Introducción
Aprender a crear un Spark DataFrame es uno de los primeros pasos prácticos en el entorno de Spark. Spark DataFrames ayuda a proporcionar una vista de la estructura de datos y otras funciones de manipulación de datos. Existen diferentes métodos según la fuente de datos y el formato de almacenamiento de datos de los archivos.
Este artículo explica cómo crear un Spark DataFrame manualmente en Python usando PySpark.

Requisitos previos
- Python 3 instalado y configurado.
- PySpark instalado y configurado.
- Un entorno de desarrollo de Python listo para probar los ejemplos de código (estamos usando Jupyter Notebook).
Métodos para crear Spark DataFrame
Hay tres formas de crear un DataFrame en Spark a mano:
1. Cree una lista y analícela como un DataFrame usando toDataFrame() método de SparkSession .
2. Convierta un RDD en un DataFrame usando toDF() método.
3. Importa un archivo a una SparkSession como DataFrame directamente.
Los ejemplos usan datos de muestra y un RDD para demostración, aunque los principios generales se aplican a estructuras de datos similares.
Crear DataFrame a partir de una lista de datos
Para crear un Spark DataFrame a partir de una lista de datos:
1. Genere una lista de diccionario de muestra con datos de juguetes:
data = [{"Category": 'A', "ID": 1, "Value": 121.44, "Truth": True},
{"Category": 'B', "ID": 2, "Value": 300.01, "Truth": False},
{"Category": 'C', "ID": 3, "Value": 10.99, "Truth": None},
{"Category": 'E', "ID": 4, "Value": 33.87, "Truth": True}
]
2. Importa y crea una SparkSession :
from pyspark.sql import SparkSession
spark = SparkSession.builder.getOrCreate()
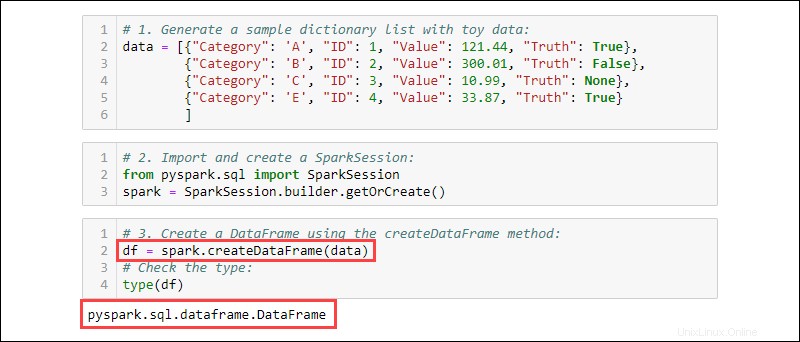
3. Cree un DataFrame usando createDataFrame método. Verifique el tipo de datos para confirmar que la variable es un DataFrame:
df = spark.createDataFrame(data)
type(df)
Crear marco de datos desde RDD
Un evento típico cuando se trabaja en Spark es crear un DataFrame a partir de un RDD existente. Cree un RDD de muestra y luego conviértalo en un DataFrame.
1. Haz una lista de diccionario que contenga datos de juguetes:
data = [{"Category": 'A', "ID": 1, "Value": 121.44, "Truth": True},
{"Category": 'B', "ID": 2, "Value": 300.01, "Truth": False},
{"Category": 'C', "ID": 3, "Value": 10.99, "Truth": None},
{"Category": 'E', "ID": 4, "Value": 33.87, "Truth": True}
]
2. Importe y cree un SparkContext :
from pyspark import SparkContext, SparkConf
conf = SparkConf().setAppName("projectName").setMaster("local[*]")
sc = SparkContext.getOrCreate(conf)
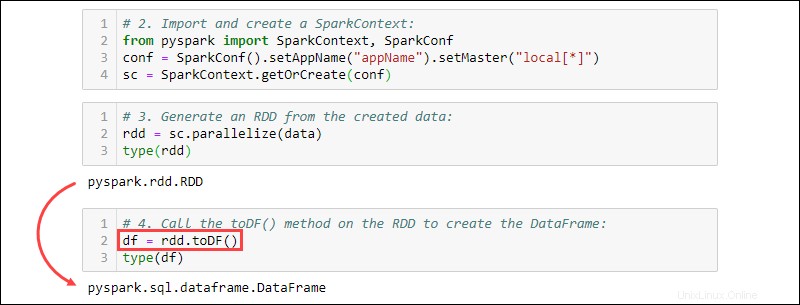
3. Genere un RDD a partir de los datos creados. Verifique el tipo para confirmar que el objeto es un RDD:
rdd = sc.parallelize(data)
type(rdd)
4. Llame al toDF() en el RDD para crear el DataFrame. Pruebe el tipo de objeto para confirmar:
df = rdd.toDF()
type(df)
Crear marco de datos a partir de fuentes de datos
Spark puede manejar una amplia gama de fuentes de datos externas para construir DataFrames. La sintaxis general para leer desde un archivo es:
spark.read.format('<data source>').load('<file path/file name>')El nombre y la ruta del origen de datos son tipos de cadena. Las fuentes de datos específicas también tienen una sintaxis alternativa para importar archivos como marcos de datos.
Crear desde un archivo CSV
Cree un Spark DataFrame leyendo directamente desde un archivo CSV:
df = spark.read.csv('<file name>.csv')Lea varios archivos CSV en un DataFrame proporcionando una lista de rutas:
df = spark.read.csv(['<file name 1>.csv', '<file name 2>.csv', '<file name 3>.csv'])
De forma predeterminada, Spark agrega un encabezado para cada columna. Si un archivo CSV tiene un encabezado que desea incluir, agregue la option método al importar:
df = spark.read.csv('<file name>.csv').option('header', 'true')
Pilas de opciones individuales llamándolas una tras otra. Alternativamente, use las options método cuando se necesitan más opciones durante la importación:
df = spark.read.csv('<file name>.csv').options(header = True)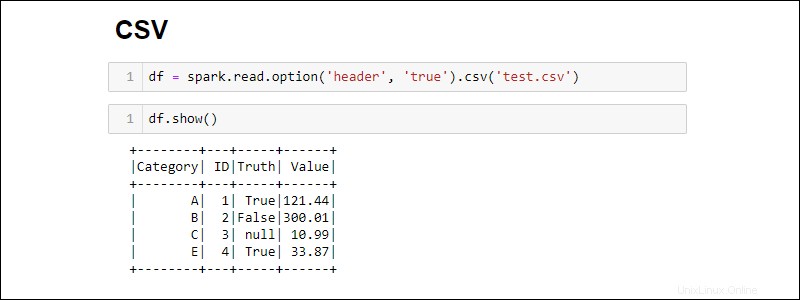
Observe que la sintaxis es diferente cuando se usa option frente a options .
Crear desde un archivo TXT
Cree un DataFrame a partir de un archivo de texto con:
df = spark.read.text('<file name>.txt')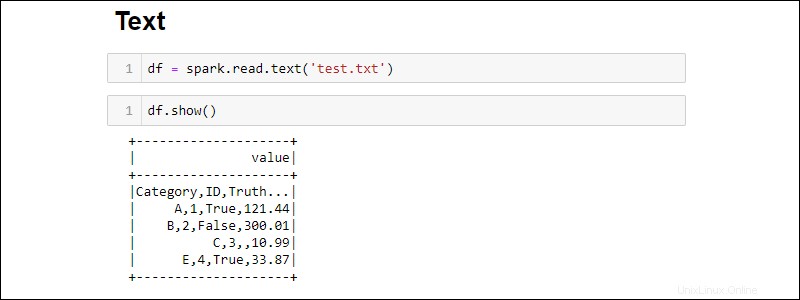
El csv El método es otra forma de leer desde un txt tipo de archivo en un DataFrame. Por ejemplo:
df = spark.read.option('header', 'true').csv('<file name>.txt')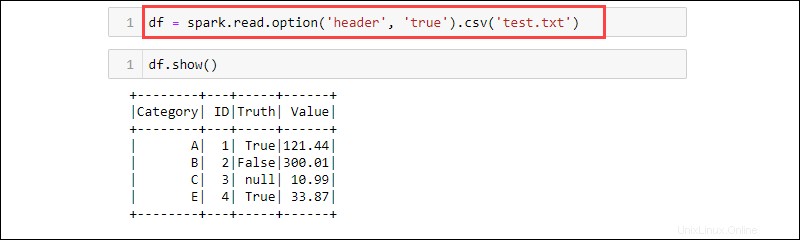
CSV es un formato de texto donde el delimitador es una coma (,) y, por lo tanto, la función puede leer datos de un archivo de texto.
Crear desde un archivo JSON
Cree un Spark DataFrame a partir de un archivo JSON ejecutando:
df = spark.read.json('<file name>.json')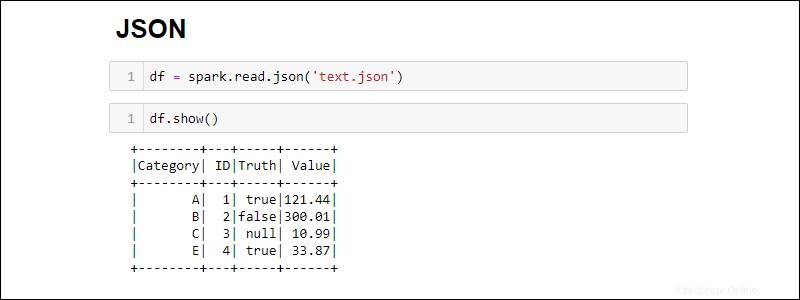
Crear desde un archivo XML
La compatibilidad con archivos XML no está disponible de forma predeterminada. Instale las dependencias para crear un DataFrame desde una fuente XML.
1. Descargue la dependencia XML de Spark. Guarde el .jar archivo en la carpeta Spark jar.
2. Lea un archivo XML en un DataFrame ejecutando:
df = spark.read\
.format('com.databricks.spark.xml')\
.option('rowTag', 'row')\
.load('test.xml')
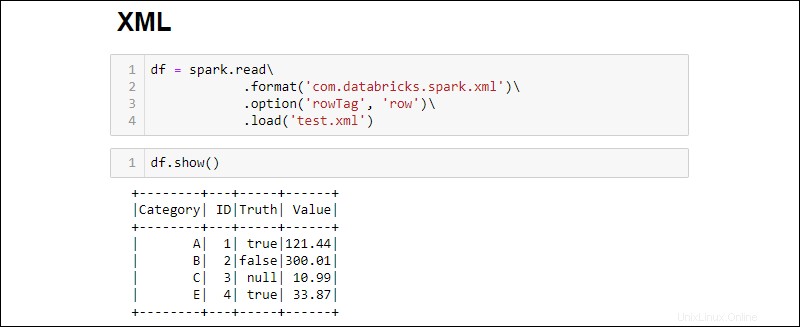
Cambiar la rowTag opción si cada fila en su XML el archivo tiene una etiqueta diferente.
Crear marco de datos desde la base de datos RDBMS
Leer desde un RDBMS requiere un conector de controlador. El ejemplo explica cómo conectarse y extraer datos de una base de datos MySQL. Pasos similares funcionan para otros tipos de bases de datos.
1. Descargue el conector del controlador MySQL Java. Guarde el .jar archivo en la carpeta Spark jar.
2. Ejecute el servidor SQL y establezca una conexión.
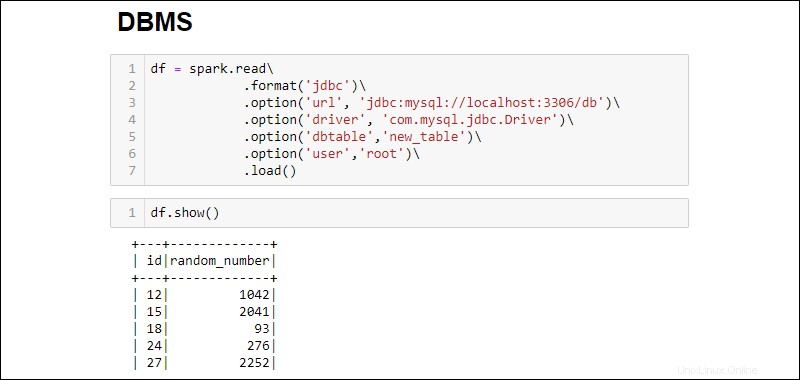
3. Establezca una conexión y busque toda la tabla de la base de datos MySQL en un DataFrame:
df = spark.read\
.format('jdbc')\
.option('url', 'jdbc:mysql://localhost:3306/db')\
.option('driver', 'com.mysql.jdbc.Driver')\
.option('dbtable','new_table')\
.option('user','root')\
.load()
Las opciones añadidas son las siguientes:
- La URL es
localhost:3306si el servidor se ejecuta localmente. De lo contrario, obtenga la URL de su servidor de base de datos. - Nombre de la base de datos extiende la URL para acceder a una base de datos específica en el servidor. Por ejemplo, si una base de datos se llama
dby el servidor se ejecuta localmente, la URL completa para establecer una conexión esjdbc:mysql://localhost:3306/db. - Nombre de la tabla asegura que toda la tabla de la base de datos se introduzca en el DataFrame. Utilice
.option('query', '<query>')en lugar de.option('dbtable', '<table name>')para ejecutar una consulta específica en lugar de seleccionar una tabla completa. - Usar el nombre de usuario y contraseña de la base de datos para establecer la conexión. Cuando se ejecuta sin contraseña, omita la opción especificada.