Un usuario experimentado de Linux sabe exactamente qué tipo de líneas en blanco molestas pueden ser en un archivo procesable. Estas líneas vacías/en blanco no solo interfieren en el procesamiento correcto de dichos archivos, sino que también dificultan que un programa en ejecución lea y escriba el archivo.
En un entorno de sistema operativo Linux, es posible implementar varias expresiones de manipulación de texto para deshacerse de estas líneas vacías/en blanco de un archivo. En este artículo, las líneas vacías/en blanco se refieren a los caracteres de espacio en blanco.
Crear un archivo con líneas vacías/en blanco en Linux
Necesitamos crear un archivo de referencia con algunas líneas vacías/en blanco. Más adelante lo modificaremos en el artículo a través de varias técnicas que discutiremos. Desde su terminal, cree un archivo de texto de su elección con un nombre como “i_have_blanks ” y rellénelo con algunos datos y algunos espacios en blanco.
$ nano i_have_blanks.txt Or $ vi i_have_blanks.txt
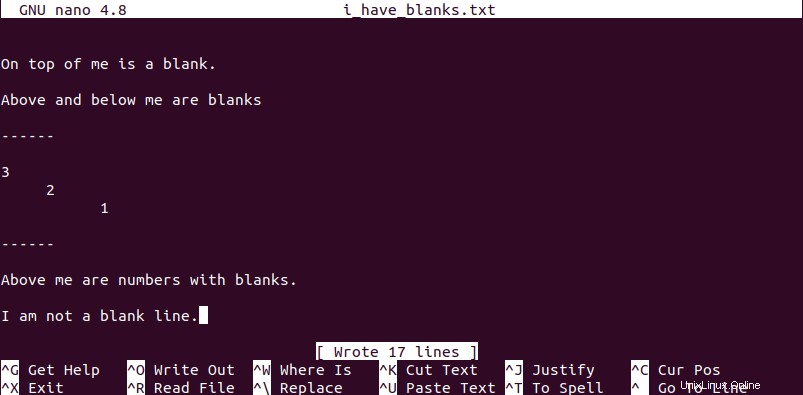
A lo largo del artículo, mostraremos el contenido de un archivo en nuestra terminal usando el comando cat para una referencia flexible.
$ cat i_have_blanks.txt

Los tres comandos de Linux que nos impulsarán hacia una solución ideal para este problema de líneas vacías/en blanco son grep, sed y awk. .
Por lo tanto, cree tres copias de su i_have_blanks.txt y guárdelos con diferentes nombres para que cada uno pueda ser acomodado por uno de los tres comandos de Linux indicados.
A través de regex (expresiones regulares ), podemos identificar líneas en blanco con el carácter estándar POSIX “[:space:]” .
Cómo eliminar líneas en blanco/vacías en archivos
Con esta declaración de problema, estamos considerando la eliminación de todas las líneas vacías/en blanco existentes de un archivo legible dado usando los siguientes comandos.
1. Eliminar líneas vacías usando el comando Grep
El uso admitido de clases de caracteres abreviados puede reducir el comando grep a uno simple como:
$ grep -v '^[[:space:]]*$' i_have_blanks.txt OR $ grep '\S' i_have_blanks.txt
Para corregir un archivo con líneas en blanco/vacías, la salida anterior debe pasar por un archivo temporal antes de sobrescribir el archivo original.
$ grep '\S' i_have_blanks.txt > tmp.txt $ mv tmp.txt i_have_blanks.txt $ cat i_have_blanks.txt

Como puede ver, todas las líneas en blanco que separaban el contenido de este archivo de texto desaparecieron.
2. Eliminar líneas vacías usando el comando Sed
El d La acción en el comando le dice que elimine cualquier espacio en blanco existente de un archivo. El mecanismo de coincidencia y eliminación de líneas en blanco de este comando se puede representar de la siguiente manera.
$ sed '/^[[:space:]]*$/d' i_have_blanks_too.txt
El comando anterior escanea las líneas del archivo de texto en busca de caracteres que no estén en blanco y elimina todos los demás caracteres restantes. A través de su compatibilidad con clases de caracteres que no están en blanco, el comando anterior se puede simplificar a lo siguiente:
$ sed '/\S/!d' i_have_blanks_too.txt
Además, debido al soporte de edición en el lugar del comando, no necesitamos un archivo temporal para almacenar temporalmente nuestro archivo convertido antes de sobrescribir el archivo de texto original como en el caso del comando grep. Sin embargo, debe usar este comando con un -i opción como argumento.
$ sed -i '/\S/!d' i_have_blanks_too.txt i_have_blanks_too.txt $ cat i_have_blanks_too.txt
3. Eliminar líneas vacías usando el comando Awk
El comando awk ejecuta una verificación de caracteres que no sean blancos en cada línea de un archivo y solo los imprime si esta condición es verdadera. La flexibilidad de este comando viene con varias rutas de implementación. Su sencilla solución es la siguiente:
$ awk '!/^[[:space:]]*$/' i_have_blanks_first.txt
La interpretación del comando anterior es sencilla, solo se imprimen las líneas de archivo que no existen como espacios en blanco. La versión más larga del comando anterior tendrá un aspecto similar al siguiente:
$ awk '{ if($0 !~ /^[[:space:]]*$/) }' i_have_blanks_first.txt
A través de awk soporte de clases de caracteres no en blanco, el comando anterior también se puede representar de la siguiente manera:
$ awk -d '/\S/' i_have_blanks_first.txt
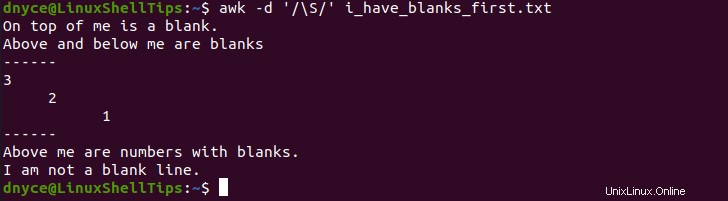
El -d una opción permite awk vuelque las líneas finales del archivo en la terminal del sistema. Como puede ver, el archivo ya no tiene espacios en blanco.
Los tres discutieron e implementaron soluciones para tratar con líneas en blanco de archivos a través de grep , sed y awk Los comandos nos ayudarán mucho a implementar operaciones de archivo de lectura y escritura estables y eficientes en un sistema Linux.