En este artículo, veremos cómo crear su primera implementación en un clúster de Kubernetes. Como ejemplo, crearemos una implementación para NginX.
Una vez que tengamos un clúster de Kubernetes en ejecución, podemos implementar nuestras aplicaciones en contenedores encima de él. Podemos crear una configuración de implementación de Kubernetes para lograr esto.
Una implementación proporciona actualizaciones declarativas para Pods y ReplicaSets. Describimos un estado deseado en la implementación y el controlador de implementación cambia el estado real al estado deseado a un ritmo controlado.
Podemos crear y administrar una implementación mediante la interfaz de línea de comandos "kubectl" de Kubernetes. Kubectl usa la API de Kubernetes para interactuar con el clúster.
Hay tres etapas en un ciclo de vida de implementación:
- Progresando : Kubernetes marca una implementación como en progreso cuando la implementación crea un nuevo conjunto de réplicas, la implementación está ampliando su conjunto de réplicas más nuevo o reduciendo su conjunto de réplicas anterior o los nuevos pods están listos o disponibles
- Completar : Kubernetes marca una implementación como completa cuando todas las réplicas asociadas con la implementación se han actualizado, están disponibles, no hay réplicas antiguas para la implementación en ejecución.
- Error : Esto puede ocurrir debido a una cuota insuficiente, fallas en la sonda de preparación, errores de obtención de imágenes, permisos insuficientes.
Requisitos previos
- Cuenta de AWS (cree si no tiene una)
- Un clúster de Kubernetes
Nota:también puede usar máquinas virtuales para crear un clúster si no desea probar las instancias EC2 de AWS.
Lo que haremos
- Cree una implementación de Kubenetes para NginX
Crear una implementación de Kubenetes para NginX
Para crear nuestra primera implementación, simplemente creemos un nuevo directorio para crear nuestro objeto/archivo de implementación. Use el siguiente comando para crear un nuevo directorio en su sistema
mkdir mi-primera-implementación
cd mi-primera-implementación/
Antes de continuar, verifique el estado del clúster.
Para comprobar los Nodos disponibles en el clúster y para comprobar la versión de el "kubectl " usa los siguientes comandos.
sudo kubectl versión
sudo kubectl obtener nodos

Una vez que tenga Nodos disponibles en su clúster, estará listo para crear su implementación.
Cree un archivo "my-first-deployment.yml" con el siguiente bloque de código
vim mi-primera-implementación.yml
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
labels:
app: nginx
spec:
replicas: 2
selector:
matchLabels:
app: nginx
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.7.9
ports:
- containerPort: 80 Aquí,
- apiVersion : APIVersion define el esquema versionado de esta representación de un objeto.
- amable :tipo de objeto que desea crear, como implementación, servicio, mapa de configuración y más.
- nombre : El nombre debe ser único dentro de un espacio de nombres.
- etiquetas : Mapa de claves y valores de cadena que se pueden usar para organizar y categorizar objetos
- especificación : Especificación del comportamiento deseado del Deployment.
- réplicas : Número de pods deseados.
- selector : selector de etiquetas para pods. Los ReplicaSets existentes cuyos pods sean seleccionados por esto serán los afectados por esta implementación. Debe coincidir con las etiquetas de la plantilla del pod.
Ahora está listo para crear su implementación usando los siguientes comandos.
sudo kubectl apply -f my-first-deployment.yml
sudo kubectl get deployments
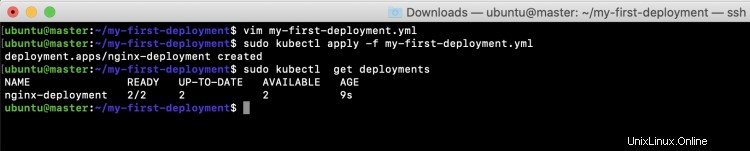
En la captura de pantalla anterior, puede ver que la implementación se creó con dos pods que están disponibles para usar.
Puedes obtener los detalles de los pods usando el siguiente comando.
sudo kubectl obtener pods
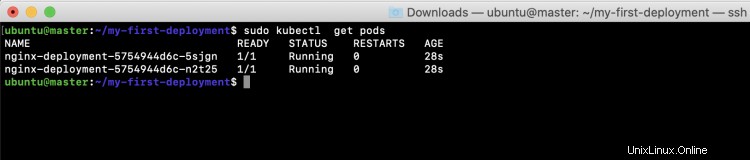
Si desea obtener más información sobre la implementación, puede usar este comando "kubectl describe" para obtener los detalles completos de la implementación.
sudo kubectl get deployments
sudo kubectl describe deployments nginx-deployment

Si ya no necesita la implementación, puede eliminarla usando el "comando de eliminación de kubectl".
sudo kubectl obtener implementaciones
sudo kubectl eliminar implementaciones nginx-deployment
sudo kubectl obtener implementaciones
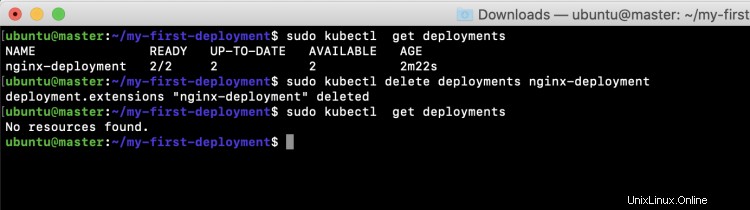
En la captura de pantalla anterior, puede ver que la implementación ya no está disponible después de que se elimine.
Una vez que elimine la implementación, los pods también se eliminarán.
Puede verificar la disponibilidad de los pods usando el siguiente comando.
sudo kubectl obtener pods

En la captura de pantalla anterior, puede ver que los pods se eliminaron después de eliminar la implementación y no están disponibles.
Conclusión
En este artículo, vimos los pasos para crear su primera implementación de NginX en Kubernetes. También vimos cómo se pueden extraer los detalles sobre el despliegue. Junto con esto, exploramos los comandos para eliminar la implementación.