una vista de 10 000 pies de los principales componentes de Kubernetes, desde de qué se compone cada contenedor hasta cómo se implementa y programa un contenedor en un módulo para cada uno de los trabajadores. Es crucial comprender todos los detalles del clúster de Kubernetes para poder implementar y diseñar una solución basada en Kubernetes como un orquestador para aplicaciones en contenedores.
Aquí hay un resumen sobre las cosas que vamos a cubrir en este artículo:
- Componentes del panel de control
- Los componentes del trabajador de Kubernetes
- Pods como bloques de construcción básicos
- Servicios de Kubernetes, balanceadores de carga y controladores de entrada
- Despliegues de Kubernetes y Daemon Sets
- Almacenamiento persistente en Kubernetes
El plano de control de Kubernetes
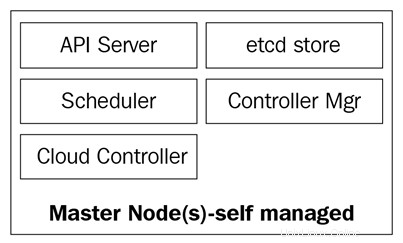
Los nodos maestros de Kubernetes son donde residen los servicios del plano de control central; no todos los servicios tienen que residir en el mismo nodo; sin embargo, por centralización y practicidad, a menudo se implementan de esta manera. Obviamente, esto plantea dudas sobre la disponibilidad de los servicios; sin embargo, se pueden superar fácilmente si se tienen varios nodos y se proporcionan solicitudes de equilibrio de carga para lograr un conjunto de nodos maestros de alta disponibilidad. .
Los nodos maestros se componen de cuatro servicios básicos:
- El kube-apserver
- El programador de kube
- El kube-controller-manager
- La base de datos etcd
Los nodos maestros pueden ejecutarse en servidores bare metal, máquinas virtuales o una nube privada o pública, pero no se recomienda ejecutar cargas de trabajo de contenedores en ellos. Veremos más sobre esto más adelante.
El siguiente diagrama muestra los componentes de los nodos maestros de Kubernetes:
El kube-apiserver
El servidor API es lo que une todo. Es la API REST de frontend del clúster que recibe manifiestos para crear, actualizar y eliminar objetos API como servicios, pods, Ingress y otros.
El kube-apiserver es el único servicio con el que deberíamos estar hablando; también es el único que escribe y habla con la base de datos etcd para registrar el estado del clúster. Con el comando kubectl enviaremos comandos para interactuar con él. Esta será nuestra navaja suiza cuando se trata de Kubernetes.
El kube-controller-manager
El demonio kube-controller-manager, en pocas palabras, es un conjunto de bucles de control infinitos que se envían por simplicidad en un solo binario. Observa el estado deseado definido del clúster y se asegura de que se logre y satisfaga moviendo todas las partes y piezas necesarias para lograrlo. El kube-controller-manager no es solo un controlador; contiene varios bucles diferentes que observan diferentes componentes en el clúster. Algunos de ellos son el controlador de servicio, el controlador de espacio de nombres, el controlador de cuenta de servicio y muchos otros. Puede encontrar cada controlador y su definición en el repositorio de Kubernetes GitHub:https://github.com/kubernetes/kubernetes/tree/master/pkg/controller.
El kube-scheduler
Kube-scheduler programa los pods recién creados en nodos con espacio suficiente para satisfacer las necesidades de recursos de los pods. Básicamente, escucha el kube-apiserver y el kube-controller-manager en busca de pods recién creados que se colocan en una cola y luego el programador los programa en un nodo disponible. La definición de kube-scheduler se puede encontrar aquí:https://github.com/kubernetes/kubernetes/blob/master/pkg/scheduler.
Además de los recursos informáticos, kube-scheduler también lee las reglas de afinidad y antiafinidad de los nodos para averiguar si un nodo puede o no ejecutar ese pod.
La base de datos etcd
La base de datos etcd es un almacén de clave-valor coherente muy confiable que se utiliza para almacenar el estado del clúster de Kubernetes. Contiene el estado actual de los pods en los que se ejecuta el nodo, cuántos nodos tiene actualmente el clúster, cuál es el estado de esos nodos, cuántas réplicas de implementación se están ejecutando, nombres de servicios y otros.
Como mencionamos antes, solo kube-apiserver se comunica con la base de datos etcd. Si el kube-controller-manager necesita verificar el estado del clúster, pasará por el servidor API para obtener el estado de la base de datos etcd, en lugar de consultar la tienda etcd directamente. Lo mismo sucede con kube-scheduler si el programador necesita informar que un pod se detuvo o se asignó a otro nodo; informará al servidor API, y el servidor API almacenará el estado actual en la base de datos etcd.
Con etcd, hemos cubierto todos los componentes principales de nuestros nodos maestros de Kubernetes para que estemos listos para administrar nuestro clúster. Pero un grupo no solo está compuesto por maestros; aún necesitamos los nodos que realizarán el trabajo pesado al ejecutar nuestras aplicaciones.
Nodos de trabajo de Kubernetes
Los nodos trabajadores que realizan esta tarea en Kubernetes se denominan simplemente nodos. Anteriormente, alrededor de 2014, se llamaban minions, pero este término se reemplazó más tarde con solo nodos, ya que el nombre se confundía con la terminología de Salt y hacía pensar a la gente que Salt desempeñaba un papel importante en Kubernetes.
Estos nodos son el único lugar donde ejecutará cargas de trabajo, ya que no se recomienda tener contenedores o cargas en los nodos maestros, ya que deben estar disponibles para administrar todo el clúster. Los nodos son muy simples en términos de componentes; solo requieren de tres servicios para cumplir con su cometido:
- Cubelet
- Proxy de Kube
- Tiempo de ejecución del contenedor
Exploremos estos tres componentes con un poco más de profundidad.
El kubelet
El kubelet es un componente de Kubernetes de bajo nivel y uno de los más importantes después del kube-apiserver; ambos componentes son esenciales para el aprovisionamiento de pods/contenedores en el clúster. El kubelet es un servicio que se ejecuta en los nodos de Kubernetes y escucha el servidor API para la creación de pods. El kubelet solo se encarga de iniciar/detener y asegurarse de que los contenedores en las vainas estén saludables; el kubelet no podrá administrar ningún contenedor que no haya creado.
El kubelet logra los objetivos hablando con el tiempo de ejecución del contenedor a través de la interfaz de tiempo de ejecución del contenedor (CRI) . El CRI proporciona capacidad de conexión al kubelet a través de un cliente gRPC, que puede comunicarse con diferentes tiempos de ejecución de contenedores. Como mencionamos anteriormente, Kubernetes admite múltiples tiempos de ejecución de contenedores para implementar contenedores, y así es como logra un soporte tan diverso para diferentes motores.
Puede verificar el código fuente de kubelet a través de https://github.com/kubernetes/kubernetes/tree/master/pkg/kubelet.
El proxy kube
El kube-proxy es un servicio que reside en cada nodo del clúster y es el que hace posible la comunicación entre pods, contenedores y nodos. Este servicio observa el kube-apiserver en busca de cambios en los servicios definidos (el servicio es una especie de equilibrador de carga lógico en Kubernetes; profundizaremos en los servicios más adelante en este artículo) y mantiene la red actualizada a través de las reglas de iptables que reenvían el tráfico a los puntos finales correctos. Kube-proxy también configura reglas en iptables que equilibran la carga aleatoriamente entre los pods detrás de un servicio.
Este es un ejemplo de una regla iptables creada por el kube-proxy:
-A KUBE-SERVICES -d 10.0.162.61/32 -p tcp -m comment --comment "predeterminado/ejemplo:no tiene terminales" -m tcp --dport 80 -j REJECT --reject-with icmp-port-unreachable
Tenga en cuenta que este es un servicio sin puntos finales (sin pods detrás de él).
Tiempo de ejecución del contenedor
Para poder hacer girar los contenedores, necesitamos un tiempo de ejecución del contenedor . Este es el motor base que creará los contenedores en el kernel de los nodos para que se ejecuten nuestros pods. El kubelet se comunicará con este tiempo de ejecución y activará o detendrá nuestros contenedores a pedido.
Actualmente, Kubernetes es compatible con cualquier tiempo de ejecución de contenedor compatible con OCI, como Docker, rkt, runc, runsc, etc.
Puede consultar este https://github.com/opencontainers/runtime-spec para obtener más información sobre todas las especificaciones de la página OCI Git-Hub.
Ahora que hemos explorado todos los componentes principales que forman un clúster, echemos un vistazo a lo que se puede hacer con ellos y cómo Kubernetes nos ayudará a orquestar y administrar nuestras aplicaciones en contenedores.
Objetos de Kubernetes
Los objetos de Kubernetes son exactamente eso:son objetos persistentes lógicos o abstracciones que representarán el estado de su clúster. Usted es el encargado de decirle a Kubernetes cuál es el estado deseado de ese objeto para que pueda trabajar para mantenerlo y asegurarse de que el objeto existe.
Para crear un objeto, hay dos cosas que debe tener:un estado y su especificación. Kubernetes proporciona el estado y es el estado actual del objeto. Kubernetes administrará y actualizará ese estado según sea necesario para estar de acuerdo con su estado deseado. El campo spec , por otro lado, es lo que proporciona a Kubernetes y es lo que le dice para describir el objeto que desea. Por ejemplo, la imagen que desea que se ejecute en el contenedor, la cantidad de contenedores de esa imagen que desea ejecutar, etc.
Cada objeto tiene campos de especificación específicos para el tipo de tarea que realiza, y proporcionará estas especificaciones en un archivo YAML que se envía al kube-apiserver con kubectl, que lo transforma en JSON y lo envía como una solicitud de API. . Profundizaremos en cada objeto y sus campos de especificaciones más adelante en este artículo.
Este es un ejemplo de un YAML que se envió a kubectl:
gato <
Los campos básicos de la definición del objeto son los primeros, y estos no variarán de un objeto a otro y se explican por sí mismos. Echemos un vistazo rápido a ellos:
Entonces, ahora hemos repasado los campos más utilizados y sus contenidos; puede obtener más información sobre las convenciones de la API de Kuberntes en https://github.com/kubernetes/community/blob/master/contributors/devel/api-conventions.md
Algunos de los campos del objeto se pueden modificar posteriormente después de que se haya creado el objeto, pero eso dependerá del objeto y el campo que desee modificar.
La siguiente es una breve lista de los diversos objetos de Kubernetes que puede crear:
Y hay muchos más.
Echemos un vistazo más de cerca a cada uno de estos elementos.
Los pods son los objetos más básicos en Kubernetes y también los más importantes. Todo gira en torno a ellos; ¡podemos decir que Kubernetes es para los pods! Todos los demás objetos están aquí para servirles, y todas las tareas que realizan son para que las vainas alcancen el estado deseado.
Entonces, ¿qué es un pod y por qué son tan importantes?
Un pod es un objeto lógico que ejecuta uno o más contenedores juntos en el mismo espacio de nombres de red, la misma comunicación entre procesos (IPC) y, a veces, según la versión de Kubernetes, el mismo ID de proceso (PID) espacio de nombres Esto se debe a que son ellos los que van a ejecutar nuestros contenedores y, por lo tanto, serán el centro de atención. El objetivo de Kubernetes es ser un orquestador de contenedores y, con los pods, hacemos posible la orquestación.
Como mencionamos antes, los contenedores en el mismo pod viven en una "burbuja" donde pueden comunicarse entre sí a través de localhost, ya que son locales entre sí. Un contenedor en un pod tiene la misma dirección IP que el otro contenedor porque comparten un espacio de nombres de red, pero en la mayoría de los casos, se ejecutará uno a uno, es decir, un solo contenedor por pod. . Varios contenedores por pod solo se usan en escenarios muy específicos, como cuando una aplicación requiere un ayudante, como un impulsor de datos o un proxy que necesita comunicarse de manera rápida y resistente con la aplicación principal.
La forma en que define un pod es la misma que lo haría para cualquier otro objeto de Kubernetes:a través de un YAML que contiene todas las especificaciones y definiciones del pod:
kind:PodapiVersion:v1metadata:name:hello-podlabels: hello:podspec: container: - name:hello-container image:alpine args: - echo - "Hello World"
Repasemos las definiciones básicas de pod necesarias en el campo spec para crear nuestro pod:
Estas son las especificaciones más básicas que declarará en un pod; otras especificaciones requerirán que tenga un poco más de conocimiento previo sobre cómo usarlas y cómo interactúan con otros objetos de Kubernetes. Los revisaremos más adelante en este artículo; algunos de ellos son los siguientes:
Para ver los pods que se están ejecutando actualmente en su clúster, puede ejecutar kubectl get pods:
[email protected]:~$ kubectl get podsNAME ESTADO LISTO REINICIA AGEbusybox 1/1 En ejecución 120 5d
Como alternativa, puede ejecutar kubectl describe pods sin especificar ningún pod. Esto imprimirá una descripción de cada pod que se ejecuta en el clúster. En este caso, será solo el pod busybox ya que es el único que se está ejecutando actualmente:
[Correo electrónico protegido]:~ $ kubectl Describa podsname:BusyBoxNamespace:DefaultPriority:0PriorityClassName:
Las vainas son mortales. Una vez que muere o se elimina, no se pueden recuperar. Su IP y los contenedores que se ejecutaban en él desaparecerán; son totalmente efímeros. Los datos en los pods que están montados como un volumen pueden sobrevivir o no, dependiendo de cómo lo configure. Si nuestros pods mueren y los perdemos, ¿cómo nos aseguramos de que todos nuestros microservicios estén funcionando? Bueno, las implementaciones son la respuesta.
Los pods por sí mismos no son muy útiles ya que no es muy eficiente tener más de una sola instancia de nuestra aplicación ejecutándose en un solo pod. Aprovisionar cientos de copias de nuestra aplicación en diferentes pods sin tener un método para buscarlos todos se saldrá de control muy rápido.
Aquí es donde entran en juego las implementaciones. Con las implementaciones, podemos administrar nuestros pods con un controlador. Esto nos permite no solo decidir cuántos queremos ejecutar, sino que también podemos administrar las actualizaciones cambiando la versión de la imagen o la imagen misma que ejecutan nuestros contenedores. Las implementaciones son con lo que trabajará la mayor parte del tiempo. Tanto con las implementaciones como con los pods y cualquier otro objeto que mencionamos antes, tienen su propia definición dentro de un archivo YAML:
apiVersion:apps/v1kind:Deploymentmetadata:nombre:nginx-deployment etiquetas: deployment:nginxspec:replicas:3 selector: matchLabels: aplicación:nginx plantilla: metadatos: etiquetas: aplicación:nginx especificaciones: contenedores: - nombre:nginx imagen:nginx:1.7.9 puertos: - containerPort:80
Empecemos a explorar su definición.
Al comienzo de YAML, tenemos campos más generales, como apiVersion, kind y metadata. Pero bajo especificaciones es donde encontraremos las opciones específicas para este Objeto API.
Bajo especificaciones, podemos agregar los siguientes campos:
Selector :con el campo Selector, la implementación sabrá a qué pods dirigirse cuando se apliquen los cambios. Hay dos campos que usará debajo del selector: matchLabels y matchExpressions. Con matchLabels, el selector utilizará las etiquetas de los pods (pares clave/valor). Es importante tener en cuenta que todas las etiquetas que especifique aquí tendrán AND. Esto significa que el pod requerirá que tenga todas las etiquetas que especifique en matchLabels.
Réplicas :Esto indicará la cantidad de pods que la implementación necesita para seguir ejecutándose a través del controlador de replicación; por ejemplo, si especifica tres réplicas y uno de los pods muere, el controlador de replicación observará la especificación de réplicas como el estado deseado e informará al programador para programar un nuevo pod, ya que el estado actual es ahora 2 desde que el pod murió.
Límite del historial de revisiones :cada vez que realiza un cambio en la implementación, este cambio se guarda como una revisión de la implementación, que luego puede revertir a ese estado anterior o mantener un registro de lo que se cambió. Puede consultar su historial con kubectl historial de implementación deployment/
Estrategia :Esto le permitirá decidir cómo quiere manejar cualquier actualización o escala de pod horizontal. Para sobrescribir el predeterminado, que es rollingUpdate, debe escribir la clave de tipo, donde puede elegir entre dos valores: recrear o rollingUpdate.
Si bien recrear es una forma rápida de actualizar su implementación, eliminará todos los pods y los reemplazará por otros nuevos, pero implicará que deberá tener en cuenta que habrá un tiempo de inactividad del sistema para este tipo de estrategia. RollingUpdate, por otro lado, es más fluido y lento, y es ideal para aplicaciones con estado que pueden reequilibrar sus datos. El rollingUpdate abre la puerta para dos campos más, que son maxSurge y maxUndisponible.
El primero será cuántos pods por encima de la cantidad total desea al realizar una actualización; por ejemplo, una implementación con 100 pods y un maxSurge del 20 % crecerá hasta un máximo de 120 pods durante la actualización. La siguiente opción le permitirá seleccionar cuántos pods en el porcentaje que está dispuesto a matar para reemplazarlos por otros nuevos en un escenario de 100 pods. En los casos en los que haya un 20 % máximo de no disponible, solo 20 pods se eliminarán y se reemplazarán por otros nuevos antes de continuar reemplazando el resto de la implementación.
Plantilla :Este es solo un campo de especificación de pod anidado donde incluirá todas las especificaciones y metadatos de los pods que administrará la implementación.
Hemos visto que, con las implementaciones, administramos nuestros pods y nos ayudan a mantenerlos en el estado que deseamos. Todos estos pods todavía están en algo llamado el clúster red , que es una red cerrada en la que solo los componentes del clúster de Kubernetes pueden comunicarse entre sí, incluso con su propio conjunto de rangos de IP. ¿Cómo hablamos con nuestras cápsulas desde el exterior? ¿Cómo llegamos a nuestra aplicación? Aquí es donde entran en juego los servicios.
Servicios :
El nombre servicio no describe completamente lo que realmente hacen los servicios en Kubernetes. Los servicios de Kubernetes son los que enrutan el tráfico a nuestros pods. Podemos decir que los servicios son lo que une las vainas.
Imaginemos que tenemos un tipo típico de aplicación de front-end/back-end en el que nuestros pods de front-end se comunican con los de back-end a través de las direcciones IP de los pods. Si un pod en el backend muere, perdemos la comunicación con nuestro backend. Esto no solo se debe a que el nuevo pod no tendrá la misma dirección IP del pod que murió, sino que ahora también tenemos que reconfigurar nuestra aplicación para usar la nueva dirección IP. Este problema y problemas similares se resuelven con los servicios.
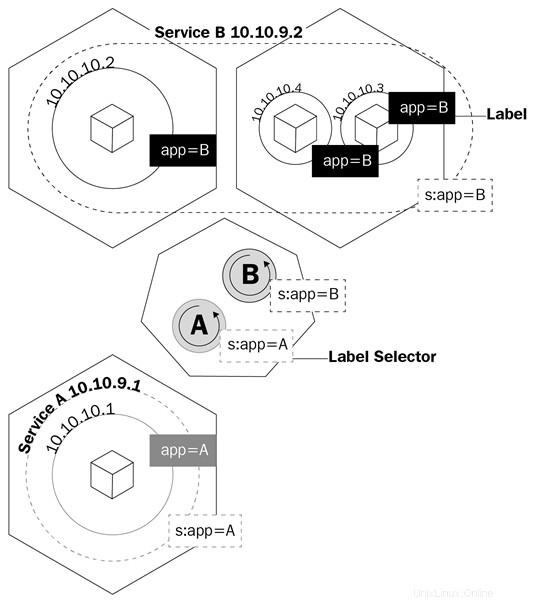
Un servicio es un objeto lógico que le dice al kube-proxy que cree reglas de iptables basadas en qué pods están detrás del servicio. Los servicios configuran sus puntos finales, que es como se llaman los pods detrás de un servicio, de la misma manera que las implementaciones saben qué pods controlar, el campo selector y las etiquetas de los pods.
Este diagrama muestra cómo los servicios usan las etiquetas para administrar el tráfico:
Los servicios no solo harán que kube-proxy cree reglas para enrutar el tráfico; también activará algo llamado kube-dns.
Kube-dns es un conjunto de pods con contenedores SkyDNS que se ejecutan en el clúster que proporciona un servidor DNS y un reenviador, que creará registros para servicios y, a veces, pods para facilitar su uso. Cada vez que cree un servicio, se creará un registro DNS que apunta a la dirección IP del clúster interno del servicio con el formulario nombre-servicio.espacio de nombres.svc.cluster.local. Puede obtener más información sobre las especificaciones de DNS de Kubernetes aquí: https://github.com/kubernetes/dns/blob/master/docs/specification.md.
Volviendo a nuestro ejemplo, ahora solo tendremos que configurar nuestra aplicación para hablar con el servicio nombre de dominio completo (FQDN) para hablar con nuestros pods de backend. De esta manera, no importará qué dirección IP tengan los pods y los servicios. Si un pod detrás del servicio muere, el servicio se encargará de todo usando el registro A, ya que podremos decirle a nuestra interfaz que enrute todo el tráfico a my-svc. La lógica del servicio se encargará de todo lo demás.
Hay varios tipos de servicio que puede crear cada vez que declara el objeto que se creará en Kubernetes. Repasémoslos para ver cuál se adapta mejor al tipo de trabajo que necesitamos:
ClusterIP :Este es el servicio predeterminado. Siempre que cree un servicio ClusterIP, creará un servicio con una dirección IP interna del clúster que solo se podrá enrutar dentro del clúster de Kubernetes. Este tipo es ideal para pods que solo necesitan comunicarse entre sí y no salir del clúster.
Puerto de nodo :cuando crea este tipo de servicio, se asignará de forma predeterminada un puerto aleatorio de 30000 a 32767 para reenviar el tráfico a los pods de punto final del servicio. Puede anular este comportamiento especificando un puerto de nodo en la matriz de puertos. Una vez que se haya definido, podrá acceder a sus pods a través de
Equilibrador de carga :La mayoría de las veces, ejecutará Kubernetes en un proveedor de nube. El tipo LoadBalancer es ideal para estas situaciones, ya que podrá asignar direcciones IP públicas a su servicio a través de la API de su proveedor de nube. Este es el servicio ideal para cuando desea comunicarse con sus pods desde fuera de su clúster. Con LoadBalancer, podrá no solo asignar una dirección IP pública sino también, utilizando Azure, asignar una dirección IP privada desde su red privada virtual. Por lo tanto, puede hablar con sus pods desde Internet o internamente en su subred privada.
Revisemos la definición de servicio de YAML:
apiVersion:v1kind:Servicemetadata: name:my-servicespec:selector: app:front-end type:NodePort ports: - name:http port:80 targetPort:8080 nodePort:30024 protocol:TCP
El YAML de un servicio es muy simple y las especificaciones variarán según el tipo de servicio que estés creando. Pero lo más importante que debe tener en cuenta son las definiciones de los puertos. Echemos un vistazo a estos:
Aunque ahora entendemos cómo podemos comunicarnos con los pods en nuestro clúster, todavía necesitamos entender cómo vamos a manejar el problema de perder nuestros datos cada vez que se termina un pod. Aquí es donde Persistente Volúmenes (VP ) viene a usar.
El almacenamiento persistente en el mundo de los contenedores es un problema grave. El único almacenamiento que persiste en las ejecuciones del contenedor son las capas de la imagen, y son de solo lectura. La capa en la que se ejecuta el contenedor es de lectura/escritura, pero todos los datos de esta capa se eliminan una vez que se detiene el contenedor. Con las vainas, esto es lo mismo. Cuando un contenedor muere, los datos escritos en él desaparecen.
Kubernetes tiene un conjunto de objetos para manejar el almacenamiento entre pods. El primero que discutiremos son los volúmenes.
Los volúmenes resuelven uno de los mayores problemas cuando se trata de almacenamiento persistente. En primer lugar, los volúmenes no son en realidad objetos, sino una definición de las especificaciones de un pod. Cuando crea un pod, puede definir un volumen en el campo de especificaciones del pod. Los contenedores en este pod podrán montar el volumen en su espacio de nombres de montaje, y el volumen estará disponible en los reinicios o bloqueos del contenedor. Sin embargo, los volúmenes están vinculados a los pods y, si se elimina el pod, el volumen también desaparecerá. Los datos sobre el volumen son otra historia; la persistencia de los datos dependerá del backend de ese volumen.
Kubernetes admite varios tipos de volúmenes o fuentes de volumen y cómo se denominan en las especificaciones de la API, que van desde mapas de sistemas de archivos del nodo local, discos virtuales de proveedores de la nube y volúmenes respaldados por almacenamiento definidos por software. Los montajes de sistemas de archivos locales son los más comunes que verá cuando se trata de volúmenes regulares. Es importante tener en cuenta que la desventaja de usar un sistema de archivos de nodo local es que los datos no estarán disponibles en todos los nodos del clúster y solo en el nodo donde se programó el pod.
Examinemos cómo se define un pod con un volumen en YAML:
apiVersion:v1kind:Podmetadata:nombre:test-pdspec:contenedores:- imagen:k8s.gcr.io/test-webserver nombre:test-container volumeMounts: - mountPath:/test-pd nombre:test-volume volumes:- nombre:test-volume hostPath: ruta:/data tipo:Directorio
Observe cómo hay un campo llamado volumes bajo spec y luego hay otro llamado volumeMounts.
El primer campo (volúmenes) es donde define el volumen que desea crear para ese pod. Este campo siempre requerirá un nombre y luego una fuente de volumen. Dependiendo de la fuente, los requisitos serán diferentes. En este ejemplo, la fuente sería hostPath, que es el sistema de archivos local de un nodo. hostPath admite varios tipos de asignaciones, que van desde directorios, archivos, dispositivos de bloque e incluso sockets Unix.
Debajo del segundo campo, volumeMounts, tenemos mountPath, que es donde defines la ruta dentro del contenedor donde deseas montar tu volumen. El parámetro de nombre es cómo se especifica en el pod qué volumen usar. Esto es importante porque puede tener varios tipos de volúmenes definidos en volúmenes, y el nombre será la única forma en que el pod sabrá cuál
Puede obtener más información sobre los diferentes tipos de volúmenes aquí https://kubernetes.io/docs/concepts/storage/volumes/#types-of-volumes y en el documento de referencia de la API de Kubernetes (https://kubernetes.io/docs /referencia/generado/kubernetes-api/v1.11/#volume-v1-core).
Que los volúmenes mueran con las vainas no es lo ideal. Necesitamos almacenamiento que persista, y así es como surgió la necesidad de PV.
La principal diferencia entre volúmenes y PV es que, a diferencia de los volúmenes, los PV son en realidad objetos de la API de Kubernetes, por lo que puede administrarlos individualmente como entidades separadas y, por lo tanto, persisten incluso después de eliminar un pod.
Quizás se pregunte por qué esta subsección tiene PV, persistente volumen reclamos (PVC ), y clases de almacenamiento, todas mezcladas. Esto se debe a que todas dependen unas de otras, y es fundamental comprender cómo interactúan entre sí para aprovisionar almacenamiento para nuestros pods.
Let's begin with PVs and PVCs. Like volumes, PVs have a storage source, so the same mechanism that volumes have applies here. You will either have a software-defined storage cluster providing a logical unit number (LUN ), a cloud provider giving virtual disks, or even a local filesystem to the Kubernetes node, but here, instead of being called volume sources, they are called persistent volume types instead.
PVs are pretty much like LUNs in a storage array:you create them, but without a mapping; they are just a bunch of allocated storage waiting to be used. PVCs are like LUN mappings:they are backed or bound to a PV and also are what you actually define, relate, and make available to the pod that it can then use for its containers.
The way you use PVCs on pods is exactly the same as with normal volumes. You have two fields:one to specify which PVC you want to use, and the other one to tell the pod on which container to use that PVC.
The YAML for a PVC API object definition should have the following code:
apiVersion:v1kind:PersistentVolumeClaimmetadata:name:gluster-pvc spec:accessModes:- ReadWriteMany resources: requests: storage:1Gi
The YAML for pod should have the following code:
kind:PodapiVersion:v1metadata:name:mypodspec:containers: - name:myfrontend image:nginx volumeMounts: - mountPath:"/mnt/gluster" name:volume volumes: - name:volume persistentVolumeClaim: claimName:gluster-pvc
When a Kubernetes administrator creates PVC, there are two ways that this request is satisfied:
Storage classes are like a way of tiering your storage. You can create a class that provisions slow storage volumes, or another one with hyper-fast SSD drives. However, storage classes are a little bit more complex than just tiering. As we mentioned in the two ways of creating PVC, storage classes are what make dynamic provisioning possible. When working on a cloud environment, you don't want to be manually creating every backend disk for every PV. Storage classes will set up something called a provisioner , which invokes the volume plug-in that's necessary to talk to your cloud provider's API. Every provisioner has its own settings so that it can talk to the specified cloud provider or storage provider.
You can provision storage classes in the following way; this is an example of a storage class using Azure-disk as a disk provisioner:
kind:StorageClassapiVersion:storage.k8s.io/v1metadata:name:my-storage-classprovisioner:kubernetes.io/azure-diskparameters:storageaccounttype:Standard_LRS kind:Shared
Each storage class provisioner and PV type will have different requirements and parameters, as well as volumes, and we have already had a general overview of how they work and what we can use them for. Learning about specific storage classes and PV types will depend on your environment; you can learn more about each one of them by clicking on the following links:
In this article, we learned about what Kubernetes is, its components, and what are the advantages of using orchestration are. With this, identifying each of Kubernetes API objects, their purpose and their use cases should be easy. You should now be able to understand how the master nodes control the cluster and the scheduling of the containers in the worker nodes.
If you found this article useful, ‘ Hands-On Linux for Architects ’ should be helpful for you. With this book, you will be covering everything from Linux components and functionalities to hardware and software support, which will help you implementing and tuning effective Linux-based solutions. You will be taken through an overview of Linux design methodology and core concepts of designing a solution. If you’re a Linux system administrator, Linux support engineer, DevOps engineer, Linux consultant or anyone looking to learn or expand their knowledge in architecting, this book is for you.
Pods:la base de Kubernetes
Despliegues
Kubernetes y almacenamiento persistente
Volúmenes
Volúmenes persistentes, reclamos de volumen persistente y clases de almacenamiento