
En este tutorial, le mostraremos cómo instalar Apache Hadoop en Debian 11. Para aquellos que no lo sabían, Apache Hadoop es una plataforma de software de código abierto basada en Java. que administra el procesamiento y el almacenamiento de datos para aplicaciones de macrodatos. Está diseñado para escalar de servidores únicos a miles de máquinas, cada una de las cuales ofrece computación y almacenamiento locales.
Este artículo asume que tiene al menos conocimientos básicos de Linux, sabe cómo usar el shell y, lo que es más importante, aloja su sitio en su propio VPS. La instalación es bastante simple y asume que se están ejecutando en la cuenta raíz, si no, es posible que deba agregar 'sudo ' a los comandos para obtener privilegios de root. Le mostraré la instalación paso a paso de Apache Hadoop en un Debian 11 (Bullseye).
Requisitos previos
- Un servidor que ejecute uno de los siguientes sistemas operativos:Debian 11 (Bullseye).
- Se recomienda que utilice una instalación de sistema operativo nueva para evitar posibles problemas.
- Acceso SSH al servidor (o simplemente abra Terminal si está en una computadora de escritorio).
- Un
non-root sudo usero acceder alroot user. Recomendamos actuar como unnon-root sudo user, sin embargo, puede dañar su sistema si no tiene cuidado al actuar como root.
Instalar Apache Hadoop en Debian 11 Bullseye
Paso 1. Antes de instalar cualquier software, es importante asegurarse de que su sistema esté actualizado ejecutando el siguiente apt comandos en la terminal:
sudo apt update sudo apt upgrade
Paso 2. Instalación de Java.
Apache Hadoop es una aplicación basada en Java. Por lo tanto, deberá instalar Java en su sistema:
sudo apt install default-jdk default-jre
Verifique la instalación de Java:
java -version
Paso 3. Creación de un usuario de Hadoop.
Ejecute el siguiente comando para crear un nuevo usuario con el nombre Hadoop:
adduser hadoop
Luego, cambie al usuario de Hadoop una vez que se haya creado el usuario:
su - hadoop
Ahora es el momento de generar una clave ssh porque Hadoop requiere acceso ssh para administrar su nodo, máquina remota o local, por lo que para nuestro nodo único de la configuración de Hadoop configuramos es tal que tenemos acceso al localhost:
ssh-keygen -t rsa
Después de eso, otorgue permiso al archivo authorized_keys:
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys chmod 0600 ~/.ssh/authorized_keys
Luego, verifique la conexión SSH sin contraseña con el siguiente comando:
ssh your-server-IP-address
Paso 4. Instalación de Apache Hadoop en Debian 11.
Primero, cambie a usuario de Hadoop y descargue la última versión de Hadoop desde la página oficial usando el siguiente wget comando:
su - hadoop wget https://www.apache.org/dyn/closer.cgi/hadoop/common/hadoop-3.3.1/hadoop-3.3.1-src.tar.gz
Luego, extraiga el archivo descargado con el siguiente comando:
tar -xvzf hadoop-3.3.1.tar.gz
Una vez desempaquetado, cambie el directorio actual a la carpeta Hadoop:
su root cd /home/hadoop mv hadoop-3.3.1 /usr/local/hadoop
Luego, cree un directorio para almacenar registros con el siguiente comando:
mkdir /usr/local/hadoop/logs
Cambiar la propiedad del directorio de Hadoop a Hadoop:
chown -R hadoop:hadoop /usr/local/hadoop su hadoop
Después de eso, configuramos las variables de entorno de Hadoop:
nano ~/.bashrc
Agregue la siguiente configuración:
export HADOOP_HOME=/usr/local/hadoop export HADOOP_INSTALL=$HADOOP_HOME export HADOOP_MAPRED_HOME=$HADOOP_HOME export HADOOP_COMMON_HOME=$HADOOP_HOME export HADOOP_HDFS_HOME=$HADOOP_HOME export YARN_HOME=$HADOOP_HOME export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib/native"
Guarde y cierre el archivo. Luego, active las variables de entorno:
source ~/.bashrc
Paso 5. Configure Apache Hadoop.
- Configurar variables de entorno Java:
sudo nano $HADOOP_HOME/etc/hadoop/hadoop-env.sh
Agregue la siguiente configuración:
export JAVA_HOME=/usr/lib/jvm/java-11-openjdk-amd64 export HADOOP_CLASSPATH+=" $HADOOP_HOME/lib/*.jar"
Luego, necesitamos descargar el archivo de activación de Javax:
cd /usr/local/hadoop/lib sudo wget https://jcenter.bintray.com/javax/activation/javax.activation-api/1.2.0/javax.activation-api-1.2.0.jar
Verifique la versión de Apache Hadoop:
hadoop version
Salida:
Hadoop 3.3.1
- Configure el archivo core-site.xml:
nano $HADOOP_HOME/etc/hadoop/core-site.xml
Agregue el siguiente archivo:
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://0.0.0.0:9000</value>
<description>The default file system URI</description>
</property>
</configuration> - Configurar archivo hdfs-site.xml:
Antes de configurar, cree un directorio para almacenar los metadatos del nodo:
mkdir -p /home/hadoop/hdfs/{namenode,datanode}
chown -R hadoop:hadoop /home/hadoop/hdfs Luego, edite el hdfs-site.xml archivo y defina la ubicación del directorio:
nano $HADOOP_HOME/etc/hadoop/hdfs-site.xml
Agregue la siguiente línea:
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.name.dir</name>
<value>file:///home/hadoop/hdfs/namenode</value>
</property>
<property>
<name>dfs.data.dir</name>
<value>file:///home/hadoop/hdfs/datanode</value>
</property>
</configuration> - Configurar archivo mapred-site.xml:
Ahora editamos el mapred-site.xml archivo:
nano $HADOOP_HOME/etc/hadoop/mapred-site.xml
Agregue la siguiente configuración:
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration> - Configurar el archivo yarn-site.xml:
Debería editar el yarn-site.xml archivo y definir la configuración relacionada con YARN:
nano $HADOOP_HOME/etc/hadoop/yarn-site.xml
Agregue la siguiente configuración:
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration> - Dar formato a NameNode de HDFS.
Ejecute el siguiente comando para formatear el Namenode de Hadoop:
hdfs namenode -format
- Inicie el clúster de Hadoop.
Ahora iniciamos NameNode y DataNode con el siguiente comando a continuación:
start-dfs.sh
A continuación, inicie los administradores de recursos y nodos de YARN:
start-yarn.sh
Ahora puede verificarlos con el siguiente comando:
jps
Salida:
hadoop@idroot.us:~$ jps 58000 NameNode 54697 DataNode 55365 ResourceManager 55083 SecondaryNameNode 58556 Jps 55365 NodeManager
Paso 6. Acceso a la interfaz web de Hadoop.
Una vez instalado correctamente, abra su navegador web y acceda a Apache Hadoop usando la URL http://your-server-ip-address:9870 . Será redirigido a la interfaz web de Hadoop:
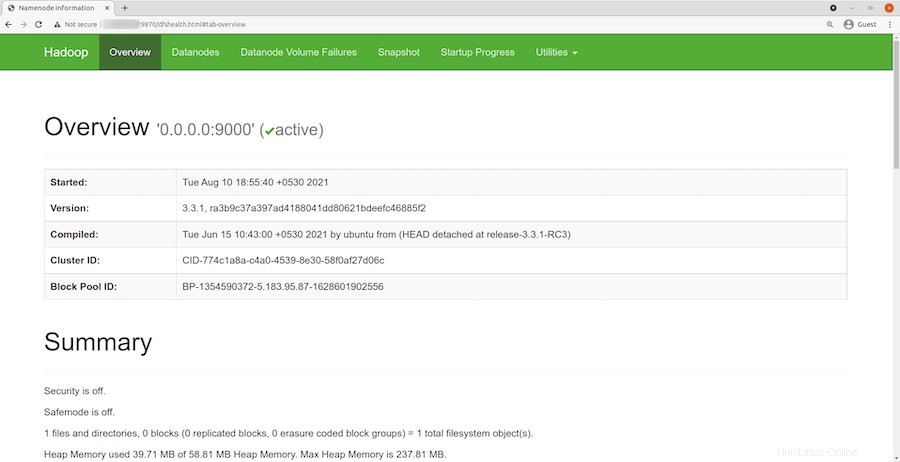
Navegue por la URL o IP de su host local para acceder a DataNodes individuales:http://your-server-ip-address:9864
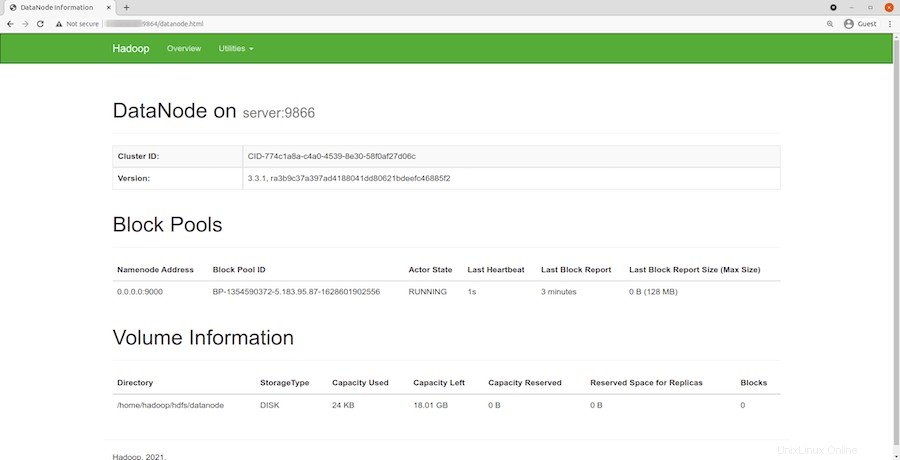
Para acceder al Administrador de recursos de YARN, use la URL http://your-server-ip-adddress:8088 . Debería ver la siguiente pantalla:
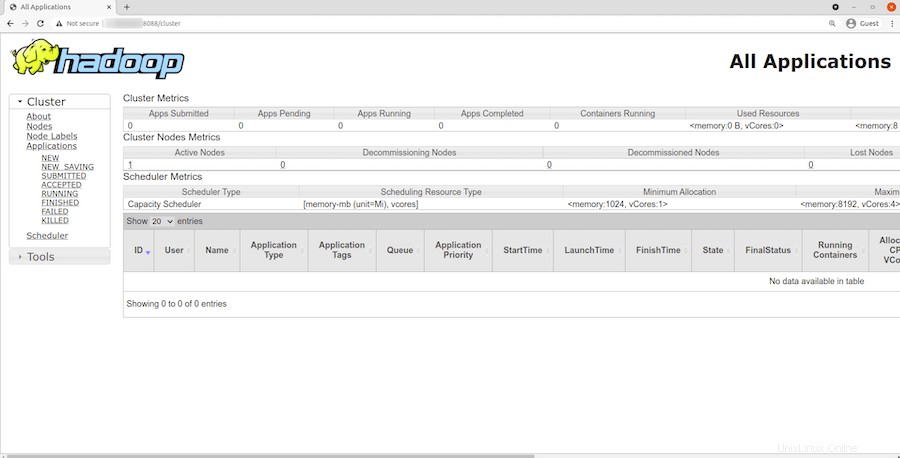
¡Felicitaciones! Ha instalado Hadoop con éxito. Gracias por usar este tutorial para instalar la última versión de Apache Hadoop en Debian 11 Bullseye. Para obtener ayuda adicional o información útil, le recomendamos que consulte el Apache oficial sitio web.