Si ha estado haciendo trabajo de administrador de sistemas durante el tiempo suficiente, ha visto los temidos incidentes "El servidor es lento". Durante mucho tiempo, este tipo de incidentes me daban un nudo en el estómago. ¿Cómo diablos solucionas algo tan subjetivo? La "lentitud" de un usuario cotidiano podría deberse a otros procesos (programados o no) que se ejecutan y consumen más recursos de lo habitual, o algo podría estar mal con el servidor.
Cuando comencé a trabajar como administrador de sistemas, respondía de inmediato:"Necesito más información sobre esto". Bueno, por lo general, el usuario no puede dar más información, porque no sabe lo que sucede detrás de escena o cómo explicar lo que está viendo, aparte de "es lento". Hoy en día, incluso antes de responder al usuario, reviso algunas cosas.
Inicio de sesión inicial
Hay muchas cosas que puede saber al iniciar sesión en el host. ¿Puedes iniciar sesión? ¿El inicio de sesión es lento o se cuelga? El ssh El comando tiene tres niveles de depuración, cada uno de los cuales le brinda una gran cantidad de información incluso antes de que esté en el sistema. Para habilitar la depuración, simplemente agregue un v adicional al -v opción. Por ejemplo, un debug de nivel tres, que es el que yo uso exclusivamente, sería:
[~]$ ssh -vvv hostname.domain.com
Los "Big 3" (también conocidos como CPU, RAM y E/S de disco)
Ahora, veamos las tres principales causas de la ralentización del servidor:CPU, RAM y E/S de disco. El uso de la CPU puede causar una lentitud general en el host y dificultad para completar las tareas de manera oportuna. Algunas herramientas que uso cuando miro la CPU son top y sar .
Comprobación del uso de CPU con top
El top La utilidad le brinda una vista en tiempo real de lo que está sucediendo con el servidor. Por defecto, cuando top comienza, muestra actividad para todas las CPU:

Esta vista se puede cambiar presionando la tecla numérica 1, que agrega más detalles sobre los valores de uso para cada CPU:
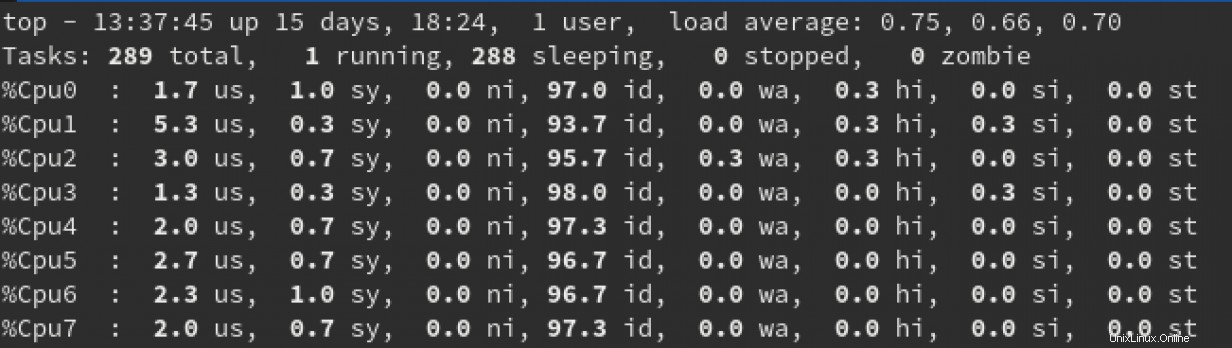
Algunas cosas para buscar en esta vista serían el promedio de carga (que se muestra en el lado derecho de la fila superior) y el valor de lo siguiente para cada CPU:
us:este porcentaje representa la cantidad de CPU consumida por los procesos de usuario.sy:este porcentaje representa la cantidad de CPU consumida por los procesos del sistema.id:este porcentaje representa cuán inactiva está cada CPU.
Cada uno de estos tres valores puede brindarle una idea bastante buena y en tiempo real de si las CPU están vinculadas a procesos de usuario o procesos del sistema.
Para explicar verdaderamente el promedio de carga necesitaría un artículo por sí solo. Para el propósito de este artículo, hablaré en generalidades. Los tres valores promedio de carga de izquierda a derecha representan promedios de un minuto, cinco minutos y 15 minutos. De nuevo, hablando muy en general, si ve que el promedio de un minuto supera la cantidad de CPU físicas que tiene, lo más probable es que el sistema esté limitado por la CPU.
Comprobando todos los "3 grandes" con sar
Para los datos históricos de rendimiento de la CPU, confío en el sar comando, que es proporcionado por sysstat paquete. En la mayoría de las versiones de servidor de Linux, sysstat está instalado de forma predeterminada, pero si no lo está, puede agregarlo con el administrador de paquetes de su distribución. El sar La utilidad recopila datos del sistema cada 10 minutos a través de un trabajo cron ubicado en /etc/cron.d/sysstat (CentOS 7.6). Aquí se explica cómo verificar todos los "3 grandes" usando sar .
sar para continuar con este artículo, déle al comando algo de tiempo para registrar datos primero.
El comando sar -u le brinda información sobre todas las CPU en el sistema, a partir de la medianoche:

Al igual que con top , lo principal que hay que comprobar aquí es %user , %system , %iowait y %idle . Esta información puede decirle cuánto tiempo hace que el servidor ha tenido problemas.
En general, el sar El comando puede proporcionar mucha información. Dado que este artículo explica solo una verificación rápida de lo que sucede en el servidor, consulte man sar para desglosar esta información aún más.
Para verificar el rendimiento de la RAM, uso sar -r , que le proporciona el uso de memoria de ese día:

Lo principal a buscar en el uso de RAM es %memused y %commit . Una palabra rápida sobre el %commit campo:este campo puede mostrarse por encima del 100 %, ya que el kernel de Linux asigna en exceso la memoria RAM de forma rutinaria. Si %commit está constantemente por encima del 100 %, este resultado podría ser un indicador de que el sistema necesita más RAM.
Para el rendimiento de E/S del disco, uso sar -d , que le brinda la salida de E/S del disco usando solo el nombre del dispositivo. Para obtener el nombre de los dispositivos, use sar -dP :

Para esta salida, mirando %util y %await le dará una buena imagen general de la E/S del disco en el sistema. El %util El campo se explica por sí mismo:es la utilización de ese dispositivo. El await El campo contiene la cantidad de tiempo que la E/S pasa en el planificador. La espera se mide en milisegundos y, en mi entorno, he visto que cualquier cosa mayor a 50 ms comienza a causar problemas. Ese umbral puede variar en su entorno.
Si alguno de estos comandos muestra un problema, puede volver para ver cuándo comenzaron los problemas del servidor usando sar {-u, -r, -d, -dP} -f /var/log/sa/sa<XX> (donde XX es el día del mes que desea buscar).
En este punto, generalmente tengo una buena idea de lo que está sucediendo actualmente en el servidor y lo que ha estado sucediendo durante las últimas 48 horas más o menos. Responderé al usuario con respuestas más informadas. Por ejemplo:"No veo ninguna indicación de lentitud del host en las últimas 24 horas. Intente usar un nuevo perfil Puty para ssh y avísame si sigues teniendo problemas".
Otro ejemplo:"No veo nada que esté causando problemas en este host, pero noté una carga de CPU más alta $time . ¿Fue entonces cuando viste problemas? Si es así, inténtalo ahora y avísame si sigues teniendo problemas".
Entiendes la idea. Tener la información proporcionada al mirar el inicio de sesión inicial y luego ejecutar algunos sar Los comandos, que generalmente me toman menos de 10 minutos para ejecutar, hacen mucho para evitar más preguntas y llegar a una resolución más rápido.