La compresión es una técnica informática importante que utilizan los programas, los servicios y los usuarios para ahorrar espacio y mejorar la calidad del servicio. Por ejemplo, si descarga un juego a través de una plataforma de juegos, generalmente descarga una versión comprimida para que pueda ahorrar tiempo y espacio. La descompresión tiene lugar después de descargar el archivo o durante el proceso de instalación.
Pero, ¿por qué te cuento todo esto? Bueno, hoy repasaré la compresión de archivos de Linux y le mostraré todo lo que necesita saber.
Comprender la compresión
Antes de seguir adelante y aprender sobre la compresión de Linux, primero comprendamos más cosas sobre la compresión.
La compresión es una técnica para reducir el tamaño del archivo en un disco determinado utilizando diferentes cálculos y algoritmos matemáticos. El objetivo principal de la compresión es ahorrar espacio. Esto es posible en la forma en que se almacenan los archivos en las unidades de disco duro. Los algoritmos o cálculos matemáticos encuentran un patrón y comprimen esa parte para que pueda volver a generarlo con poca o ninguna pérdida de detalle. En resumen, el contenido repetido allana el camino para que funcione la compresión.
Hay dos tipos de compresión que debe conocer. Son compresión Lossy y Lossless.
Compresión sin pérdidas
Es una técnica de compresión que no pierde información y los datos reales se pueden recuperar del archivo comprimido. La compresión con pérdida es útil para reducir el tamaño del archivo sin perder la calidad del archivo original.
Compresión con pérdida
Por otro lado, existe una técnica de compresión con pérdida que comprime un archivo para ahorrar espacio, pero el archivo comprimido no se puede usar para recuperar el contenido del archivo original. En este caso, la información se pierde.
Para entender esto, veamos un ejemplo. Puede tomar una imagen sin procesar y luego comprimirla usando el modo con pérdida y sin pérdida. En la compresión sin pérdidas, el tamaño de la imagen disminuirá ligeramente y podrá conservar la imagen original si la descomprime. En la mayoría de los casos, se utiliza un formato PNG para la compresión sin pérdidas. Sin embargo, si usa la compresión con pérdida, obtendrá una salida de imagen que no se puede revertir a la original. En este caso, la imagen resultante es un formato JPEG/JPG.
Los algoritmos de compresión son excelentes a su manera y brindan valor al usuario. Los algoritmos más nuevos usan un método adaptativo donde son rápidos y más precisos en su técnica de compresión.
Diferentes formas de comprimir archivos en Linux
Para comprender la compresión en Linux, primero debemos crear un archivo para probar los métodos de compresión. Para hacerlo, podemos generar aleatoriamente un archivo usando el siguiente procedimiento.
base64 /dev/urandom | head -c 3000000 > mynewfile.txt
Para conocer el tamaño del archivo recién creado, puede ejecutar el siguiente comando.
ls -l --block-size=MB
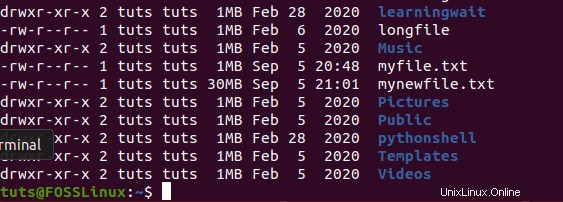
También puede verificar el tamaño del archivo utilizando el explorador de archivos y verificando el tamaño del archivo en sus propiedades.
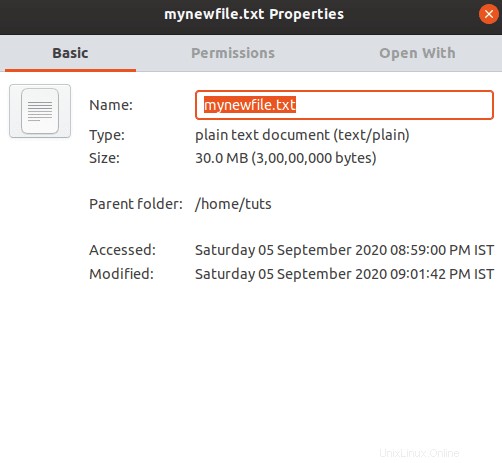
Vamos a crear varias copias del archivo para que podamos usarlo para probar técnicas de compresión.

El tamaño total de la carpeta en la que se almacenan los archivos es de 150 MB.
Compresión zip
Una de las técnicas de compresión estándar que encontrará en Linux es la técnica de compresión zip. Para ejecutar el comando zip en los archivos que tenemos, debe ejecutar el siguiente comando.
zip <output>.zip <input>
Entonces, para comprimir los cinco archivos que tenemos en la carpeta, debemos ejecutar el siguiente comando.
zip testing1.zip *
El comando tardará un tiempo en ejecutarse y lo verá frente a sus ojos.
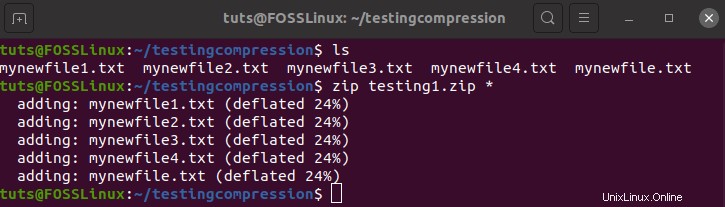
Como puede ver, cada uno de los archivos se redujo en un 24%. Con un ahorro del 24%, el tamaño final se sitúa en 114 MB. Eso es bastante bueno. El resultado habría sido diferente si hubiéramos utilizado archivos fuente adicionales. Una cosa más que habrás notado es que utiliza la técnica de compresión desinflada.
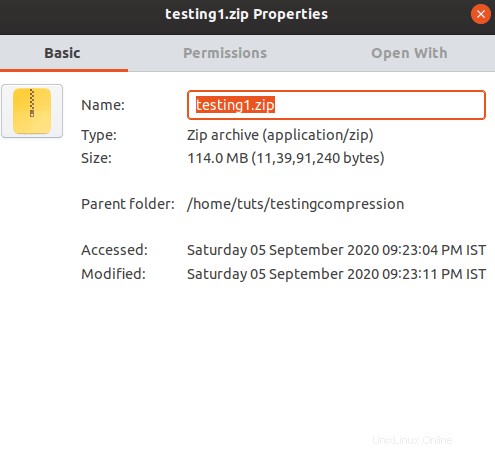
Para descomprimir el archivo, debe usar el siguiente comando.
descomprimir
Como puede ver, puede establecer un destino. También puede descomprimir en la misma carpeta simplemente usando el comando sin el parámetro de destino.
Compresión Gzip
Ahora que hemos pasado por la compresión zip, ahora es el momento de la compresión GNU Zip o gzip. También es un método popular para comprimir archivos en Linux. Jean-Loup Gailly y Mark Adler lo crean.
Además, es mejor que el método de compresión zip ya que ofrece una mejor compresión. La sintaxis para usar la compresión Gzip es la siguiente.
gzip <option> <input>
Para comprimir los archivos que tenemos, necesitamos usar el siguiente comando.
gzip -v mynewfile1.txt
Esto comprimirá el archivo, "mynewfile1.txt", y luego lo nombrará "mynewfile1.txt.gz".

El tamaño final del archivo es de 22,8 MB, que es una compresión bastante impresionante.
También puede comprimir toda la carpeta usando el indicador recursivo -r. La sintaxis es la siguiente:
gzip -r <folder_path>
También puede personalizar el nivel de compresión para Gzip. El valor del nivel de compresión se puede establecer de 1 a 9. 1 representa la compresión más rápida y mínima, mientras que nueve representa la compresión más lenta pero la mejor compresión.
gzip -v -9 mynewfile1.txt
Para descomprimir el archivo gzip, debe usar el siguiente comando.
gzip -d <gzip_file>
Compresión Bzip2
El último tipo de compresión que vamos a discutir es Bzip2. Es una herramienta gratuita y de código abierto. Utiliza el algoritmo de Burrows-Wheeler.
La técnica de compresión es bastante antigua, ya que se introdujo por primera vez en 1996. Puede utilizar Bzip2 en su trabajo diario. Es rápido y funciona de manera similar a la herramienta gzip. La sintaxis de la técnica de compresión Bzip2 es la siguiente:
bzip2 <option> <input>
Intentemos comprimir el archivo usando bzip2.

Al igual que gzip, también puede establecer la fuerza de la compresión de 1 a 9.
Para descomprimir el archivo, debe usar el siguiente comando.
bzip2 -d <filename>
Archivo
Hay otro término importante que debemos aprender aquí.
Archival es el método de realizar copias de seguridad de los datos en una ubicación segura utilizando un formato comprimido (generalmente). En el servidor Linux, encontrará la extensión de archivo tar que significa que es un archivo archivado. El formato tar es excelente a la hora de manipular y direccionar distintos archivos. Puede mantener intactos los metadatos y los permisos y, por lo tanto, se usa principalmente con fines de archivo en sistemas Linux.
La sintaxis del comando tar es la siguiente.
tar <option> <output_file> <input>
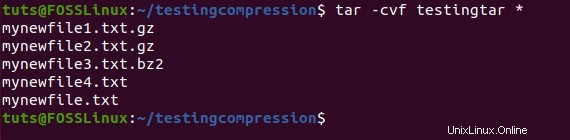
Para extraer, debe usar el siguiente comando.
tar -xvf <archieved-file-name>
Conclusión
Esto nos lleva al final de nuestra guía de compresión de Linux. Como puede ver, hay muchas formas de comprimir archivos. Además, el proceso de archivo tiene su uso único. Entonces, ¿qué opinas sobre la compresión de archivos de Linux? ¿Lo usas mucho? Háganos saber en los comentarios a continuación.