Introducción
MySQL es una aplicación de base de datos que almacena datos en filas y columnas de diferentes tablas para evitar la duplicación. Pueden ocurrir valores duplicados, lo que puede afectar el rendimiento de MySQL.
Esta guía le mostrará cómo encontrar valores duplicados en una base de datos MySQL .

Requisitos previos
- Una instalación existente de MySQL
- Credenciales de cuenta de usuario raíz para MySQL
- Una línea de comando/ventana de terminal
Configuración de una tabla de muestra (opcional)
Este paso lo ayudará a crear una tabla de muestra para trabajar. Si ya tiene una base de datos para trabajar, pase a la siguiente sección.
Abra una ventana de terminal y cambie al shell de MySQL:
mysql –u root –pLista de bases de datos existentes:
SHOW databases;
Cree una nueva base de datos que aún no existe:
CREATE database sampledb;Seleccione la tabla que acaba de crear:
USE sampledb;Cree una nueva tabla con los siguientes campos:
CREATE TABLE dbtable (
id INT PRIMARY KEY AUTO_INCREMENT,
date_x VARCHAR(10) NOT NULL,
system_x VARCHAR(50) NOT NULL,
test VARCHAR(50) NOT NULL
);Insertar filas en la tabla:
INSERT INTO dbtable (date_x,system_x,test)
VALUES ('01/03/2020','system1','hard_drive'),
('01/04/2020','system2','memory'),
('01/10/2020','system2','processor'),
('01/14/2020','system3','hard drive'),
('01/10/2020','system2','processor'),
('01/20/2020','system4','hard drive'),
('01/24/2020','system5','memory'),
('01/29/2020','system6','hard drive'),
('02/02/2020','system7','motherboard'),
('02/04/2020','system8','graphics card'),
('02/02/2020','system7','motherboard'),
('02/08/2020','system9','hard drive');Ejecute la siguiente consulta SQL:
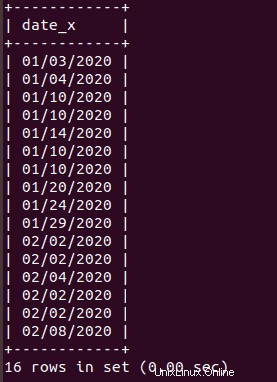
SELECT * FROM dbtable
ORDER BY date_x;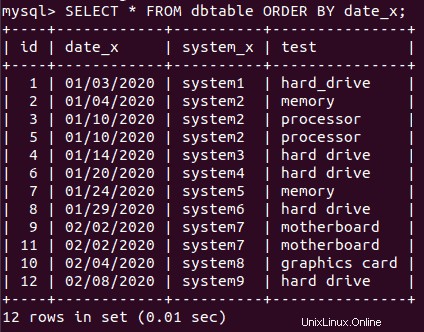
Encontrar duplicados en MySQL
Encuentre valores duplicados en una sola columna
Utilice el GROUP BY función para identificar todas las entradas idénticas en una columna. Continúe con un COUNT() HAVING función para enumerar todos los grupos con más de una entrada.
SELECT
test,
COUNT(test)
FROM
dbtable
GROUP BY test
HAVING COUNT(test) > 1;
Encuentre valores duplicados en varias columnas
Es posible que desee enumerar los duplicados exactos, con la misma información en las tres columnas.
SELECT
date_x, COUNT(date_x),
system_x, COUNT(system_x),
test, COUNT(test)
FROM
dbtable
GROUP BY
date_x,
system_x,
test
HAVING COUNT(date_x)>1
AND COUNT(system_x)>1
AND COUNT(test)>1;

Esta consulta funciona seleccionando y probando el >1 condición en las tres columnas. El resultado es que solo se devuelven filas con valores duplicados en la salida.
Comprobar duplicados en varias tablas con INNER JOIN
Use la función INNER JOIN para encontrar duplicados que existen en varias tablas.
Ejemplo de sintaxis para INNER JOIN la función se ve así:
SELECT column_name
FROM table1
INNER JOIN table2
ON table1.column_name = table2.column name;
Para probar este ejemplo, necesita una segunda tabla que contenga información duplicada del sampledb tabla que creamos arriba.
SELECT dbtable.date_x
FROM dbtable
INNER JOIN new_table
ON dbtable.date_x = new_table.date_x;
Esto mostrará cualquier fecha duplicada que exista entre los datos existentes y la nueva_tabla .