No hay una función de corrector ortográfico o de diccionario integrada en el comando. No reconoce "registro" y "registros" como relacionados. Su único objetivo es hacer coincidir perfectamente los dos archivos.
En cuanto a la salida, todavía es bastante difícil de traducir. Es poco probable que ahorre mucho tiempo.
Afortunadamente, hay opciones que se pueden agregar para hacer que las cosas sean más legibles para los humanos. Veamos un par de ejemplos diferentes usando la misma lista.
La opción de contexto brinda una representación más visual sobre la información más programática que se muestra de manera predeterminada. Continuemos con nuestro texto de ejemplo.
| Símbolo | Significado |
|---|
| + | Añadir |
| ! | Cambiar |
| – | Eliminar |
| *** | Archivo 1 |
| – – – | Archivo 2 |
christopher:~$ diff -c 1.txt 2.txt
*** 1.txt 2019-10-20 12:05:09.244673327 -0400
--- 2.txt 2019-10-20 12:11More:31.382547316 -0400
***************
*** 1,5 ****
cobweb
! locket
acoustics
expansion
- record
--- 1,5 ----
cobweb
! LOCKET
acoustics
+ records
expansion
Es mucho más fácil de entender cuando ves la información de esta manera. En lugar de la salida alfanumérica, el nuevo conjunto de símbolos lo ayuda a identificar rápidamente las diferencias entre los dos archivos.
La salida primero muestra el primer archivo, es decir, 1.txt y su línea de 1 a 5. Dice que hay un ligero cambio en (parte de) la línea 2 del archivo 1.txt y (parte de) la línea 2 del archivo 2 .txt.
También indica que la línea número 5 del archivo 1 ha sido eliminada (-) en el segundo archivo.
— 1,5 —- indica el inicio del segundo archivo y dice que la línea 2 ha cambiado ligeramente con respecto a la línea 2 del archivo 1. También indica que se agregó la línea 4 (+) en el segundo archivo y no hay ninguna correspondiente línea en el archivo 1.
Ejemplo 3:Diferencia en contexto “Unificado” con -u
Esta opción proporciona una salida similar al formato de contexto copiado. En lugar de mostrar los dos archivos por separado, los fusiona.
christopher:~$ diff 1.txt 2.txt -u
--- 1.txt 2019-10-20 12:05:09.244673327 -0400
+++ 2.txt 2019-10-20 12:11:31.382547316 -0400
@@ -1,5 +1,5 @@
cobweb
-locket
+LOCKET
acoustics
+records
expansion
-record
Como puede ver, usa los mismos símbolos que antes, pero en lugar del símbolo de cambio, sugiere que se realicen cambios usando + fáciles de leer. o - simbolos Aquí, se recomienda eliminar la línea 2 de 1.txt y reemplácelo con la línea 2 de 2.txt .
En el futuro, también sugiere que agregue registros después de la línea que contiene la acústica y elimine la línea record después de la línea que contiene la expansión.
Todos estos cambios se sugieren para el primer archivo en el comando diff. Este es otro escenario en el que es útil recordar que el programa diff utiliza el segundo archivo enumerado como "original" o base para las correcciones.
Para comparar una lista como esta, personalmente encuentro este método más fácil de usar. Le brinda una visualización clara del texto que debe cambiarse para que los archivos sean idénticos.
Ejemplo 4:Comparar pero ignorar casos con -i
Las búsquedas que distinguen entre mayúsculas y minúsculas son las predeterminadas para diff, pero puede desactivarlas. Veamos qué sucede cuando haces eso.
christopher:~$ diff 1.txt 2.txt -i
3a4
> records
5d5
< record
Como puede ver, "relicario" y "MEDALLA" ya no aparecen como cambios sugeridos.
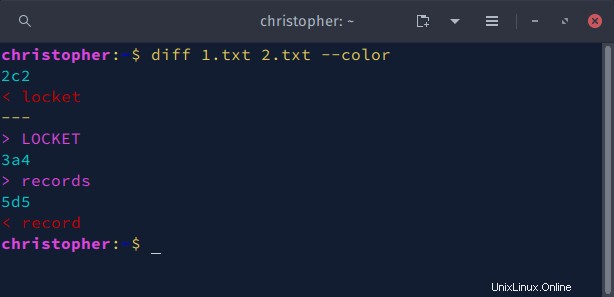
Ejemplo 5:Diferencia con –color
Puedes usar --color para resaltar los cambios en la salida del comando diff. Cuando se ejecuta el comando, las secciones de salida se imprimirán en diferentes colores desde la paleta del terminal.
Ejemplo 6:Análisis rápido de archivos con las opciones de comando diff -s y -q
Hay un par de formas sencillas de comprobar si los archivos son idénticos o no. Si usa -s le dirá que los archivos son idénticos o se ejecutará de forma diferente.
Usando -q solo le dirá que los archivos "difieren". Si no lo hacen, no obtendrá ningún resultado.
christopher:~$ diff 1.txt 1.txt -s
Files 1.txt and 1.txt are identical
christopher:~$ diff 1.txt 2.txt -q
Files 1.txt and 2.txt differ
Consejo extra:usar el comando diff en Linux con archivos de texto grandes
Es posible que no siempre esté comparando información tan simple. Es posible que tenga archivos de texto grandes para escanear y encontrar diferencias. Detallaré algunos métodos para manejar este tipo de problema.
Para este ejemplo, creé dos archivos con grandes fragmentos de texto (lorem ipsum). Cada línea tiene cientos de columnas. Obviamente, esto dificultó la comparación de líneas.
Cuando diff se ejecuta en un archivo como este, la salida genera enormes fragmentos de texto y los símbolos son difíciles de ver incluso con herramientas como la salida contextual.
Para ahorrar espacio, tomé una captura de pantalla de la salida para que la veas.
No es muy útil, ¿verdad?
Puede utilizar algunos de los mismos conceptos para analizar este tipo de archivos. No funcionarán bien a menos que el archivo tenga el formato adecuado. Algunos bloques grandes de texto no tienen saltos de línea. Probablemente haya encontrado un archivo como este en el que necesitaba habilitar "Word Wrap" para que todo el texto se mostrara dentro del espacio asignado sin usar una barra de desplazamiento. La razón por la que esto sucede es que algunos formatos de texto no crean saltos de línea automáticamente. Así es como terminas con los grandes fragmentos de texto en solo 2 o 3 líneas. Hay una solución bastante fácil para esto.
Use fold para envolver texto en líneas
Este es el Manual de Linux, por lo que, naturalmente, tenemos una solución para usted y podemos incluir un mini tutorial. Aquí hay un excelente artículo sobre fold (Unix) y fmt (GNU). Daré un ejemplo rápido que debería explicarse por sí mismo para avanzar.
El comando plegar se usa para romper líneas usando el número de columnas. Se puede personalizar para brindarle opciones sobre cómo se implementan estos nuevos saltos de línea.
En el ejemplo aquí, separará el archivo en un ancho estandarizado y usará -s opción. Esto le dice al programa que rompa SÓLO donde hay espacios en blanco, no en medio del texto.
Use fold para insertar rápidamente saltos de línea
fold -w 80 -s lorem.txt > lorem.txt
fold -w 80 -s lorem2.txt > lorem2.txt
Con ambos archivos divididos en 31 líneas en lugar de 3, puede compararlos de manera mucho más efectiva. Este es un ejemplo de su salida con el filtro de contexto unificado.
christopher:~$ diff lorem.txt 2lorem.txt -u
--- lorem.txt 2019-10-27 09:39:07.298691695 -0400
+++ 2lorem.txt 2019-10-27 09:39:08.370704501 -0400
@@ -1,10 +1,10 @@
Lorem ipsum dolor sit amet, consectetur adipiscing elit. Vivamus in tincidunt
sapien. Maecenas sagittis ex risus, in vehicula turpis imperdiet sed. Phasellus
placerat posuere maximus. In hac habitasse platea dictumst. Ut vel tristique
-eros, sit amet sodales nibh. Maecenas non nibh a nisi porttitor porta.
+eros, sit amet sodales nibh. Maecenas non nibh a nisi porttitor PORTA.
Suspendisse at mauris vitae sapien euismod tincidunt. Sed placerat finibus
blandit. Duis ornare ante at ipsum accumsan, nec bibendum nibh tincidunt.
-Nullam ut rhoncus risus. Phasellus est ex, tristique et semper eu,
+Nullam ut rhoncus risus. Phasellus est ex, tristique et semper eu, facilisis
vitae enim. Nam condimentum, purus nec semper efficitur, nisi quam vehicula
sem, eget finibus diam ipsum suscipit velit.
@@ -21,7 +21,7 @@
Maecenas lacinia cursus tristique. Nulla a hendrerit orci. Donec lobortis nisi
sed ante euismod lobortis. Nullam sit amet est nec nunc porttitor sollicitudin
-a ut orci. Ut euismod, ex at venenatis mattis, neque massa dignissim QUAM, at
+a ut orci. Ut euismod, ex at venenatis mattis, neque massa dignissim quam, at
interdum mi metus vel tellus. Fusce nec dui a risus posuere mattis at eu orci.
Proin purus sem, finibus eget viverra vel, porta pulvinar ex. In hac habitasse
platea dictumst. Nunc faucibus leo nec tristique porta. Phasellus luctus ipsum
Usar diff con –minimal output
Puede hacer que esto sea un poco más fácil de leer con --minimal etiqueta. Esto hace que los archivos de texto más grandes sean un poco más fáciles de leer. Echemos un vistazo a la salida.
christopher:~$ diff lorem.txt 2lorem.txt --minimal
4c4
< eros, sit amet sodales nibh. Maecenas non nibh a nisi porttitor porta.
---
> eros, sit amet sodales nibh. Maecenas non nibh a nisi porttitor PORTA.
7c7
< Nullam ut rhoncus risus. Phasellus est ex, tristique et semper eu,
---
> Nullam ut rhoncus risus. Phasellus est ex, tristique et semper eu, facilisis
24c24
< a ut orci. Ut euismod, ex at venenatis mattis, neque massa dignissim QUAM, at
---
> a ut orci. Ut euismod, ex at venenatis mattis, neque massa dignissim quam, at
Puede combinar cualquiera de estos consejos o usar algunas de las otras opciones enumeradas en las páginas de manual de diff. Esta es una utilidad de software poderosa y fácil de usar.
Espero que hayas encontrado útil este artículo. Si tienes un consejo, no olvides dejarnos un comentario y contarnos al respecto.