El trabajo principal de un robot web es rastrear o escanear sitios web y páginas en busca de información; trabajan incansablemente para recopilar datos para motores de búsqueda y otras aplicaciones. Para algunos, existe una buena razón para mantener las páginas alejadas de los motores de búsqueda. Ya sea que desee ajustar el acceso a su sitio o desee trabajar en un sitio de desarrollo sin aparecer en los resultados de Google, una vez implementado, el archivo robots.txt permite que los rastreadores web y los bots sepan qué información pueden recopilar.
¿Qué es un archivo Robots.txt?
Un archivo robots.txt es un archivo de sitio web de texto sin formato en la raíz de su sitio que sigue el Estándar de exclusión de robots. Por ejemplo, www.sudominio.com tendría un archivo robots.txt en www.sudominio.com/robots.txt. El archivo consta de una o más reglas que permiten o bloquean el acceso a los rastreadores, restringiéndolos a una ruta de archivo específica en el sitio web. De forma predeterminada, todos los archivos están totalmente permitidos para el rastreo, a menos que se especifique lo contrario.
El archivo robots.txt es uno de los primeros aspectos analizados por los rastreadores. Es importante tener en cuenta que su sitio solo puede tener un archivo robots.txt. El archivo se implementa en una o varias páginas o en un sitio completo para evitar que los motores de búsqueda muestren detalles sobre su sitio web.
Este artículo proporcionará cinco pasos para crear un archivo robots.txt y la sintaxis necesaria para mantener a raya a los bots.
Cómo configurar un archivo Robots.txt
1. Crear un archivo Robots.txt
Debe tener acceso a la raíz de su dominio. Su proveedor de alojamiento web puede ayudarlo a determinar si tiene o no el acceso adecuado.
La parte más importante del archivo es su creación y ubicación. Use cualquier editor de texto para crear un archivo robots.txt y se puede encontrar en:
- La raíz de su dominio:www.sudominio.com/robots.txt.
- Sus subdominios:página.sudominio.com/robots.txt.
- Puertos no estándar:www.sudominio.com:881/robots.txt.
Finalmente, deberá asegurarse de que su archivo robots.txt sea un archivo de texto codificado en UTF-8. Google y otros motores de búsqueda y rastreadores populares pueden ignorar los caracteres fuera del rango UTF-8, lo que posiblemente haga que sus reglas de robots.txt no sean válidas.
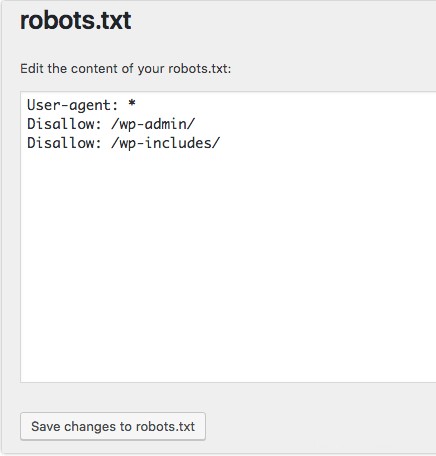
2. Configure su agente de usuario de Robots.txt
El siguiente paso para crear archivos robots.txt es configurar el agente de usuario . El agente de usuario se refiere a los rastreadores web o motores de búsqueda que desea permitir o bloquear. Varias entidades podrían ser el agente de usuario . A continuación, enumeramos algunos rastreadores, así como sus asociaciones.
Hay tres formas diferentes de establecer un usuario-agente dentro de su archivo robots.txt.
Creación de un agente de usuario
La sintaxis que utiliza para configurar el agente de usuario es User-agent:NameOfBot . A continuación, DuckDuckBot es el único agente de usuario establecido.
# Example of how to set user-agent
User-agent: DuckDuckBotCreación de más de un agente de usuario
Si tenemos que agregar más de uno, siga el mismo proceso que siguió para el user-agent de DuckDuckBot. en una línea posterior, ingresando el nombre del agente de usuario adicional . En este ejemplo, usamos Facebot.
#Example of how to set more than one user-agent
User-agent: DuckDuckBot
User-agent: FacebotConfiguración de todos los rastreadores como agente de usuario
Para bloquear todos los bots o rastreadores, sustituya el nombre del bot por un asterisco (*).
#Example of how to set all crawlers as user-agent
User-agent: *3. Establezca reglas para su archivo Robots.txt
Un archivo robots.txt se lee en grupos. Un grupo especificará quién es el agente de usuario es y tener una regla o directiva para indicar qué archivos o directorios el user-agent puede o no puede acceder.
Estas son las directivas utilizadas:
- Rechazar :la directiva que se refiere a una página o directorio relativo a su dominio raíz que no desea que el agente de usuario nombrado gatear Comenzará con una barra inclinada (/) seguida de la URL de la página completa. Lo terminará con una barra diagonal solo si se refiere a un directorio y no a una página completa. Puede usar uno o más disallow configuración por regla.
- Permitir :la directiva se refiere a una página o directorio relativo a su dominio raíz que desea que se llame user-agent gatear Por ejemplo, usaría permitir directiva para anular disallow regla. También comenzará con una barra inclinada (/) seguida de la URL de la página completa. Lo terminará con una barra diagonal solo si se refiere a un directorio y no a una página completa. Puede usar uno o más permitir configuración por regla.
- Mapa del sitio :La directiva del mapa del sitio es opcional y proporciona la ubicación del mapa del sitio para el sitio web. La única estipulación es que debe ser una URL completamente calificada. Puede usar cero o más, dependiendo de lo que sea necesario.
Los rastreadores web procesan los grupos de arriba a abajo. Como se mencionó anteriormente, acceden a cualquier página o directorio que no esté configurado explícitamente para no permitir . Por lo tanto, agregue Disallow:/ debajo del agente de usuario información en cada grupo para impedir que esos agentes de usuario específicos rastreen su sitio web.
# Example of how to block DuckDuckBot
User-agent: DuckDuckBot
Disallow: /
#Example of how to block more than one user-agent
User-agent: DuckDuckBot
User-agent: Facebot
Disallow: /
#Example of how to block all crawlers
User-agent: *
Disallow: /Para bloquear un subdominio específico de todos los rastreadores, agregue una barra diagonal y la URL completa del subdominio en su regla de rechazo.
# Example
User-agent: *
Disallow: /https://page.yourdomain.com/robots.txtSi desea bloquear un directorio, siga el mismo proceso agregando una barra diagonal y el nombre de su directorio, pero luego termine con otra barra diagonal.
# Example
User-agent: *
Disallow: /images/Finalmente, si desea que todos los motores de búsqueda recopilen información en todas las páginas de su sitio, puede crear un permitir o no permitir regla, pero asegúrese de agregar una barra inclinada cuando use la regla permitir regla. A continuación se muestran ejemplos de ambas reglas.
# Allow example to allow all crawlers
User-agent: *
Allow: /
# Disallow example to allow all crawlers
User-agent: *
Disallow:4. Cargue su archivo Robots.txt
Los sitios web no vienen automáticamente con un archivo robots.txt, ya que no es obligatorio. Una vez que decida crear uno, cargue el archivo en el directorio raíz de su sitio web. La carga depende de la estructura de archivos de su sitio y de su entorno de alojamiento web. Comuníquese con su proveedor de alojamiento para obtener ayuda sobre cómo cargar su archivo robots.txt.
5. Verifique que su archivo Robots.txt funcione correctamente
Hay varias formas de probar y asegurarse de que su archivo robots.txt funcione correctamente. Con cualquiera de estos, puede ver cualquier error en su sintaxis o lógica. Estos son algunos de ellos:
- Probador de robots.txt de Google en su consola de búsqueda.
- El validador de robots.txt y la herramienta de prueba de Merkle, Inc.
- Herramienta de prueba de robots.txt de Ryte.
Bonificación:Uso de Robots.txt en WordPress
Si usa WordPress, el complemento Yoast SEO, verá una sección dentro de la ventana de administración para crear un archivo robots.txt.
Inicie sesión en el backend de su sitio web de WordPress y acceda a Herramientas bajo el SEO y luego haga clic en Editor de archivos .
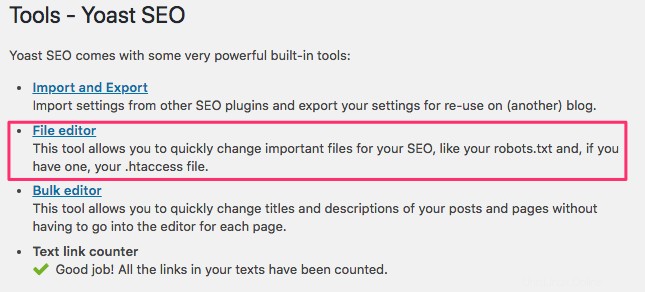
Siga la misma secuencia que antes para establecer sus reglas y agentes de usuario. A continuación, hemos bloqueado los rastreadores web de los directorios wp-admin y wp-includes de WordPress, al mismo tiempo que permitimos que los usuarios y los bots vean otras páginas del sitio. Cuando haya terminado, haga clic en Guardar cambios en robots.txt para activar el archivo robots.txt.