Si está buscando una plataforma de análisis de datos en tiempo real, Jack Wallen cree que Apache Druid es difícil de superar. Descubra cómo poner en marcha esta herramienta y luego cómo cargar datos de muestra.
Apache Druid es una base de datos de análisis en tiempo real que se diseñó para generar análisis rápidos de corte y dados en conjuntos masivos de datos. Puede ejecutar fácilmente Apache Druid desde una versión de escritorio de Linux, o un servidor Linux con una GUI, y luego cargar datos para comenzar a analizar.
Apache Druid incluye funciones como:
- Almacenamiento orientado a columnas
- Índices de búsqueda nativos
- Streaming e ingesta por lotes
- Esquemas flexibles
- particionamiento con tiempo optimizado
- Compatibilidad con SQL
- Escalabilidad horizontal
- Fácil operación
Apache Druid es una gran opción para casos de uso que requieren ingesta en tiempo real, consultas rápidas y tiempo de actividad elevado.
Lo guiaré a través del proceso de ejecución de Apache Druid en Pop!_OS Linux (aunque se puede ejecutar en cualquier distribución de Linux) y luego le mostraré cómo cargar datos de muestra.
Lo que necesitarás
Lo único que necesitará para que esto funcione es una instancia en ejecución de Linux completa con un entorno de escritorio y un usuario con privilegios sudo.
Eso es todo. Hagamos un poco de magia con la base de datos.
Cómo instalar Java 8
Por el momento, Apache Druid solo es compatible con Java 8, por lo que debemos asegurarnos de que esté instalado y configurado como predeterminado. Para instalar Java 8 en una distribución de escritorio basada en Ubuntu, inicie sesión en la máquina, abra una ventana de terminal y emita el comando:
sudo apt install openjdk-8-jdk -y
Una vez completada la instalación, debe configurar Java 8 como predeterminado. Haz esto con el comando:
sudo update-alternatives --config java
Debería ver una lista de todas las versiones de Java que están actualmente instaladas en la máquina. Asegúrese de seleccionar el número que corresponde a Java 8.
Una palabra sobre los servicios Apache Druid
Lo que vamos a lanzar es una microinstancia de Apache Druid, que requiere 4 CPU y 16 GB de RAM. Hay 6 configuraciones de servicio diferentes para Apache Druid, que son:
- Inicio rápido nano:1 CPU, 4 GB de RAM
- Micro-inicio rápido:4 CPU, 16 GB de RAM
- Pequeño:8 CPU, 64 GB de RAM
- Medio:16 CPU, 128 GB de RAM
- Grande:32 CPU, 256 GB de RAM
- Extra grande:64 CPU, 512 GB de RAM
Dependiendo del tamaño de sus datos y necesidades. Cuando ingresa a grandes cantidades de datos, se recomienda que Apache Druid se implemente como un clúster. Sin embargo, dado que acabamos de presentarnos a Apache Druid, la instancia micro estará bien.
Cobertura de lectura obligada para desarrolladores
Cómo descargar y descomprimir Apache Druid
Con Java instalado, es hora de descargar y descomprimir Apache Druid. De vuelta en la ventana de la terminal, descargue la última versión (asegúrese de consultar la página de descarga de Apache Druid para verificar que esta es la última versión) con el comando:
wget https://dlcdn.apache.org/druid/0.22.1/apache-druid-0.22.1-bin.tar.gz
Descomprima el archivo descargado con:
tar xvfz apache-druid-0.22.1-bin.tar.gz
Cambie al directorio recién creado con:
cd apache-druid-0.22.1
Inicie el servicio con:
./bin/start-micro-quickstart
El servicio Apache Druid debería iniciarse sin problemas. Tenga en cuenta que no recuperará su terminal mientras el servicio se ejecuta hasta que lo cancele con CTRL + C.
Cómo acceder a la consola de Apache Druid
En la misma máquina que ejecuta Apache Druid, abra un navegador web y diríjalo a http://localhost:8888 . Desafortunadamente, Apache Druid está configurado de tal manera que no puede acceder a él desde una máquina remota, razón por la cual lo instalamos en una máquina de escritorio.
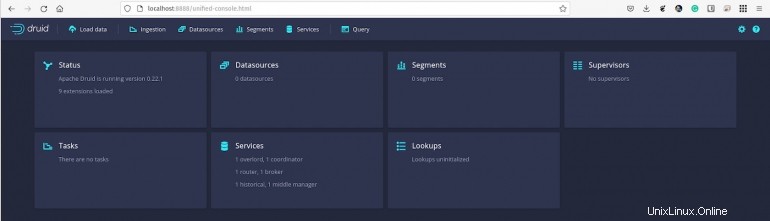
La consola de Apache Druid le dará la bienvenida (Figura A ).
Figura A
Cómo cargar datos
Vamos a cargar una muestra predefinida de datos, que se encuentra en el directorio de inicio rápido/tutorial/. La muestra se llama wikiticker-2015-09-12-sampled.json.gz.
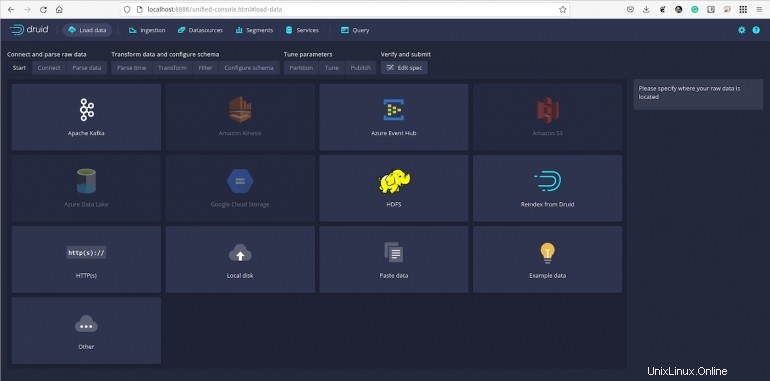
Figura B
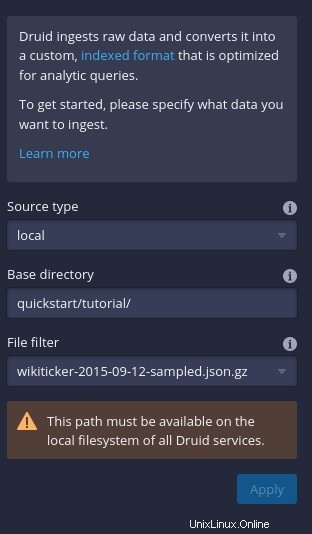
Haga clic en Conectar datos (en el lado derecho de la ventana) y luego, en la barra lateral resultante (Figura C ), escriba quickstart/tutorial como directorio base y wikiticker-2015-09-12-sampled.json.gz en la sección Filtro de archivos.
Figura C
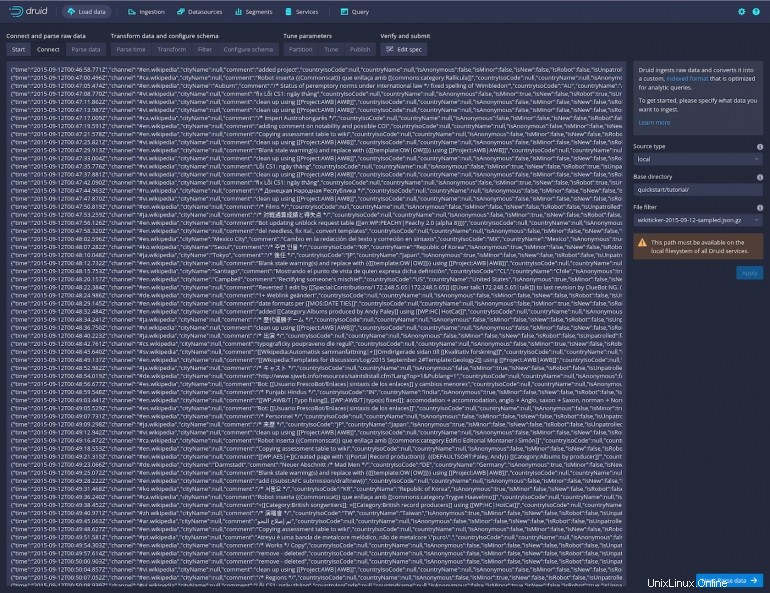
Haga clic en Aplicar y debería ver aparecer una gran cantidad de datos en la ventana principal (Figura D ).
Figura D
Haga clic en Siguiente:Analizar datos en la parte inferior derecha y se le presentará una lista de los datos en un formato más legible (Figura E ).
Figura E
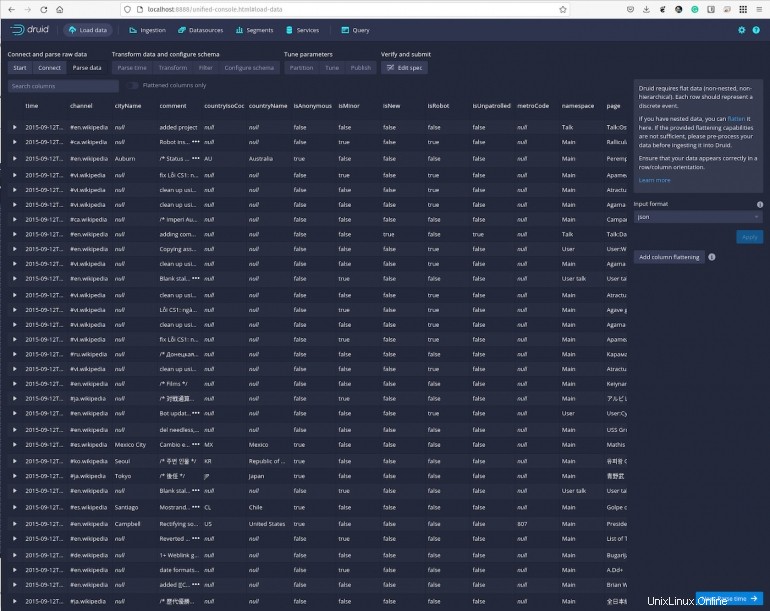
Haga clic en Siguiente:Tiempo de análisis y podrá ver los datos contra marcas de tiempo particulares (Figura F ).
Figura F
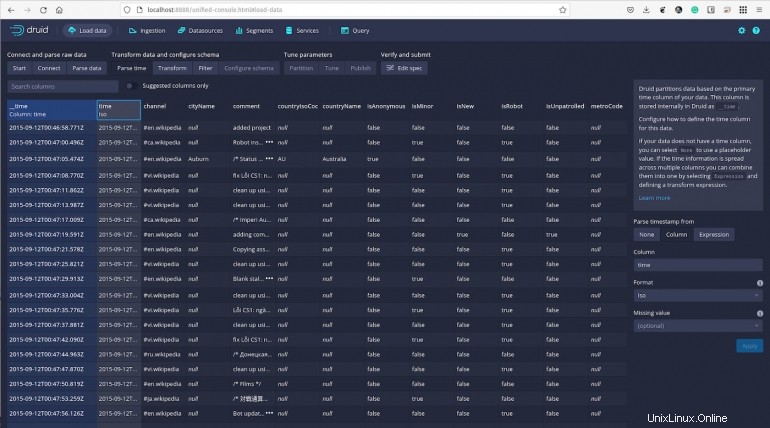
Haga clic en Siguiente:Transformar y podrá realizar transformaciones por fila de los valores de columna para crear nuevas columnas o modificar las que ya existen.
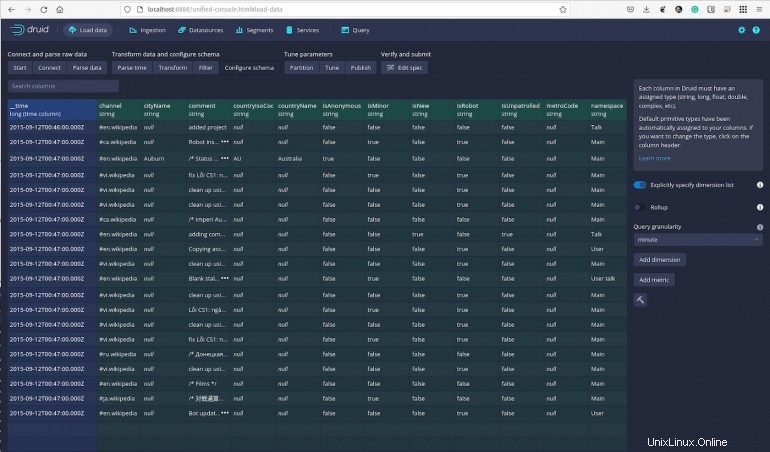
Siga haciendo clic en los datos y, en cualquier momento, puede ejecutar consultas y filtrar datos según sea necesario. En la sección Configurar Esquema (Figura G ), incluso puede especificar la granularidad de sus consultas y agregar dimensiones y métricas.
Figura G
Y eso es más o menos lo básico de Apache Druid. Aunque solo hemos examinado la superficie de lo que puede hacer esta poderosa plataforma de análisis de datos, debería poder tener una idea bastante clara de cómo funciona jugando con los datos de muestra.
Cuando haya terminado de trabajar, asegúrese de volver a la ventana de la terminal y detenga el servicio Apache Druid con CTRL + C.