Para un administrador de sistemas, es muy común realizar redirección de entrada o salida durante su trabajo diario.
La redirección de entrada y salida es una herramienta muy poderosa que le permite conectar varios comandos y sintetizar la salida de varios comandos.
Redireccionamiento de entrada/salida es un concepto central de los sistemas basados en Unix, y se puede utilizar como una forma de aumentar la productividad del programador tremendamente.
Sin embargo, la redirección de entrada y salida es un tema amplio y hay algunos conceptos básicos que debe comprender si desea ser productivo.
Con este tutorial, vas a entender todo que hay que saber sobre la redirección de entrada y salida en sistemas Linux.
Reflexionaremos sobre el diseño del kernel de Linux en los archivos, así como la forma en que funcionan los procesos para tener una comprensión profunda y completa de lo que es la redirección de entrada y salida.
Se proporcionarán algunos ejemplos a lo largo del camino para asegurarse de que el conocimiento teórico se vincule con los ejercicios prácticos.
¿Listo?
Lo que aprenderás
Si sigue este tutorial hasta el final, aprenderá los siguientes conceptos.
- ¿Qué descriptores de archivo son y cómo se relacionan con entradas y salidas estándar;
- Cómo verificar entradas y salidas estándar para un proceso dado en Linux;
- Cómo redirigir entradas y salidas estándar en Linux;
- Cómo usar canalizaciones para encadenar entradas y salidas para comandos largos;
Ese es un programa bastante largo, sin más preámbulos, echemos un vistazo a qué son los descriptores de archivos y cómo el kernel de Linux conceptualiza los archivos.
1 – ¿Qué son los procesos de Linux?
Antes de comprender la entrada y la salida en un sistema Linux, es muy importante tener algunos conceptos básicos sobre qué son los procesos de Linux y cómo interactúan con su hardware.
Si solo está interesado en las líneas de comando de redirección de entrada y salida, puede pasar a las siguientes secciones. Esta sección es para administradores de sistemas que deseen profundizar en el tema.
a – ¿Cómo se crean los procesos de Linux?
Probablemente ya lo hayas escuchado antes, ya que es un adagio bastante popular, pero en Linux todo es un archivo .
Significa que los procesos, dispositivos, teclados, discos duros se representan como archivos que viven en el sistema de archivos.
El kernel de Linux puede diferenciar esos archivos asignándoles un tipo de archivo (un archivo, un directorio, un enlace suave o un socket, por ejemplo) pero el Kernel los almacena en la misma estructura de datos.
Como probablemente ya sepa, los procesos de Linux se crean como bifurcaciones de procesos existentes, que pueden ser el proceso init o el proceso systemd en distribuciones más recientes.
Al crear un nuevo proceso, el Kernel de Linux bifurcará un proceso padre y duplicará una estructura que es la siguiente.
b – ¿Cómo se almacenan los archivos en Linux?
Creo que un diagrama vale más que cien palabras, así que así es como se almacenan conceptualmente los archivos en un sistema Linux.

Como puede ver, por cada proceso creado, una nueva task_struct se crea en su host Linux.
Esta estructura contiene dos referencias, una para los metadatos del sistema de archivos (llamada fs ) donde puede encontrar información como, por ejemplo, la máscara del sistema de archivos.
El otro es una estructura para archivos que contiene lo que llamamos descriptores de archivo. .
También contiene metadatos sobre los archivos utilizados por el proceso, pero nos centraremos en los descriptores de archivos para este capítulo.
En informática, los descriptores de archivos son referencias a otros archivos que actualmente utiliza el propio núcleo.
Pero, ¿qué representan esos archivos?
c – ¿Cómo se usan los descriptores de archivo en Linux?
Como probablemente ya sepa, el núcleo actúa como un interfaz entre sus dispositivos de hardware (una pantalla, un mouse, un CD-ROM o un teclado).
Significa que su Kernel puede entender que desea transferir algunos archivos entre discos, o que puede querer crear un nuevo video en su disco secundario, por ejemplo.
Como consecuencia, el kernel de Linux está moviendo datos de forma permanente desde los dispositivos de entrada (un teclado, por ejemplo) a los dispositivos de salida (un disco duro, por ejemplo).
Usando esta abstracción, los procesos son esencialmente una forma de manipular entradas (como leer operaciones) para generar varios resultados (como escribir operaciones)
Pero, ¿cómo saben los procesos a dónde deben enviarse los datos?
Los procesos saben a dónde deben enviarse los datos mediante descriptores de archivos.
En Linux, el descriptor de archivo 0 (o fd[0]) se asigna a la entrada estándar.
Del mismo modo el descriptor de archivo 1 (o fd[1]) se asigna a la salida estándar y el descriptor de archivo 2 (o fd[2]) se asigna al error estándar.
Es una constante en un sistema Linux, para cada proceso, los primeros tres descriptores de archivo están reservados para entradas, salidas y errores estándar.
Esos descriptores de archivos están asignados a dispositivos en su sistema Linux.
Dispositivos registrados cuando se instancia el kernel, se pueden ver en /dev directorio de su host.
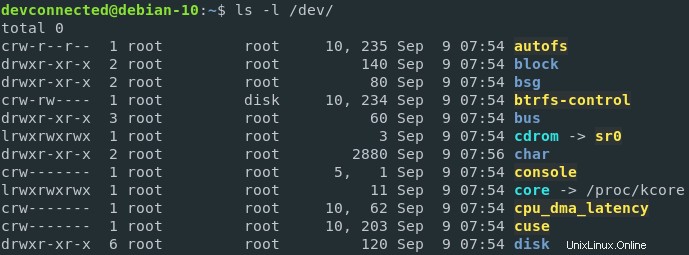
Si tuviera que echar un vistazo a los descriptores de archivo de un proceso dado, digamos un proceso bash, por ejemplo, puede ver que los descriptores de archivo son esencialmente enlaces suaves a dispositivos de hardware reales en su host.
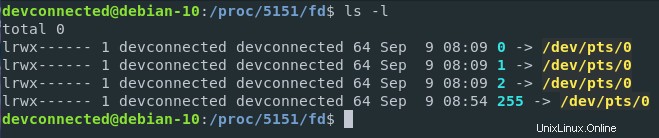
Como puede ver, al aislar los descriptores de archivo de mi proceso bash (que tiene el PID 5151 en mi host), puedo ver los dispositivos que interactúan con mi proceso (o los archivos abiertos por el kernel para mi proceso).
En este caso, /dev/pts/0 representa una terminal que es un dispositivo virtual (o tty) en mi sistema de archivos virtual. En términos más simples, significa que mi instancia de bash (que se ejecuta en una interfaz de terminal de Gnome) espera las entradas de mi teclado, las imprime en la pantalla y las ejecuta cuando se le solicita.
Ahora que tiene una comprensión más clara de los descriptores de archivos y cómo los utilizan los procesos, estamos listos para describir cómo hacer la redirección de entrada y salida en Linux .
2 – ¿Qué es la redirección de salida en Linux?
La redirección de entrada y salida es una técnica utilizada para redireccionar/cambiar entradas y salidas estándar, cambiando esencialmente desde dónde se leen los datos o dónde se escriben los datos.
Por ejemplo, si ejecuto un comando en mi shell de Linux, la salida podría imprimirse directamente en mi terminal (un comando cat, por ejemplo).
Sin embargo, con la redirección de salida, podría optar por almacenar la salida de mi comando cat en un archivo para almacenamiento a largo plazo.
a – ¿Cómo funciona la redirección de salida?
La redirección de salida es el acto de redirigir la salida de un proceso a un lugar elegido, como archivos, bases de datos, terminales o cualquier dispositivo (o dispositivo virtual) en el que se pueda escribir.
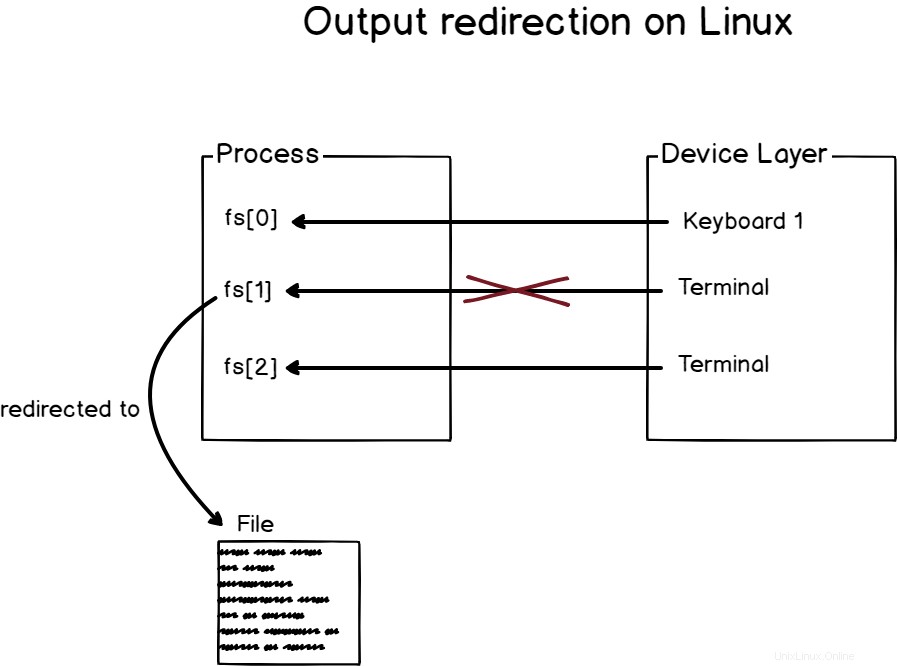
Como ejemplo, echemos un vistazo al comando echo.
De forma predeterminada, la función de eco tomará un parámetro de cadena y lo imprimirá en el dispositivo de salida predeterminado.
Como consecuencia, si ejecuta la función de eco en una terminal, la salida se imprimirá en la propia terminal.

Ahora digamos que quiero que la cadena se imprima en un archivo, para almacenamiento a largo plazo.
Para redirigir la salida estándar en Linux, debe usar el operador ">".
Como ejemplo, para redirigir la salida estándar de la función de eco a un archivo, debe ejecutar
$ echo devconnected > fileSi el archivo no existe, se creará.
A continuación, puede echar un vistazo al contenido del archivo y ver que la cadena "devconnected" se imprimió correctamente en él.

Alternativamente, es posible redirigir la salida usando el “1> ” sintaxis.
$ echo test 1> file
b – Redirección de salida a archivos de forma no destructiva
Al redirigir la salida estándar a un archivo, probablemente notó que borra el contenido existente del archivo.
A veces, puede ser bastante problemático, ya que desearía mantener el contenido existente del archivo y simplemente agregar algunos cambios al final del archivo.
Para agregar contenido a un archivo usando la redirección de salida, use el operador ">>" en lugar del operador ">".
Dado el ejemplo que acabamos de usar antes, agreguemos una segunda línea a nuestro archivo existente.
$ echo a second line >> file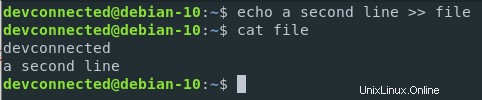
¡Genial!
Como puede ver, el contenido se agregó al archivo, en lugar de sobrescribirlo por completo.
c – errores de redirección de salida
Cuando se trata de la redirección de salida, es posible que tenga la tentación de ejecutar un comando en un archivo solo para redirigir la salida al mismo archivo.
Redireccionando al mismo archivo
echo 'This a cool butterfly' > file
sed 's/butterfly/parrot/g' file > file¿Qué espera ver en el archivo de prueba?
El resultado es que el archivo está completamente vacío.

¿Por qué?
De forma predeterminada, al analizar su comando, el kernel no ejecutará los comandos secuencialmente.
Significa que no esperará al final del comando sed para abrir su nuevo archivo y escribir el contenido en él.
En cambio, el núcleo abrirá su archivo, borrará todo el contenido que contiene y esperará a que se procese el resultado de su operación sed.
Como la operación sed está viendo un archivo vacío (porque la operación de redirección de salida borró todo el contenido), el contenido está vacío.
Como consecuencia, no se agrega nada al archivo y el contenido está completamente vacío.
Para redirigir la salida al mismo archivo, es posible que desee utilizar tuberías o comandos más avanzados como
command … input_file > temp_file && mv temp_file input_fileProteger un archivo para que no se sobrescriba
En Linux, es posible proteger los archivos para que no sean sobrescritos por el operador ">".
Puede proteger sus archivos configurando el parámetro "noclobber" en el entorno de shell actual.
$ set -o noclobberTambién es posible restringir la redirección de salida corriendo
$ set -CNota :para volver a habilitar la redirección de salida, simplemente ejecute set +C
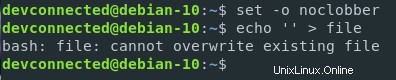
Como puede ver, el archivo no se puede anular al configurar este parámetro.
Si realmente quiero forzar la anulación, puedo usar el comando “>| ” para forzarlo.

3:¿Qué es la redirección de entrada en Linux?
a – ¿Cómo funciona la redirección de entrada?
La redirección de entrada es el acto de redirigir la entrada de un proceso a un dispositivo determinado (o dispositivo virtual) para que comience a leer desde este dispositivo y no desde el predeterminado asignado por el Kernel.
Como ejemplo, cuando está abriendo una terminal, está interactuando con ella con su teclado.
Sin embargo, hay algunos casos en los que es posible que desee trabajar con el contenido de un archivo, porque desea enviar mediante programación el contenido del archivo a su comando.
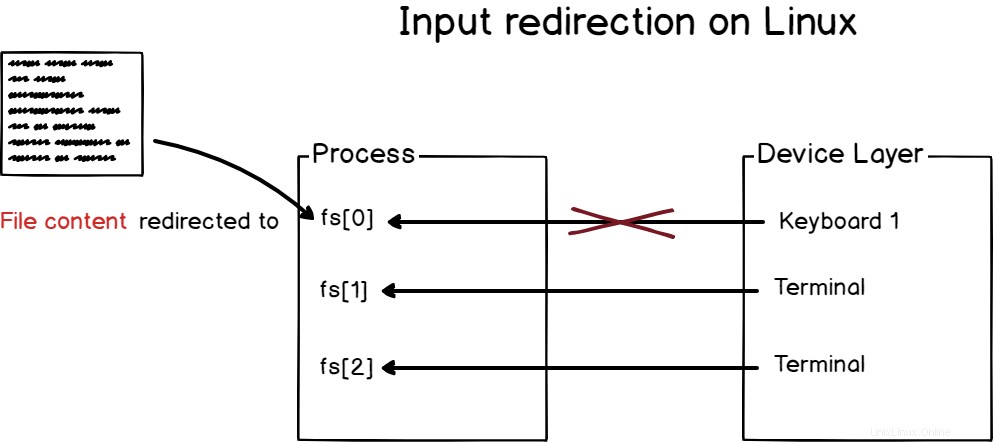
Para redirigir la entrada estándar en Linux, debe usar el operador "<".
Como ejemplo, supongamos que desea utilizar el contenido de un archivo y ejecutar un comando especial en él.
En este caso, usaré un archivo que contiene dominios y el comando será un comando de clasificación simple.
De esta forma, los dominios se ordenarán alfabéticamente.
Con la redirección de entrada, puedo ejecutar el siguiente comando
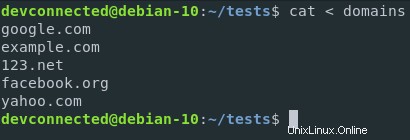
Si quiero ordenar esos dominios, puedo redirigir el contenido del archivo de dominios a la entrada estándar de la función de ordenación.
$ sort < domains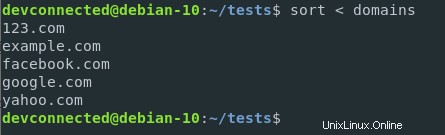
Con esta sintaxis, el contenido del archivo de dominios se redirige a la entrada de la función de clasificación. Es bastante diferente de la siguiente sintaxis
$ sort domainsIncluso si la salida puede ser la misma, en este caso, la función de clasificación toma un archivo como parámetro.
En el ejemplo de redirección de entrada, la función de clasificación se llama sin parámetro.
Como consecuencia, cuando no se proporcionan parámetros de archivo a la función, la función los lee de la entrada estándar de forma predeterminada.
En este caso, está leyendo el contenido del archivo proporcionado.
b – Redirigir la entrada estándar con un archivo que contiene varias líneas
Si su archivo contiene varias líneas, aún puede redirigir la entrada estándar de su comando para cada línea de su archivo.
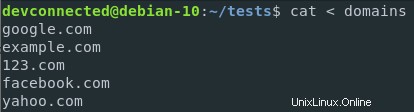
Digamos, por ejemplo, que desea tener una solicitud de ping para cada entrada en el archivo de dominios.
De forma predeterminada, el comando ping espera que se haga ping a una sola IP o URL.
Sin embargo, puede redireccionar el contenido de su archivo de dominios a una función personalizada que ejecutará una función de ping para cada entrada.
$ ( while read ip; do ping -c 2 $ip; done ) < ips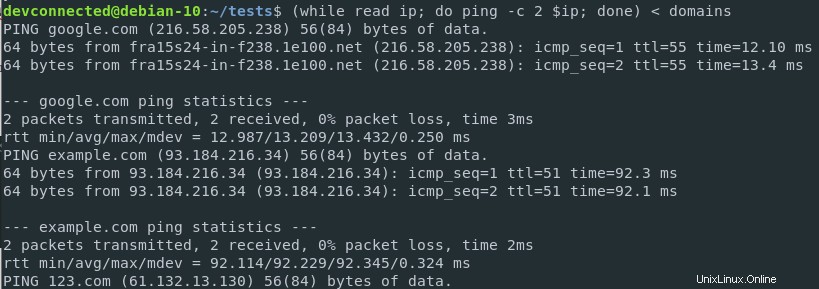
c – Combinación de redirección de entrada con redirección de salida
Ahora que sabe que la entrada estándar se puede redirigir a un comando, es útil mencionar que la redirección de entrada y salida se puede realizar dentro del mismo comando.
Ahora que está ejecutando comandos de ping, obtiene las estadísticas de ping para cada sitio web en la lista de dominios.
Los resultados se imprimen en la salida estándar, que en este caso es el terminal.
Pero, ¿y si quisiera guardar los resultados en un archivo?
Esto se puede lograr combinando redirecciones de entrada y salida en el mismo comando .
$ ( while read ip; do ping -c 2 $ip; done ) < domains > stats.txt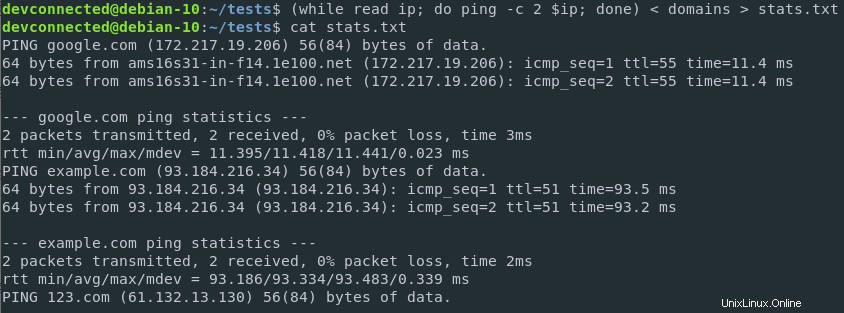
¡Estupendo!
Los resultados se guardaron correctamente en un archivo y pueden ser analizados más tarde por otros equipos de su empresa.
d – Descartar completamente la salida estándar
En algunos casos, podría ser útil descartar la salida estándar por completo.
Puede ser porque no está interesado en la salida estándar de un proceso o porque este proceso está imprimiendo demasiadas líneas en la salida estándar.
Para descartar completamente la salida estándar en Linux, redirige la salida estándar a /dev/null.
La redirección a /dev/null hace que los datos se descarten y borren por completo.
$ cat file > /dev/nullNota:la redirección a /dev/null no borra el contenido del archivo, solo descarta el contenido de la salida estándar.
4 – ¿Qué es la redirección de error estándar en Linux?
Finalmente, después de la redirección de entrada y salida, veamos cómo se puede redirigir el error estándar.
a – ¿Cómo funciona la redirección de error estándar?
De manera muy similar a lo que vimos antes, la redirección de errores está redirigiendo los errores devueltos por los procesos a un dispositivo definido en su host.
Por ejemplo, si estoy ejecutando un comando con parámetros incorrectos, lo que veo en mi pantalla es un mensaje de error y ha sido procesado a través del descriptor de archivo responsable de los mensajes de error (fd[2]).
Tenga en cuenta que no hay formas triviales de diferenciar un mensaje de error de un mensaje de salida estándar en la terminal, tendrá que confiar en que el programador envíe mensajes de error al descriptor de archivo correcto.
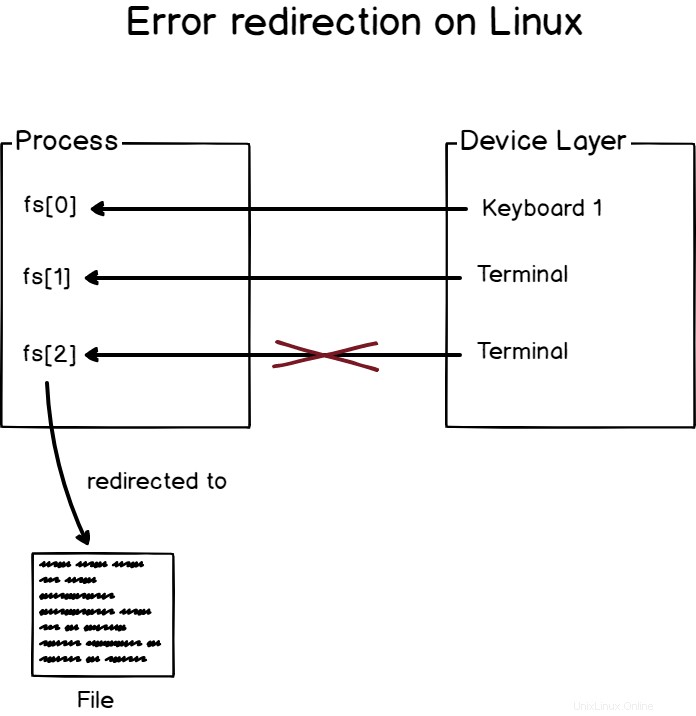
Para redirigir la salida de error en Linux, utilice el "2> ” operador
$ command 2> fileUsemos el ejemplo del comando ping para generar un mensaje de error en la terminal.

Ahora veamos una versión donde la salida de error se redirige a un archivo de error.

Como puede ver, utilicé el operador "2>" para redirigir los errores al archivo "archivo de errores".
Si tuviera que redirigir solo la salida estándar al archivo, no se imprimiría nada.

Como puede ver, el mensaje de error se imprimió en mi terminal y no se agregó nada a mi salida de "archivo normal".
b – Combinación de error estándar con salida estándar
En algunos casos, es posible que desee combinar los mensajes de error con la salida estándar y redirigirlo a un archivo.
Puede ser especialmente útil porque algunos programas no solo devuelven mensajes estándar o mensajes de error, sino una combinación de ambos.
Tomemos el ejemplo de buscar dominio.
Si estoy ejecutando un comando de búsqueda en el directorio raíz sin derechos de sudo, es posible que no tenga autorización para acceder a algunos directorios, como procesos que no son de mi propiedad, por ejemplo.
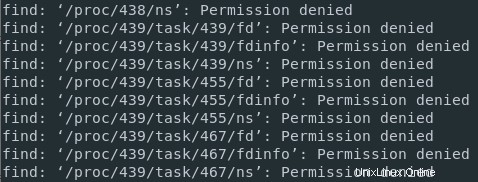
Como consecuencia, habrá una mezcla de mensajes estándar (los archivos propiedad de mi usuario) y mensajes de error (al intentar acceder a un directorio que no me pertenece).
En este caso, quiero tener ambas salidas almacenadas en un archivo.
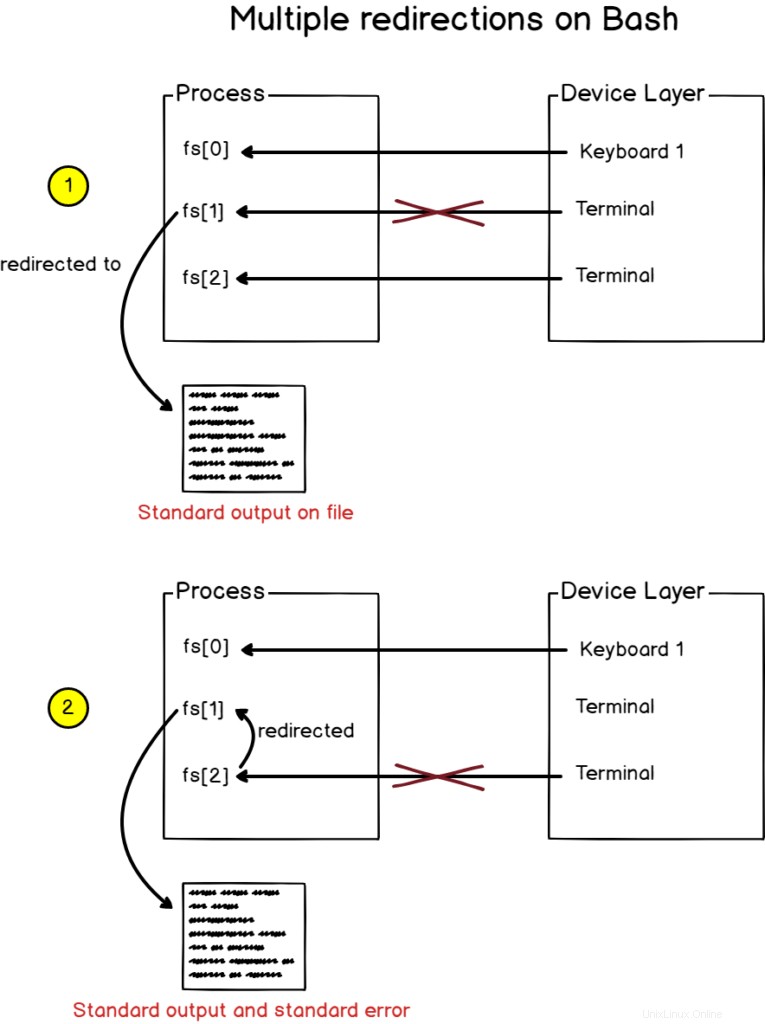
Para redirigir la salida estándar, así como la salida de error a un archivo, use la sintaxis "2<&1" con un ">" al principio.
$ find / -user devconnected > file 2>&1Alternativamente, puede utilizar “&>” sintaxis como una forma más corta de redirigir tanto la salida como los errores.
$ find / -user devconnected &> fileEntonces, ¿qué pasó aquí?
Cuando bash ve varias redirecciones, las procesa de izquierda a derecha.
Como consecuencia, la salida de la función de búsqueda se redirige primero al archivo.
A continuación, se procesa la segunda redirección y redirige el error estándar a la salida estándar (que se asignó previamente al archivo).
5 – ¿Qué son las canalizaciones en Linux?
Las canalizaciones son un poco diferentes de las redirecciones.
Al realizar la redirección de entrada o salida estándar, esencialmente estaba sobrescribiendo la entrada o salida predeterminada en un archivo personalizado.
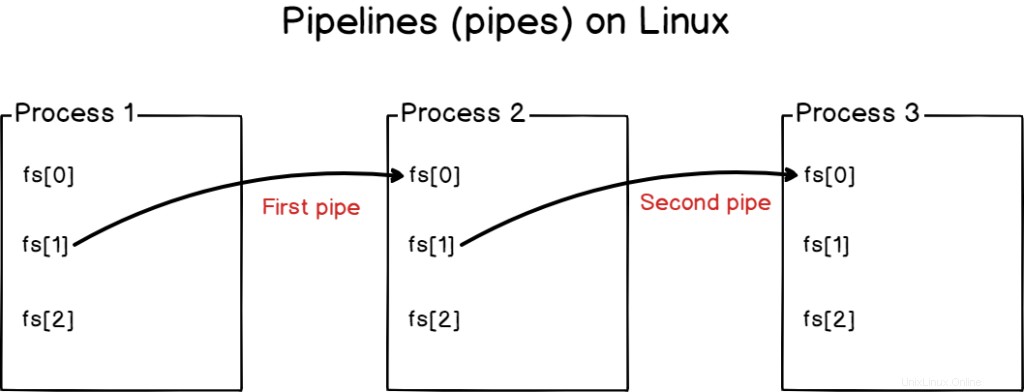
Con las canalizaciones, no sobrescribe entradas o salidas, sino que las conecta entre sí.
Las canalizaciones se utilizan en los sistemas Linux para conectar procesos entre sí, vinculando las salidas estándar de un programa con la entrada estándar de otro.
Se pueden vincular varios procesos con tuberías (o tuberías )
Los administradores de sistemas utilizan mucho las canalizaciones para crear consultas complejas combinando consultas simples juntas.
Uno de los ejemplos más populares es, probablemente, contar el número de líneas en un archivo de texto, después de aplicar algunos filtros personalizados en el contenido del archivo.
Volvamos al archivo de dominios que creamos en las secciones anteriores y cambiemos sus extensiones de país para incluir dominios .net.
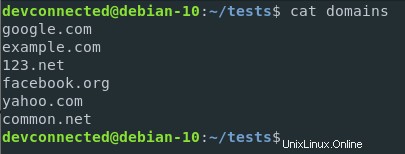
Ahora supongamos que desea contar la cantidad de dominios .com en el archivo.
¿Cómo realizarías eso? Usando tuberías.
Primero, desea filtrar los resultados para aislar solo los dominios .com en el archivo. Luego, desea canalizar el resultado al comando "wc" para contarlos.
Así es como contaría los dominios .com en el archivo.
$ grep .com domains | wc -l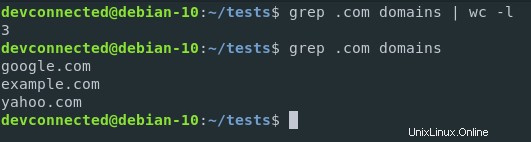
Esto es lo que sucedió con un diagrama en caso de que aún no puedas entenderlo.
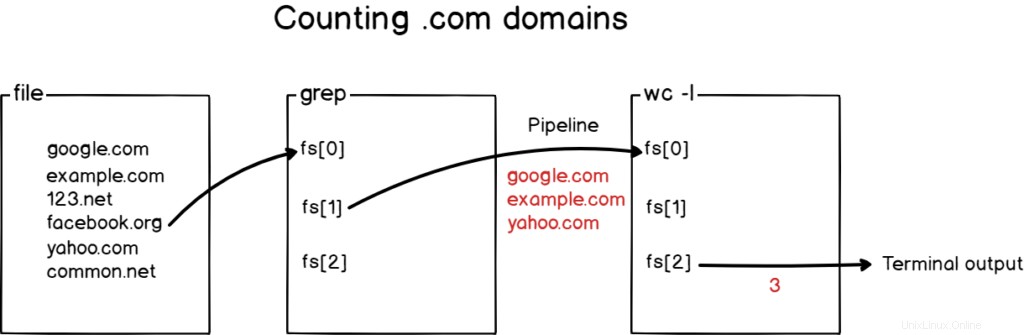
¡Impresionante!
6 – Conclusión
En el tutorial de hoy, aprendió qué es la redirección de entrada y salida y cómo se puede usar de manera efectiva para realizar operaciones administrativas en su sistema Linux.
También aprendiste sobre tuberías (o conductos) que se utilizan para encadenar comandos con el fin de ejecutar comandos más largos y complejos en su host.
Si tiene curiosidad acerca de la administración de Linux, tenemos una categoría completa dedicada a ella en devconnected, ¡así que asegúrese de revisarla!