Introducción
Pandas es una biblioteca Python de código abierto que se utiliza principalmente para el análisis de datos. La colección de herramientas del paquete Pandas es un recurso esencial para preparar, transformar y agregar datos en Python.
La biblioteca de Pandas se basa en el paquete NumPy y es compatible con una amplia gama de módulos existentes. La adición de dos nuevas estructuras de datos tabulares, Series y marcos de datos , permite a los usuarios utilizar funciones similares a las de las bases de datos relacionales o las hojas de cálculo.
Este artículo le muestra cómo instalar Python Pandas e introduce comandos básicos de Pandas.

Cómo instalar Python Pandas
La popularidad de Python ha resultado en la creación de numerosas distribuciones y paquetes. Los administradores de paquetes son herramientas eficientes que se utilizan para automatizar el proceso de instalación, administrar actualizaciones, configurar y eliminar paquetes y dependencias de Python.
- Cómo instalar Python 3.8 en Ubuntu 18.04 o Ubuntu 20.04.
- Cómo instalar Python 3 en Windows 10
- Cómo instalar la última versión de Python 3 en Centos 7
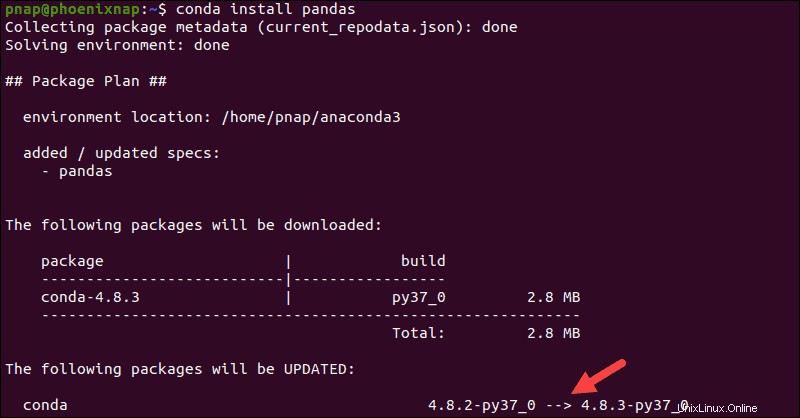
Instalar Pandas con Anaconda
El paquete Anaconda ya contiene la biblioteca Pandas. Verifique la versión actual de Pandas escribiendo el siguiente comando en su terminal:
conda list pandasEl resultado confirma la versión y compilación de Pandas.

Si Pandas no está presente en su sistema, también puede usar el conda herramienta para instalar Pandas:
conda install pandasAnaconda administra toda la transacción mediante la instalación de una colección de módulos y dependencias.
Instalar Pandas con pip
El repositorio de software PyPI se administra regularmente y mantiene las últimas versiones del software basado en Python. Instale pip, el administrador de paquetes de PyPI, y utilícelo para implementar pandas de Python:
pip3 install pandasEl proceso de descarga e instalación tarda unos minutos en completarse.
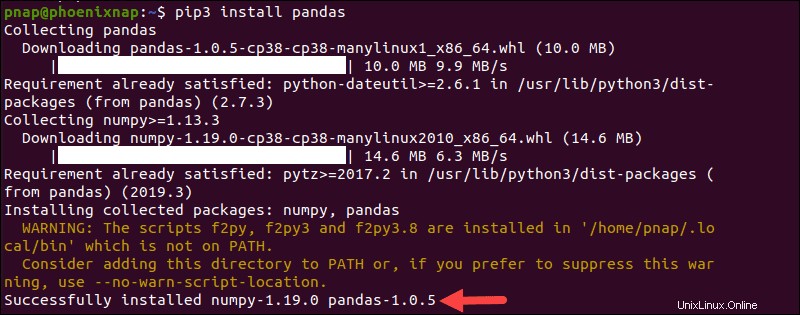
Instalar Pandas en Linux
La instalación de una solución preempaquetada puede no ser siempre la opción preferida. Puede instalar Pandas en cualquier distribución de Linux usando el mismo método que con otros módulos. Por ejemplo, use el siguiente comando para instalar el módulo básico de Pandas en Ubuntu 20.04:
sudo apt install python3-pandas -y Tenga en cuenta que los paquetes en los repositorios de Linux a menudo no contienen la última versión disponible.
Uso de Python Pandas
La flexibilidad de Python le permite usar Pandas en una amplia variedad de marcos. Esto incluye editores de código básicos de Python, comandos emitidos desde el shell de Python de su terminal, entornos interactivos como Spyder, PyCharm, Atom y muchos otros. Los ejemplos prácticos y los comandos de este tutorial se presentan con Jupyter Notebook.
Importación de la biblioteca Python Pandas
Para analizar y trabajar con datos, debe importar la biblioteca de Pandas en su entorno de Python. Inicie una sesión de Python e importe Pandas usando los siguientes comandos:
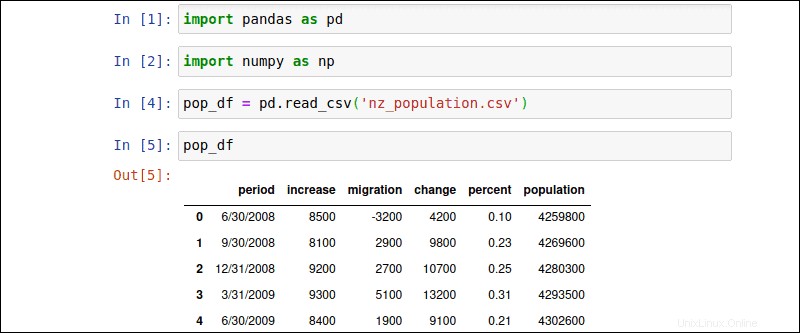
import pandas as pdimport numpy as np
Se considera una buena práctica importar pandas como pd y el numpy biblioteca científica como np . Esta acción te permite usar pd o np al escribir comandos. De lo contrario, sería necesario ingresar el nombre completo del módulo cada vez.

Es fundamental importar la biblioteca de Pandas cada vez que inicie un nuevo entorno de Python.
Series y DataFrames
Python Pandas utiliza Series y DataFrames para estructurar datos y prepararlos para diversas acciones analíticas. Estas dos estructuras de datos son la columna vertebral de la versatilidad de Pandas. Los usuarios que ya están familiarizados con las bases de datos relacionales comprenden de forma innata los conceptos y comandos básicos de Pandas.
Serie Pandas
Las series representan un objeto dentro de la biblioteca Pandas. Dan estructura a conjuntos de datos simples y unidimensionales emparejando cada elemento de datos con una etiqueta única. Una serie consta de dos matrices:la principal matriz que contiene los datos y el índice matriz que contiene las etiquetas emparejadas.
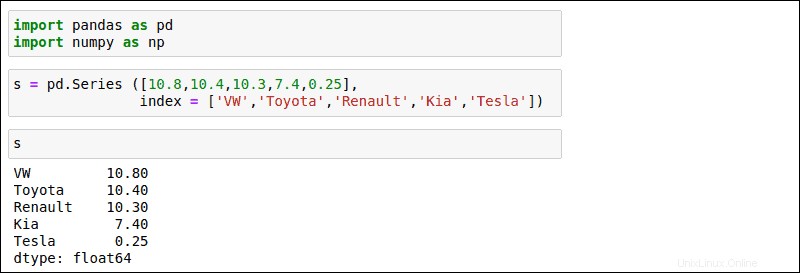
Utilice el siguiente ejemplo para crear una Serie básica. En este ejemplo, la Serie estructura los números de venta de automóviles indexados por fabricante:
s = pd.Series([10.8,10.7,10.3,7.4,0.25],
index = ['VW','Toyota','Renault','KIA','Tesla')
Después de ejecutar el comando, escriba s para ver la serie que acaba de crear. El resultado enumera los fabricantes según el orden en que se ingresaron.
Puede realizar un conjunto de funciones complejas y variadas en Series, incluidas funciones matemáticas, manipulación de datos y operaciones aritméticas entre Series. Una lista completa de parámetros, atributos y métodos de Pandas está disponible en la página oficial de Pandas.
Marcos de datos de Pandas
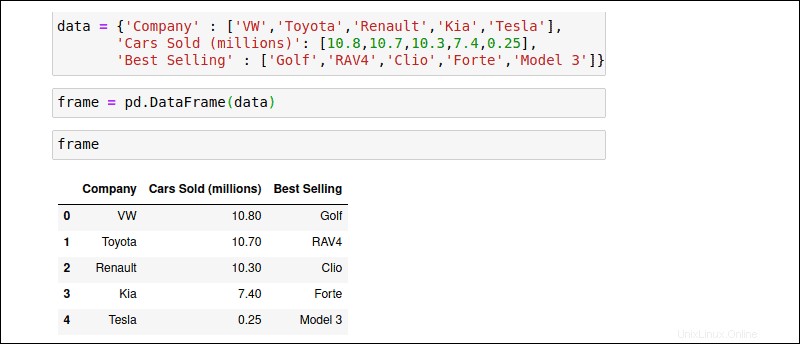
El DataFrame introduce una nueva dimensión a la estructura de datos de la Serie. Además de la matriz de índices, un conjunto de columnas estrictamente organizadas proporciona a los marcos de datos una estructura similar a una tabla. Cada columna puede almacenar un tipo de datos diferente. Intente crear manualmente un dict objeto llamado 'datos' con los mismos datos de ventas de automóviles:
data = { 'Company' : ['VW','Toyota','Renault','KIA','Tesla'],
'Cars Sold (millions)' : [10.8,10.7,10.3,7.4,0.25],
'Best Selling Model' : ['Golf','RAV4','Clio','Forte','Model 3']}
Pase el objeto 'datos' a pd.DataFrame() constructor:
frame = pd.DataFrame(data)
Use el nombre del DataFrame, frame , para ejecutar el objeto:
frameEl DataFrame resultante formatea los valores en filas y columnas.
La estructura de DataFrame le permite seleccionar y filtrar valores en función de columnas y filas, asignar nuevos valores y transponer los datos. Al igual que con Series, la página oficial de Pandas proporciona una lista completa de parámetros, atributos y métodos de DataFrame.
Leer y escribir con pandas
A través de Series y DataFrames, Pandas presenta un conjunto de funciones que permiten a los usuarios importar archivos de texto, formatos binarios complejos e información almacenada en bases de datos. La sintaxis para leer y escribir datos en Pandas es sencilla:
pd.read_filetype = (filename or path)– importar datos de otros formatos a Pandas.df.to_filetype = (filename or path)– exportar datos de Pandas a otros formatos.
Los formatos más comunes incluyen CSV , XLXS ,
| Leer | Escribir |
|---|---|
| pd.read_csv (‘nombre de archivo.csv’) | df.to_csv (‘nombre de archivo o ruta’) |
| pd.read_excel (‘nombre de archivo.xlsx’) | df.to_excel (‘nombre de archivo o ruta’) |
| pd.read_json (‘nombre de archivo.json’) | df.to_json ('nombre de archivo o ruta') |
| pd.read_html (‘nombre de archivo.htm’) | df.to_html (‘nombre de archivo o ruta’) |
| pd.read_sql (‘nombre de tabla’) | df.to_sql ('Nombre de la base de datos') |