Consultando desde un MySQL el shell de la base de datos siempre es divertido y técnico hasta que necesita una salida de la base de datos guardada en algún lugar para facilitar el acceso y la referencia; especialmente cuando se trata de grandes conjuntos de datos.
El acceso rápido a los datos le evita tener que iniciar sesión cada vez en un servidor MySQL a través de un shell de terminal para hacer referencia a salidas específicas asociadas a consultas MySQL. El CSV (Valor separado por comas ) es un candidato ideal para resolver este tipo de interacciones repetitivas entre el usuario y la base de datos.
El formato de archivo de CSV se aplica mejor para guardar resultados de MySQL debido a sus atributos destacados que incluyen:
- Es un formato de almacenamiento de datos separados por comas ampliamente aceptado.
- Su ventaja adicional legible por humanos.
- Su fácil importación a cualquier aplicación debido a su naturaleza de texto sin formato.
- Su adaptabilidad en la gestión y organización de grandes conjuntos de datos.
Requisitos
- El archivo CSV que se asociará con el MySQL las salidas de consulta aún no deberían existir, ya que se generarán automáticamente durante la ejecución de una salida de consulta MySQL específica.
- Tener privilegios de root tanto en la base de datos MySQL como en el sistema Linux.
Creación de una tabla de base de datos de muestra con valores de varias filas
Para que este tutorial sea atractivo y se entienda mejor, es necesario que exista una tabla de base de datos con algunos valores. Para este tutorial, puede estar bajo MySQL o MariaDB RDBMS. Desde MariaDB es una bifurcación de código abierto de MySQL , estos dos RDBMS hacen referencia a la misma implementación de sus comandos de shell de base de datos.
Inicie sesión en su MySQL base de datos como usuario raíz de base de datos o con una credencial de usuario de base de datos existente.
$ sudo mysql -u root -p
Crearemos una nueva base de datos para alojar nuestra nueva tabla de base de datos.
MariaDB[(none)]> show databases; MariaDB[(none)]> create database lst_db; MariaDB[(none)]> use lst_db;
A continuación, cree la base de datos con algunas tablas como se muestra.
MariaDB[(none)]> CREATE TABLE lst_projects( project_id INT AUTO_INCREMENT, project_name VARCHAR(100) NOT NULL, project_category VARCHAR(100) NOT NULL, project_manager VARCHAR(100) NOT NULL, start_date DATE, end_date DATE, PRIMARY KEY(project_id) );
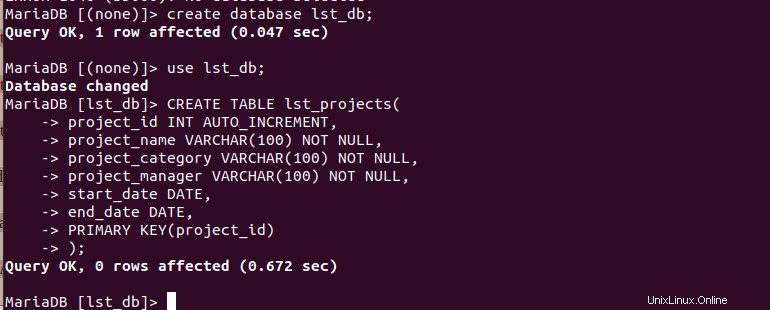
Rellenar tabla de base de datos MySQL con datos
Hemos verificado que nuestra tabla de base de datos MySQL creada existe. Es hora de llenarlo con algunos datos.
MariaDB[(none)]> show tables;
MariaDB[(none)]> INSERT INTO
lst_projects(project_name, project_category, project_manager, start_date, end_date)
VALUES
('Marketing','AI','David Guitar','2021-08-01','2021-12-31'),
('Copy writing','AI','Viola Guin','2022-01-01','2022-03-31'),
('Modeling','Robotics','Mary Atkins','2023-04-01','2023-07-31'),
('API','ML','Duncan Reeves','2024-02-01','2024-06-20'),
('Sales','ML','Anthony Luigi','2025-05-15','2025-11-20');
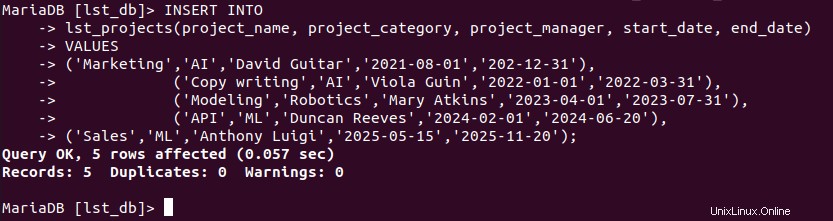
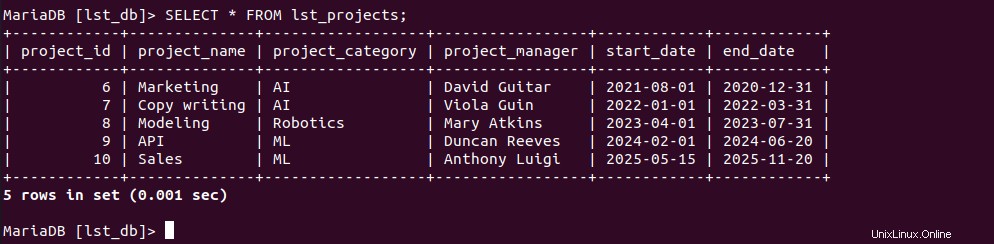
Confirmemos la existencia de nuestros lst_projects valores de la tabla.
MariaDB[(none)]> SELECT * FROM lst_projects;
Exportación de resultados de consultas de MySQL a formato CSV
El directorio temporal “/var/tmp” le da a MySQL los privilegios de lectura y escritura necesarios. Lo usaremos para alojar todos los archivos CSV generados automáticamente a partir de consultas de MySQL.
Varias condiciones determinan cómo exportamos el resultado de una consulta MySQL a un formato de archivo CSV.
Exportar todas las consultas de MySQL a CSV
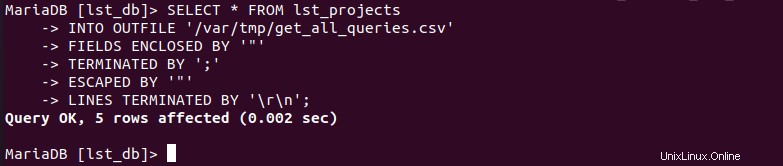
Para exportar esta consulta de base de datos “SELECT * FROM lst_projects; ” en un archivo CSV, lo implementaríamos de la siguiente manera:
MariaDB[(none)]> SELECT * FROM lst_projects INTO OUTFILE '/var/tmp/get_all_queries.csv' FIELDS ENCLOSED BY '"' TERMINATED BY ';' ESCAPED BY '"' LINES TERMINATED BY '\r\n';
Intentemos recuperar el archivo generado:
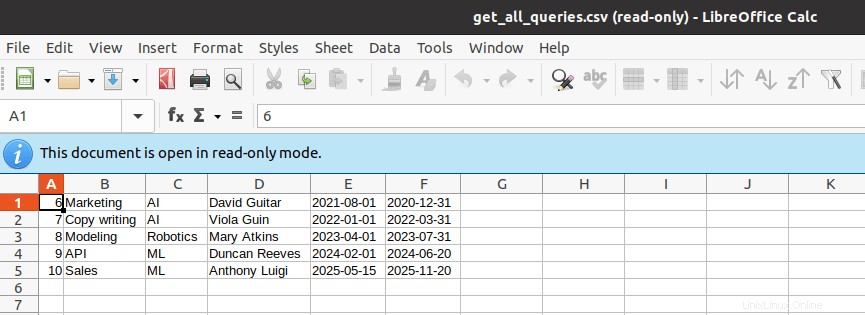
Exportar tablas de MySQL a CSV con encabezados
Este enfoque le da a su archivo CSV generado una apariencia profesional.
MariaDB[(none)]> (SELECT 'Project Name','Project Category','Project Manager','Start Date','End Date') UNION (SELECT project_name,project_category, project_manager, start_date, end_date FROM lst_projects INTO OUTFILE '/var/tmp/included_column_headings.csv' FIELDS ENCLOSED BY '"' TERMINATED BY ';' ESCAPED BY '"' LINES TERMINATED BY '\r\n');
Recuperemos nuevamente el archivo generado:
Como se señaló, la exportación de CSV de consulta de MySQL ahora está bien organizada con encabezados de columna.
Tratar con valores nulos en consultas MySQL exportadas
Agreguemos una columna que acepte Null valores a nuestra tabla de base de datos lst_projects .
MariaDB[(none)]> ALTER TABLE lst_projects ADD COLUMN project_status VARCHAR(15) AFTER end_date;
No insertaremos ningún valor en esta nueva columna para garantizar que permanezca vacía. Exportaciones de consultas MySQL con Null los valores están pregrabados con “"N” en el archivo CSV generado. Para solucionar este problema, podemos reemplazar el “"N” valor con algo más identificable como “N/A” .
MariaDB[(none)]> (SELECT 'Project Name','Start Date','End Date','Project Status')
UNION
(SELECT
project_name, start_date, end_date, IFNULL(project_status, 'N/A')
FROM
lst_projects INTO OUTFILE '/var/tmp/with_null.csv'
FIELDS ENCLOSED BY '"'
TERMINATED BY ';'
ESCAPED BY '"' LINES
TERMINATED BY '\r\n');
Revisemos el archivo CSV generado.
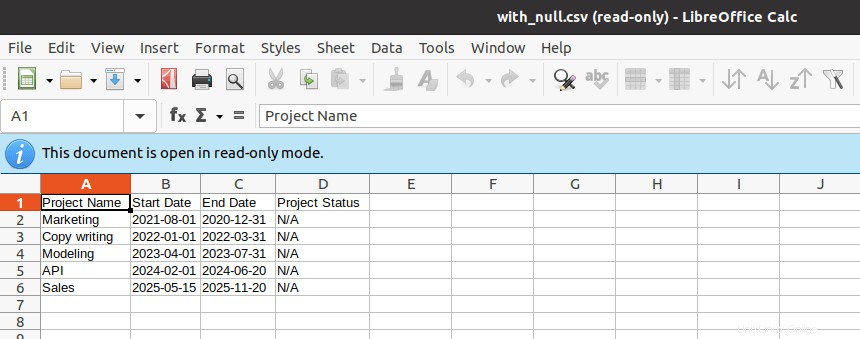
Exportar tablas de MySQL a CSV con nombre de archivo de marca de tiempo
Crea una rutina de administración más precisa en términos de cuándo se generaron sus archivos CSV.
MariaDB[(none)]> SET @TS = DATE_FORMAT(NOW(),'_%Y_%m_%d_%H_%i_%s');
SET @FOLDER = '/var/tmp/';
SET @PREFIX = 'lst_projects';
SET @EXT = '.csv';
SET @CMD = CONCAT("SELECT * FROM lst_projects INTO OUTFILE '",@FOLDER,@PREFIX,@TS,@EXT,
"' FIELDS ENCLOSED BY '\"' TERMINATED BY ';' ESCAPED BY '\"'",
" LINES TERMINATED BY '\r\n';");
PREPARE statement FROM @CMD;
EXECUTE statement;
El nombre del archivo CSV generado ahora debería tener una marca de tiempo.
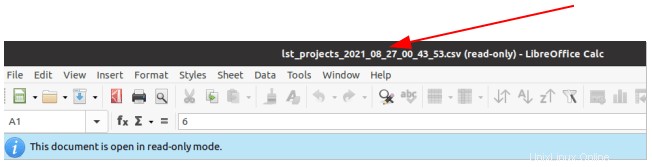
Salida de su MySQL consultar los resultados a un archivo CSV es una forma eficiente de administrar grandes conjuntos de datos, ya que le ahorra tiempo y dinero, especialmente cuando administra datos para grandes organizaciones.