 Logstash es una aplicación central de gestión de archivos de registro de código abierto.
Logstash es una aplicación central de gestión de archivos de registro de código abierto.
Puede recopilar registros de múltiples servidores, múltiples aplicaciones, analizar esos registros y almacenarlos en un lugar central. Una vez almacenado, puede usar una GUI web para buscar registros, profundizar en los registros y generar varios informes.
Este tutorial explicará los fundamentos de logstash y todo lo que necesita saber sobre cómo instalar y configurar logstash en su sistema.
1. Descargar Logstatsh binario
Logstash es parte de la familia elasticsearch. Descárguelo del sitio web de logstash aquí. Tenga en cuenta que debe tener Java instalado en su máquina para que esto funcione.
o use curl para descargarlo directamente desde el sitio web.
wget https://download.elasticsearch.org/logstash/logstash/logstash-1.4.2.tar.gz tar zxvf logstash-1.4.2.tar.gz cd logstash-1.4.2
Nota:Instalaremos logstash usando yum más tarde. Por ahora, inicialmente descargaremos el binario manualmente para comprobar cómo funciona desde la línea de comandos.
2. Logstash Especificar opciones en la línea de comandos
Para comprender los conceptos básicos de logstash, con fines de prueba, revisemos rápidamente algunas cosas desde la línea de comandos.
Ejecute logstash desde la línea de comando como se muestra a continuación. Cuando se le solicite, simplemente escriba "hola mundo" como entrada.
# bin/logstash -e 'input { stdin { } } output { stdout {} }'
hello world
2014-07-06T17:27:25.955+0000 base hello world En el resultado anterior, la primera línea es el "hola mundo" que ingresamos usando stdin.
La segunda línea es la salida que muestra logstash usando la salida estándar. Básicamente, solo escupe lo que ingresamos en el stdin.
Tenga en cuenta que especificar el indicador de línea de comando -e le permite a Logstash aceptar una configuración directamente desde la línea de comando. Esto es muy útil para probar configuraciones rápidamente sin tener que editar un archivo entre iteraciones.
3. Modifique el formato de salida usando el códec
El códec rubydebug generará los datos de su evento Logstash utilizando la biblioteca ruby-awesome-print.
Entonces, al reconfigurar la salida "stdout" (agregando un "códec"), podemos cambiar la salida de Logstash. Al agregar entradas, salidas y filtros a su configuración, es posible manipular los datos de registro de muchas maneras, para maximizar la flexibilidad de los datos almacenados cuando los consulta.
# bin/logstash -e 'input { stdin { } } output { stdout { codec => rubydebug } }'
hello world
{
"message" => "",
"@version" => "1",
"@timestamp" => "2014-07-06T17:40:48.775Z",
"host" => "base"
}
{
"message" => "hello world",
"@version" => "1",
"@timestamp" => "2014-07-06T17:40:48.776Z",
"host" => "base"
} 4. Descargar ElasticSearch
Ahora que hemos visto cómo funciona Logstash, avancemos un paso más. Es obvio que no podemos pasar la entrada y salida de cada registro manualmente. Entonces, para superar este problema, tendremos que instalar un software llamado Elasticsearch.
Descarga el elasticsearch desde aquí.
O use wget como se muestra a continuación.
curl -O https://download.elasticsearch.org/elasticsearch/elasticsearch/elasticsearch-1.4.0.tar.gz tar zxvf elasticsearch-1.4.0.tar.gz
Inicie el servicio elasticsearch como se muestra a continuación:
cd elasticsearch-1.4.0/ ./bin/elasticsearch
Nota:este tutorial especifica la ejecución de Logstash 1.4.2 con Elasticsearch 1.4.0. Cada versión de Logstash tiene una versión recomendada de Elasticsearch para emparejar. Asegúrese de que las versiones coincidan según la versión de Logstash que esté ejecutando.
5. Verificar búsqueda elástica
Por defecto, elasticsearch se ejecuta en el puerto 9200.
Para fines de prueba, seguiremos tomando la entrada de la entrada estándar (similar a nuestro ejemplo anterior), pero la salida no se mostrará en la salida estándar. En su lugar, irá a elasticsearch.
Para verificar elasticsearch, ejecutemos lo siguiente. Cuando solicite la entrada, simplemente escriba "las cosas geek" como shoen a continuación.
# bin/logstash -e 'input { stdin { } } output { elasticsearch { host => localhost } }'
the geek stuff Dado que no veremos la salida en la salida estándar, debemos mirar la búsqueda elástica.
Vaya a la siguiente URL:
http://localhost:9200/_search?pretty
Lo anterior mostrará todos los mensajes disponibles en el elasticsearch. Debería ver el mensaje que ingresamos en el comando logstash anterior aquí en la salida.
{
"took" : 4,
"timed_out" : false,
"_shards" : {
"total" : 5,
"successful" : 5,
"failed" : 0
},
"hits" : {
"total" : 9,
"max_score" : 1.0,
"hits" : [ {
"_index" : "logstash-2014.07.06",
"_type" : "logs",
"_id" : "G3uZPQCMQ6ed4joNCuseew",
"_score" : 1.0, "_source" : {"message":"the geek stuff","@version":"1","@timestamp":"2014-07-06T18:09:46.612Z","host":"base"}
} ]
} 6. Entradas, salidas y códecs de Logstash
Las entradas, las salidas, los códecs y los filtros se encuentran en el corazón de la configuración de Logstash. Al crear una canalización de procesamiento de eventos, Logstash puede extraer los datos relevantes de sus registros y ponerlos a disposición de elasticsearch para consultar sus datos de manera eficiente.
Las siguientes son algunas de las entradas disponibles. Las entradas son el mecanismo para pasar datos de registro a Logstash
- archivo:lee desde un archivo en el sistema de archivos, muy parecido al comando UNIX "tail -0a"
- syslog:escucha en el conocido puerto 514 los mensajes de syslog y los analiza según el formato RFC3164
- redis:lee desde un servidor redis, usando canales redis y también listas redis. Redis se usa a menudo como un "intermediario" en una instalación centralizada de Logstash, que pone en cola los eventos de Logstash de los "remitentes" remotos de Logstash.
- lumberjack:procesa los eventos enviados en el protocolo lumberjack. Ahora se llama logstash-forwarder.
Los siguientes son algunos de los filtros. Los filtros se utilizan como dispositivos de procesamiento intermediarios en la cadena de Logstash. A menudo se combinan con condicionales para realizar una determinada acción en un evento, si coincide con un criterio particular.
- grok:analiza texto arbitrario y lo estructura. Grok es actualmente la mejor manera en Logstash de analizar datos de registro no estructurados en algo estructurado y consultable. Con 120 patrones integrados en Logstash, ¡es muy probable que encuentre uno que satisfaga sus necesidades!
- mutar:el filtro de mutación le permite realizar mutaciones generales en los campos. Puede cambiar el nombre, eliminar, reemplazar y modificar campos en sus eventos.
- eliminar:descartar un evento por completo, por ejemplo, depurar eventos.
- clonar:hacer una copia de un evento, posiblemente agregando o eliminando campos.
- geoip:agrega información sobre la ubicación geográfica de las direcciones IP (y muestra gráficos sorprendentes en kibana)
Los siguientes son algunos de los códecs. Los resultados son la fase final de la canalización de Logstash. Un evento puede pasar por varias salidas durante el procesamiento, pero una vez que se completan todas las salidas, el evento ha terminado su ejecución.
- elasticsearch:si planea guardar sus datos en un formato eficiente, conveniente y fácil de consultar
- archivo:escribe datos de eventos en un archivo en el disco.
- graphite:envía datos de eventos a graphite, una popular herramienta de código abierto para almacenar y graficar métricas
- statsd:un servicio que "escucha estadísticas, como contadores y temporizadores, se envía a través de UDP y envía agregados a uno o más servicios de back-end conectables".
7. Usar el archivo de configuración de Logstash
Ahora es el momento de pasar de las opciones de la línea de comandos al archivo de configuración. En lugar de especificar las opciones en la línea de comandos, puede especificarlas en un archivo .conf como se muestra a continuación:
# vi logstash-simple.conf
input { stdin { } }
output {
elasticsearch { host => localhost }
stdout { codec => rubydebug }
} Ahora pidamos al logstast que lea el archivo de configuración que acabamos de crear usando la opción -f como se indica a continuación. Para propósitos de prueba, esto todavía usa stdin y stdout. Entonces, escriba un mensaje después de ingresar este comando.
# bin/logstash -f logstash-simple.conf
This is Vadiraj
{
"message" => "This is Vadiraj",
"@version" => "1",
"@timestamp" => "2014-11-07T04:59:20.959Z",
"host" => "base.thegeekstuff.com"
} 8. Analizar el mensaje de registro de entrada de Apache
Ahora, hagamos configuraciones un poco más avanzadas. Elimine todas las entradas del archivo logstash-simple.conf y agregue las siguientes líneas:
# vi logstash-simple.conf
input { stdin { } }
filter {
grok {
match => { "message" => "%{COMBINEDAPACHELOG}" }
}
date {
match => [ "timestamp" , "dd/MMM/yyyy:HH:mm:ss Z" ]
}
}
output {
elasticsearch { host => localhost }
stdout { codec => rubydebug }
} Ahora, ejecute el comando logstash como se muestra a continuación:
# bin/logstash -f logstash-filter.conf
Pero, esta vez, pegue la siguiente entrada del archivo de registro de Apache de muestra como entrada.
# bin/logstash -f logstash-filter.conf "127.0.0.1 - - [11/Dec/2013:00:01:45 -0800] "GET /xampp/status.php HTTP/1.1" 200 3891 "http://cadenza/xampp/navi.php" "Mozilla/5.0 (Macintosh; Intel Mac OS X 10.9; rv:25.0) Gecko/20100101 Firefox/25.0""
El resultado de logstatsh será algo similar a lo siguiente:
{
"message" => "127.0.0.1 - - [11/Dec/2013:00:01:45 -0800] \"GET /xampp/status.php HTTP/1.1\" 200 3891 \"http://cadenza/xampp/navi.php\" \"Mozilla/5.0 (Macintosh; Intel Mac OS X 10.9; rv:25.0) Gecko/20100101 Firefox/25.0\"",
"@version" => "1",
"@timestamp" => "2013-12-11T08:01:45.000Z",
"host" => "base.tgs.com",
"clientip" => "127.0.0.1",
"ident" => "-",
"auth" => "-",
"timestamp" => "11/Dec/2013:00:01:45 -0800",
"verb" => "GET",
"request" => "/xampp/status.php",
"httpversion" => "1.1",
"response" => "200",
"bytes" => "3891",
"referrer" => "\"http://cadenza/xampp/navi.php\"",
"agent" => "\"Mozilla/5.0 (Macintosh; Intel Mac OS X 10.9; rv:25.0) Gecko/20100101 Firefox/25.0\""
} Como puede ver en el resultado anterior, nuestra entrada se analiza en consecuencia y todos los valores se dividen y almacenan en los campos correspondientes.
El filtro grok extrajo el registro de apache y lo dividió en bits útiles para que podamos consultar más tarde.
9. Archivo de configuración de Logstash para el registro de errores de Apache
Cree el siguiente archivo de configuración logstash para el archivo apache error_log.
# vi logstash-apache.conf
input {
file {
path => "/var/log/httpd/error_log"
start_position => beginning
}
}
filter {
if [path] =~ "error" {
mutate { replace => { "type" => "apache_error" } }
grok {
match => { "message" => "%{COMBINEDAPACHELOG}" }
}
}
date {
match => [ "timestamp" , "dd/MMM/yyyy:HH:mm:ss Z" ]
}
}
output {
elasticsearch {
host => localhost
}
stdout { codec => rubydebug }
} En el archivo de configuración anterior:
- El archivo de entrada es /var/log/httpd/error_log y la posición inicial será el comienzo del archivo.
- Filtrar el archivo de entrada y renombrar (mutar) cualquier cosa con error como apache_error. grok creará un apachelog combinado en la columna del mensaje y los datos mostrarán la marca de tiempo con el formato dado.
- La salida se almacenará en elasticsearch en localhost y se repetirá a través de stdout en formato de impresión ruby con el códec => rubydebug
10. Archivo de configuración de Logstash para el registro de errores de Apache y el registro de acceso
Podemos especificar una carta comodín para leer todos los archivos de registro con *_log como se muestra a continuación.
Pero, también necesitamos cambiar las condiciones en consecuencia para analizar tanto el acceso como el registro de errores como se muestra a continuación.
# vi logstash-apache.conf
input {
file {
path => "/var/log/httpd/*_log"
}
}
filter {
if [path] =~ "access" {
mutate { replace => { type => "apache_access" } }
grok {
match => { "message" => "%{COMBINEDAPACHELOG}" }
}
date {
match => [ "timestamp" , "dd/MMM/yyyy:HH:mm:ss Z" ]
}
} else if [path] =~ "error" {
mutate { replace => { type => "apache_error" } }
} else {
mutate { replace => { type => "random_logs" } }
}
}
output {
elasticsearch { host => localhost }
stdout { codec => rubydebug }
} 11. Configurar repositorios adicionales de Yum
Se acabaron las pruebas. Ahora sabemos cómo funciona Logstash con elasticseach.
Instalaremos lo siguiente:
- logstash:nuestro servidor de registro central
- Elasticsearch:para almacenar los registros
- Redis:para filtro
- Nginx:para ejecutar Kibana
- Kibana:es un panel de GUI hermoso y pone todo junto
Antes de instalar, configure los siguientes repositorios:
# cd /etc/yum.repos.d/ # vi /etc/yum.repos.d/logstash.repo [logstash] name=Logstash baseurl=http://packages.elasticsearch.org/logstash/1.4/centos gpgcheck=1 gpgkey=http://packages.elasticsearch.org/GPG-KEY-elasticsearch enabled=1 # vi /etc/yum.repos.d/elasticsearch.repo [elasticsearch] name=Elasticsearch baseurl=http://packages.elasticsearch.org/elasticsearch/1.4/centos gpgcheck=1 gpgkey=http://packages.elasticsearch.org/GPG-KEY-elasticsearch enabled=1
Además, configure el repositorio EPEL como discutimos anteriormente.
12. Instale Elasticsearch, Nginx y Redis y Logstash
Primero actualice el sistema y luego instale logstash junto con elasticsearch, redis y nginx como se muestra a continuación:
yum clean all yum update -y yum install -y install elasticsearch redis nginx logstash
13. Instalar Kibana
Instale Kibana para el tablero como se muestra a continuación:
cd /opt/ wget https://download.elasticsearch.org/kibana/kibana/kibana-3.1.2.tar.gz tar -xvzf kibana-3.1.2.tar.gz mv kibana-3.1.2 /usr/share/kibana3
14. Configurar Kibana
Tenemos que contarle a Kibana sobre elasticsearch. Para ello, modifique el siguiente config.js.
# vi /usr/share/kibana3/config.js elasticsearch: "http://log.thegeekstuff.com:9200"
Dentro del archivo anterior, busque elasticsearch y cambie "dev.kanbier.lan" en esa línea a su dominio (por ejemplo:log.thegeekstuff.com)
15. Configurar Kibana para que se ejecute desde Nginx
También tenemos que hacer que kibana se ejecute desde el servidor web nginx.
Agregue lo siguiente a nginx.conf
server {
listen *:80 ;
server_name log.thegeekstuff.com;
access_log /var/log/nginx/kibana.myhost.org.access.log;
location / {
root /usr/share/kibana3;
index index.html index.htm;
} Además, no olvide configurar la dirección IP adecuada de su servidor en el archivo redis.conf.
16. Configurar el archivo de configuración de Logstash
Ahora necesitamos crear un archivo de configuración logstash similar al archivo de configuración de ejemplo que usamos anteriormente.
Definiremos la ruta de los archivos de registro, qué puerto recibir los registros remotos y le informaremos a logstash sobre la herramienta elasticsearch.
# vi /etc/logstash/conf.d/logstash.conf
input {
file {
type => "syslogpath => [ "/var/log/*.log", "/var/log/messages", "/var/log/syslog" ]
sincedb_path => "/opt/logstash/sincedb-access"
}
redis {
host => "10.37.129.8"
type => "redis-input"
data_type => "list"
key => "logstash"
}
syslog {
type => "syslog"
port => "5544"
}
}
filter {
grok {
type => "syslog"
match => [ "message", "%{SYSLOGBASE2}" ]
add_tag => [ "syslog", "grokked" ]
}
}
output {
elasticsearch { host => "log.thegeekstuff.com" }
}" 17. Verifique e inicie Logstash, Elasticsearch, Redis y Nginx
Inicie todos estos servicios como se muestra a continuación:
service elasticsearch start service logstash start service nginx start service redis start
18. Verificar la GUI web de Logstash
Abra un navegador y vaya al nombre del servidor (host) que usó en el archivo de configuración anterior. Por ejemplo:log.thegeekstuff.com
Verá un gráfico similar al siguiente, desde donde puede manipular, examinar y desglosar todos los archivos de registro recopilados por logstash.
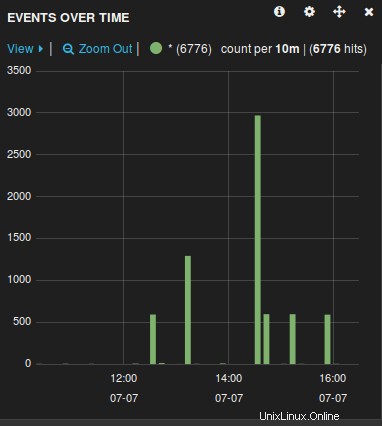
Ahora que el servidor de registro está listo, solo tiene que reenviar los archivos de registro del servidor remoto administrados por rsyslog a este servidor central modificando el archivo rsyslog.conf.