Solución 1:
Tomado directamente de mi entrada de blog:http://www.standalone-sysadmin.com/blog/2008/09/introduction-to-lvm-in-linux/
En primer lugar, hablemos de la vida sin LVM. En los viejos tiempos, tenías un disco duro. Este disco duro podría tener particiones. Puede instalar sistemas de archivos en estas particiones y luego usar esos sistemas de archivos. Cuesta arriba en ambos sentidos. Se parecía mucho a esto:
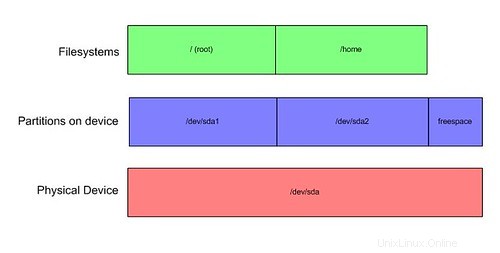
Tienes la unidad real, en este caso sda. En esa unidad hay dos particiones, sda1 y sda2. También hay algo de espacio libre sin usar. Cada una de las particiones tiene un sistema de archivos, que está montado. El tipo de sistema de archivos real es arbitrario. Podrías llamarlo ext3, reiserfs, o lo que sea. Lo importante a tener en cuenta es que existe una correlación uno a uno directa entre las particiones de disco y los posibles sistemas de archivos.
Agreguemos un poco de administración de volumen lógico que recree exactamente la misma estructura:
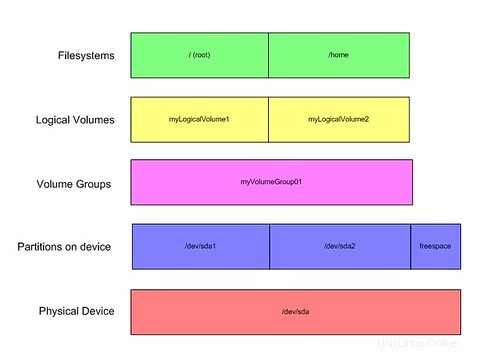
Ahora, verá las mismas particiones, sin embargo, hay una capa encima de las particiones llamada "Grupo de volúmenes", literalmente un grupo de volúmenes, en este caso, particiones de disco. Podría ser aceptable pensar en esto como una especie de disco virtual que puede particionar. Dado que estamos haciendo coincidir exactamente nuestra configuración anterior, aún no puede ver las fortalezas del sistema. Puede notar que encima del grupo de volúmenes, hemos creado volúmenes lógicos, que podrían considerarse como particiones virtuales, y es sobre estos que construimos nuestros sistemas de archivos.
Veamos qué sucede cuando agregamos más de un volumen físico:
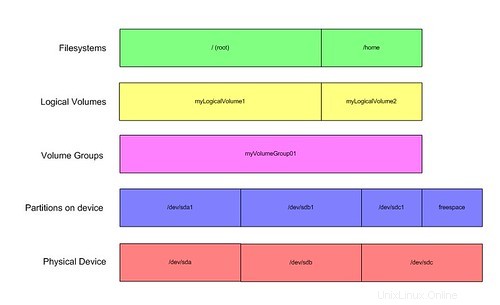
Aquí tenemos tres discos físicos, sda, sdb y sdc. Cada uno de los dos primeros discos tiene una partición que ocupa todo el espacio. El último, sdc, tiene una partición que ocupa la mitad del disco, con la mitad restante de espacio libre sin particionar.
Podemos ver el grupo de volúmenes arriba que incluye todos los volúmenes disponibles actualmente. Aquí se encuentra uno de los mayores puntos de venta. Puede construir una partición lógica tan grande como la suma de sus discos. En muchos sentidos, esto es similar a cómo funciona el nivel 0 de RAID, excepto que no hay división en absoluto. Los datos se escriben en su mayor parte linealmente. Si necesita redundancia o los aumentos de rendimiento que proporciona RAID, asegúrese de colocar sus volúmenes lógicos encima de las matrices RAID. Las porciones RAID funcionan exactamente como los discos físicos aquí.
Ahora, tenemos este grupo de volúmenes que ocupa 2 discos y medio. Ha sido tallado en dos volúmenes lógicos, el primero de los cuales es más grande que cualquiera de los discos. A los volúmenes lógicos no les importa el tamaño de los discos físicos reales, ya que todo lo que ven es que están extraídos de myVolumeGroup01. Esta capa de abstracción es importante, como veremos.
¿Qué sucede si decidimos que necesitamos el espacio no utilizado porque hemos agregado más usuarios?
Normalmente tendríamos problemas si usáramos el mapeo uno a uno, pero con volúmenes lógicos, esto es lo que podemos hacer:
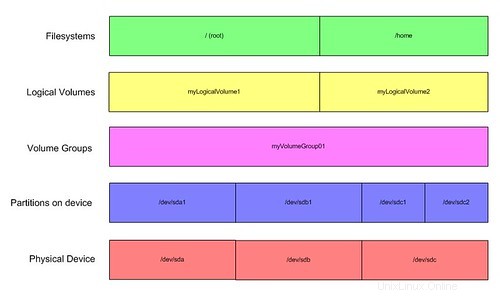
Aquí tomamos el espacio previamente libre en /dev/sdc y creamos /dev/sdc2. Luego lo agregamos a la lista de volúmenes que componen myVolumeGroup01. Una vez hecho esto, éramos libres de expandir cualquiera de los volúmenes lógicos según fuera necesario. Desde que agregamos usuarios, crecimos myLogicalVolume2. En ese momento, siempre que el sistema de archivos /home lo admitiera, éramos libres de aumentarlo para llenar el espacio adicional. Todo porque abstrajimos nuestro almacenamiento de los discos físicos en los que vive.
Muy bien, eso cubre el por qué básico de la gestión de volúmenes lógicos. Como estoy seguro de que está ansioso por aprender más sobre cómo preparar y construir sus propios sistemas, aquí hay algunos recursos excelentes para comenzar:
http://www.pma.caltech.edu/~laurence/Linux/lvm.html
http://www.freeos.com/articles/3921/
http://www.linuxdevcenter.com/pub/a/linux/2006/04/27/managing-disk-space-with-lvm.html
Solución 2:
Puede usar LVM para hacer muchas cosas con discos. El principal beneficio es la capacidad de hacer crecer los sistemas de archivos sobre la marcha. Suponga que está configurando un servidor de registro y sabe que en el futuro tendrá una tonelada de datos. Ext3 admite un máximo de 16 TB (más dependiendo de su kernel y versión de EL). Pero, ¿qué sucede si sabe que en 2 años necesitará 1 PB de almacenamiento? Bueno, esto crea algunos problemas. Primero, su jefe lo mirará con ojos de venado cuando le diga el precio de ese hardware de almacenamiento. Esto lleva a otro problema:debe comenzar con una pequeña solución que pueda escalar hacia arriba. LVM te da esa opción. Empiezas con unos cuantos discos. Luego agrega más, los convierte en un grupo lógico, los agrega al primer volumen lógico, aumenta el tamaño del volumen y finalmente aumenta el sistema de archivos. Listo, tienes un buen sistema de archivos escalable.
Esto le evita tener que sacar los datos del dispositivo, reformatear los LUN y luego volver a mover todo para realizar una actualización. Perdón por la brevedad, espero que tenga sentido.
Editar:también debo tener en cuenta que si está tratando con 1 PB, no querrá usar Ext3... probablemente XFS.
Solución 3:
Hay una serie de beneficios indirectos de LVM. Lo principal que hace LVM es abstraer los discos físicos del sistema operativo . El principal beneficio de esto es simplemente flexibilidad . La mayoría de los beneficios de LVM solo se obtienen cuando tiene un sistema de archivos que admite el cambio de tamaño sobre la marcha. Lo básico que hace LVM se describe a continuación:
Las particiones del sistema existen una capa por encima del disco
Sin LVM, Linux usa las particiones ubicadas físicamente en el disco. Las particiones son nombres directos de dispositivos. La tabla de particiones reside en el MBR y normalmente (en el caso de particiones lógicas extendidas) en el registro de arranque extendido (que le permite crear una mayor cantidad de particiones). Las particiones definen un tamaño y escribir entre otros atributos (más específicamente, definen un cilindro inicial y final que esencialmente define el tamaño). Debido a que están tan estrechamente vinculados al disco, es importante configurar un esquema de partición "correcto" al momento de la instalación. Si de repente, la función de una máquina cambia o si es un novato y no ha entendido las implicaciones de la partición, o si está subestimando el uso del disco en alguna parte, o los registros de una aplicación en particular, cambiar esa partición puede ser engorroso. Hay herramientas para hacerlo, pero generalmente necesita mover datos fuera de la partición para cambiarlos. Obviamente, si tiene cuatro particiones, cambiar el cilindro final de la segunda partición afecta los cilindros de inicio de las particiones tercera y cuarta y entonces se encuentra en una situación complicada.
Los ingenuos pueden abogar por el uso de una única partición grande, pero es posible que se deshaga cuando necesite introducir cuotas o aislar procesos no autorizados que llenan partes de su sistema (por ejemplo, /var/log, /tmp, etc.)
Los beneficios de esto son:
Agregar/quitar almacenamiento
Agregar almacenamiento es generalmente trivial. Si está utilizando hardware o software RAID y agrega más discos, es posible que a menudo tenga que jugar con los enlaces simbólicos para reconstruir la matriz RAID para que Linux haga que su nuevo almacenamiento esté disponible en las ubicaciones que desee.
Tome el ejemplo de un directorio /home grande que se está llenando. Eso existe en un volumen RAID 1 de dos discos existente. Desea agregar dos discos más. Los configura en una configuración RAID 1 de hardware. Sin LVM, tiene un par de opciones:
- Reconstruya la matriz RAID completa en una configuración 1+0 que requiere sacar los datos de la máquina, reconstruirlos y volver a encenderlos.
- Cree un nuevo grupo de volúmenes RAID 1 que sea independiente. Linux ya tiene el primer volumen RAID montado en /home, por lo que debe montar el segundo volumen RAID en /home1 o similar. Ahora, para obtener las rutas adecuadas para los usuarios que sean consistentes con la primera, es posible que deba usar enlaces simbólicos para obtener el mismo efecto. Además, esta solución requiere un mantenimiento constante del volumen RAID original y la posible migración de datos fuera de la partición original.
Con LVM, simplemente puede agregar el nuevo grupo de volúmenes RAID 1 al grupo de almacenamiento adicional, cambiar el tamaño del sistema de archivos (siempre que lo admita) y listo, /home ahora es repentinamente más grande. No necesita vincular nada ni hacer mantenimiento en la posibilidad de mover datos de /home a /home1 o viceversa. Enjuague, lave, repita para futuras actualizaciones de discos.
Mantenimiento en línea
La mayoría de las tareas de LVM, siempre que el hardware lo admita, se pueden realizar en línea, sin reiniciar la máquina. Si puede intercambiar discos en caliente en un sistema, puede agregar discos nuevos y, posteriormente, eliminar discos antiguos (quizás más pequeños) para aumentar los requisitos de almacenamiento del sistema.
Uno de los principales problemas con los volúmenes LVM es que a medida que se acercan a la capacidad, la fragmentación puede convertirse en un problema en mi experiencia. Volúmenes> 90 %, y realmente> 95 % pueden significar que puede terminar con una mala fragmentación en el disco según el uso del disco y los tipos de archivo. Rara vez es algo de lo que preocuparse demasiado, ese es el caso con cualquier tipo de gestión de volumen/partición, pero la fragmentación en la capa de volumen en lugar de en la partición es la preocupación aquí.