¡Abucheo! Halloween finalmente está aquí. ¿Ya tienes preparado tu disfraz de Halloween favorito? O tal vez sus hijos se estén preparando para pedir dulces. Es el año 2020, y esta pandemia de coronavirus es probablemente lo más aterrador, incluso más aterrador que los fantasmas y zombis que llaman a tu puerta.

Cuando eres un administrador de sistemas, puedes encontrarte con algunos momentos realmente aterradores que te ponen la piel de gallina y noches de insomnio, pero incluso el fantasma, zombi o monstruo más aterrador tiene un némesis del que huir, ya sea una cruz copta, un collar de ajo , un trozo de kryptonita o un administrador de sistemas experto. En este artículo, presentaré algunos posibles momentos de miedo para un administrador de sistemas como usted. También te diré cómo puedes manejarlos. Es Halloween, después de todo, así que piensa en esta lista como mi regalo de Halloween para ti.
También he proporcionado este blog en YouTube, le gustaría verlo en lugar de leer más.
Truco #1:Caída del servidor en la nube

Son las 2 a. m. y su teléfono inteligente comienza a zumbar. Medio despierto, tomas tu teléfono y miras la pantalla. Disparo. Su correo electrónico sigue recibiendo notificaciones generadas automáticamente desde el sistema de mensajes de Slack/Teams de que su servidor de producción ha estado inactivo durante dos o tres horas. Lo siguiente que sabes es que tu jefe quiere que tú y el resto del equipo de operaciones estén allí lo antes posible. Esta es definitivamente una situación en la que no quieres estar, entonces, ¿cómo puedes evitar que suceda?
[ También te puede interesar: Comandos Bash Bang:un truco imprescindible para la línea de comandos de Linux]
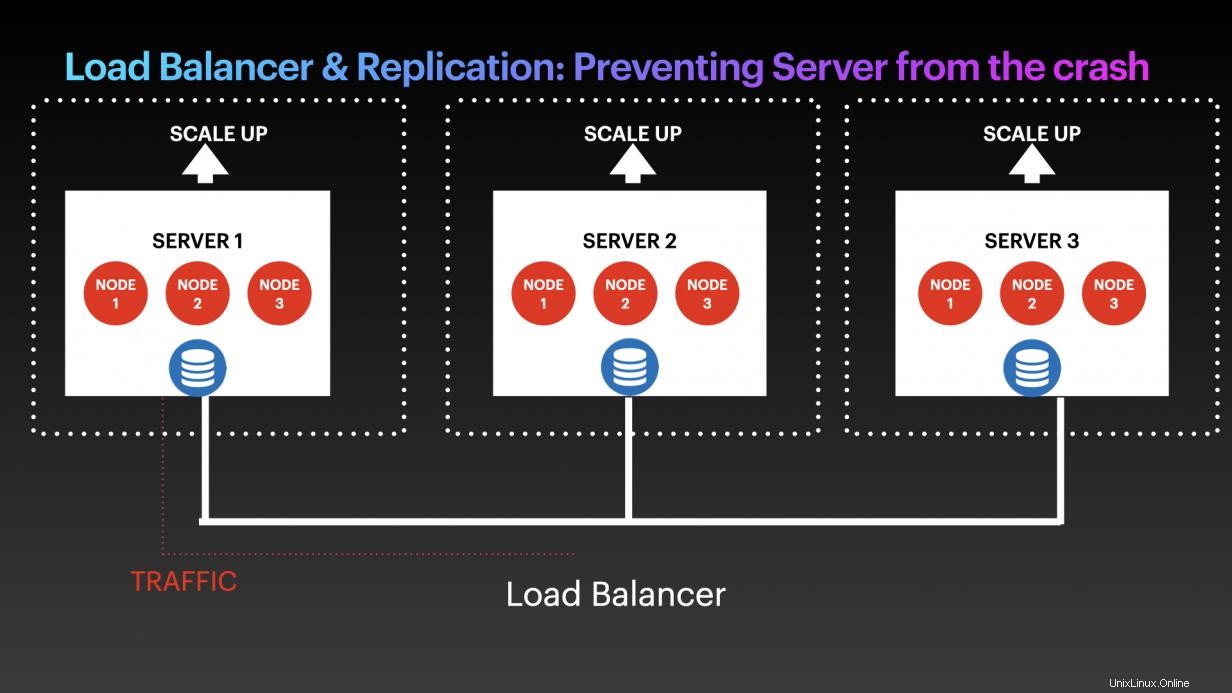
Trato n.º 1:Equilibrador de carga y replicación:prevención del bloqueo del servidor
Si bien es imposible evitar por completo que los servidores en ejecución se bloqueen, es posible crear un sistema casi tolerante a fallas si lo diseña de la manera correcta. Una solución es configurar la replicación en varios entornos con varios clústeres y varios nodos. Puede agregar un balanceador de carga para asegurarse de que otros clústeres continúen funcionando incluso si un clúster se apaga. Si hay demasiado tráfico u otros problemas de rendimiento, puede configurar la función de escalado automático para escalar verticalmente o horizontalmente.
Truco #2:Corrupción o pérdida de datos

Un nuevo pasante llamado Mike se unió a su equipo de ingeniería. Emocionado por haber obtenido las herramientas que necesita, ejecuta una consulta SQL sin intención de dañar nada. Pero oh-oh. Este pequeño cambio hace que se elimine la tabla de su base de datos y todos los datos críticos del cliente desaparecen. ¿Qué puedes hacer para evitar que ocurra un problema como este?
Trato n.º 2:copia de seguridad y restauración de datos:solucione la pérdida y corrupción de datos
La pérdida de datos es un problema grave para cualquier servicio o aplicación en vivo. Por lo tanto, la estrategia de copia de seguridad y restauración siempre debe estar disponible, al menos para el entorno de producción. Idealmente, el procedimiento de copia de seguridad y restauración debería estar disponible en todos los entornos. Además, cree un mecanismo para automatizar este proceso. La forma más sencilla de comenzar es crear algunos scripts bash para ejecutar una serie de comandos de copia de seguridad y restauración.

Truco n.º 3:bloqueo de la aplicación

¡Hurra! Su servidor y base de datos ahora son tolerantes a fallas y sólidos como una roca, pero una aplicación Java que expone puntos finales importantes para el negocio explota repentinamente. Cuando un cliente visita el sitio web, solo ve una página 404, lo que le cuesta a su empresa un millón de dólares por minuto.
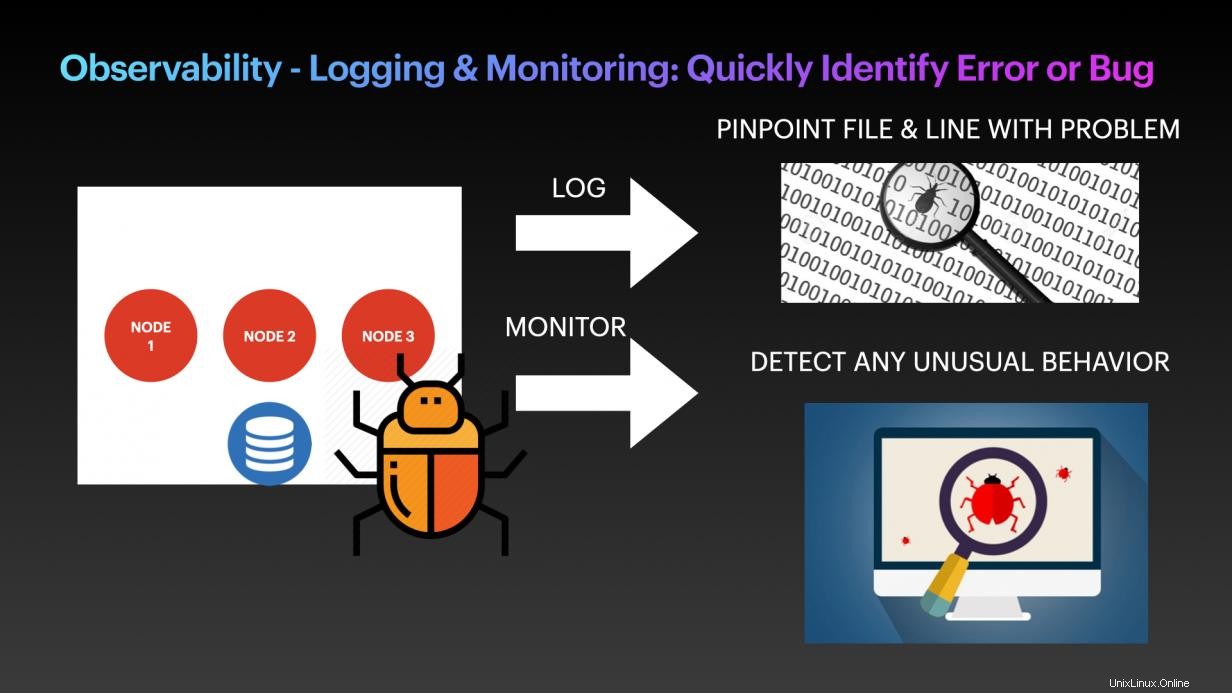
Trato n.º 3:Observabilidad:registro y supervisión:identificación rápida de errores o errores
Los errores de aplicación ocurren todo el tiempo, y hay muchas técnicas y patrones de diseño de programación, como el patrón de disyuntor, para manejar los problemas. Sin embargo, cualquier error que se ejecute dentro de la aplicación debe identificarse rápidamente antes de que pueda solucionarse. Por lo tanto, el registro y la supervisión son necesidades absolutas para todas las aplicaciones. Asegúrese de que su aplicación tenga puntos de depuración habilitados en todos los bloques y líneas de código. Estos errores o resultados deben enviarse a los paneles de monitoreo para que los desarrolladores puedan identificar rápidamente el problema.
Truco #4:Una aplicación lenta

Agregó registro y monitoreo para todas las aplicaciones. Finalmente puedes dormir feliz, soñando con cómo ganar la competencia virtual de disfraces de Halloween de este año. Sin embargo, unos minutos más tarde, lee un correo electrónico de un cliente que indica que el servicio de la aplicación realmente se siente lento.
Trato n.º 4:herramientas de desarrollo para la identificación de cuellos de botella:descubra dónde se produce la ralentización
Así como un desarrollador puede identificar el cuello de botella rápidamente con el monitoreo y el registro habilitados en todas las aplicaciones, puede usar herramientas de desarrollador como traceroute /tracert , Chrome browser Developer Tools y Wireshark para solucionar problemas de aplicaciones e identificar fácilmente dónde ocurren los problemas de rendimiento. Conocer herramientas como esta puede ayudar a un desarrollador a navegar los desafiantes problemas relacionados con las aplicaciones basadas en la nube.

Truco #5:latencia lenta reportada en una sola ubicación

Como usted es un maestro administrador de sistemas, finalmente encontró la causa de la lentitud general de la aplicación. Solucionaste el problema y el cliente luego te envía una carta de agradecimiento diciendo que todo está bien. Sin embargo, un día después, recibe un correo electrónico de otro cliente, ubicado en Sydney, Australia, quejándose de que la aplicación de su empresa se siente lenta cuando visita el sitio. ¿Qué está pasando?
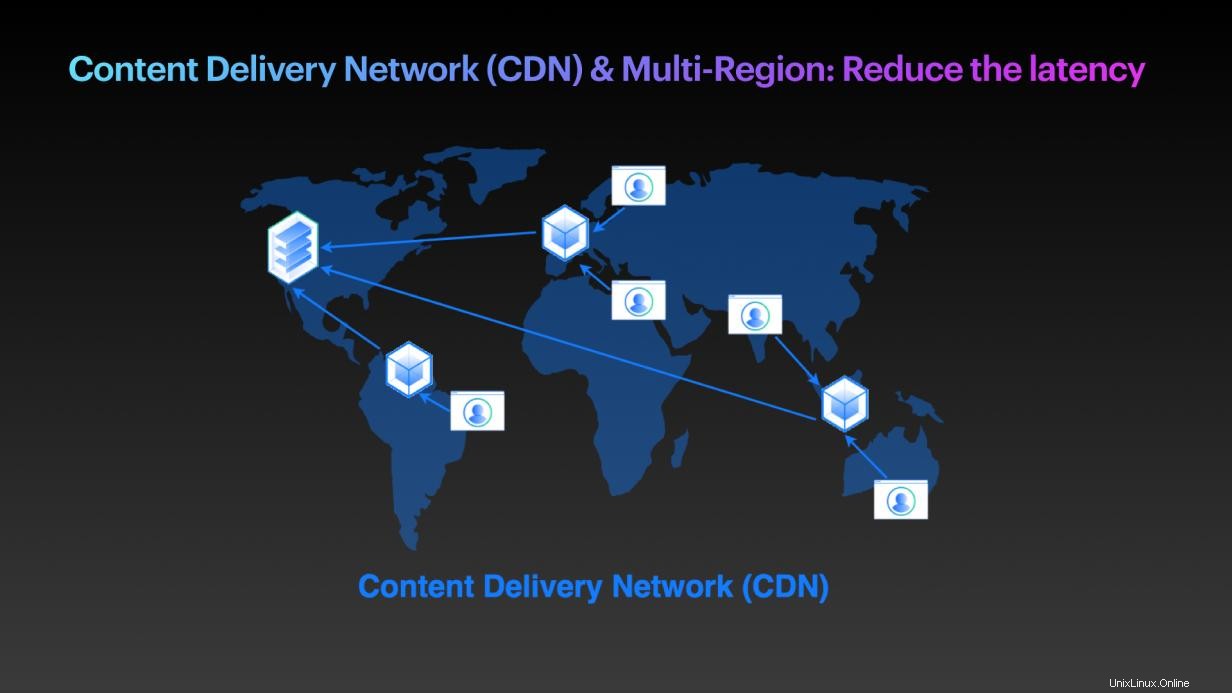
Trato n.º 5:red de entrega de contenido (CDN) y acceso multirregional:reduzca la latencia
Aunque el problema aún puede ser un problema de latencia debido al diseño de una aplicación, el problema podría deberse a la falta de disponibilidad del servidor para el cliente en esa ciudad o región. Una forma de resolver el problema es agregar una ubicación adicional para sus servicios en ejecución para que el servidor más cercano pueda seleccionarse automáticamente para entregar el contenido necesario al cliente. En otras palabras, un clúster de varias regiones y una red de entrega de contenido (CDN) pueden ayudar a mitigar el problema.
[ Descargar ahora:una guía para administradores de sistemas sobre secuencias de comandos Bash. ]
Resumir
¡Eso es todo amigos! Aprendió a resolver los cinco puntos débiles más comunes que puede encontrar como administrador de sistemas cuando tiene aplicaciones que se ejecutan en un servidor o en un entorno de nube. Problemas como estos ocurren todo el tiempo, pero hay formas de prevenir o mitigar los problemas de manera adecuada con la arquitectura adecuada y un buen enfoque de administrador de sistemas. Espero que este artículo le haya ayudado a convertirse en un mejor administrador de sistemas. ¡Feliz Halloween!