
En este tutorial, le mostraremos cómo instalar Apache Hadoop en Ubuntu 20.04 LTS. Para aquellos de ustedes que no lo sabían, Apache Hadoop es un marco de código abierto que se utiliza para el almacenamiento distribuido. así como el procesamiento distribuido de big data en clústeres de computadoras que se ejecutan en hardware básico. En lugar de depender del hardware para brindar alta disponibilidad, la biblioteca en sí está diseñada para detectar y manejar fallas en la capa de aplicación, por lo que brinda un servicio de alta disponibilidad. encima de un grupo de computadoras, cada una de las cuales puede ser propensa a fallar.
Este artículo asume que tiene al menos conocimientos básicos de Linux, sabe cómo usar el shell y, lo que es más importante, aloja su sitio en su propio VPS. La instalación es bastante simple y asume que se están ejecutando en la cuenta raíz, si no, es posible que deba agregar 'sudo ' a los comandos para obtener privilegios de root. Te mostraré la instalación paso a paso de Flask en Ubuntu 20.04 (Focal Fossa). Puede seguir las mismas instrucciones para Ubuntu 18.04, 16.04 y cualquier otra distribución basada en Debian como Linux Mint.
Requisitos previos
- Un servidor que ejecuta uno de los siguientes sistemas operativos:Ubuntu 20.04, 18.04, 16.04 y cualquier otra distribución basada en Debian como Linux Mint.
- Se recomienda que utilice una instalación de sistema operativo nueva para evitar posibles problemas.
- Acceso SSH al servidor (o simplemente abra Terminal si está en una computadora de escritorio).
- Un
non-root sudo usero acceder alroot user. Recomendamos actuar como unnon-root sudo user, sin embargo, puede dañar su sistema si no tiene cuidado al actuar como root.
Instalar Apache Hadoop en Ubuntu 20.04 LTS Focal Fossa
Paso 1. Primero, asegúrese de que todos los paquetes de su sistema estén actualizados ejecutando el siguiente apt comandos en la terminal.
sudo apt update sudo apt upgrade
Paso 2. Instalación de Java.
Para ejecutar Hadoop, debe tener Java 8 instalado en su máquina. Para hacerlo, use el siguiente comando:
sudo apt install default-jdk default-jre
Una vez instalado, puede verificar la versión instalada de Java con el siguiente comando:
java -version
Paso 3. Cree un usuario de Hadoop.
Primero, cree un nuevo usuario llamado Hadoop con el siguiente comando:
sudo addgroup hadoopgroup sudo adduser —ingroup hadoopgroup hadoopuser
Luego, inicie sesión con un usuario de Hadoop y genere un par de claves SSH con el siguiente comando:
su - hadoopuser ssh-keygen -t rsa cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys chmod 0600 ~/.ssh/authorized_keys
Después de eso, verifique el SSH sin contraseña con el siguiente comando:
ssh localhost
Una vez que haya iniciado sesión sin contraseña, puede continuar con el siguiente paso.
Paso 4. Instalación de Apache Hadoop en Ubuntu 20.04.
Ahora descargamos la última versión estable de Apache Hadoop, al momento de escribir este artículo es la versión 3.3.0:
su - hadoop wget https://downloads.apache.org/hadoop/common/hadoop-3.3.0/hadoop-3.3.0.tar.gz tar -xvzf hadoop-3.3.0.tar.gz
Luego, mueva el directorio extraído a /usr/local/ :
sudo mv hadoop-3.3.0 /usr/local/hadoop sudo mkdir /usr/local/hadoop/logs
Cambiamos la propiedad del directorio de Hadoop a Hadoop:
sudo chown -R hadoop:hadoop /usr/local/hadoop
Paso 5. Configure Apache Hadoop.
Configurando las variables de entorno. Edite ~/.bashrc el archivo y agregue los siguientes valores al final del archivo:
nano ~/.bashrc
Agregue las siguientes líneas:
export HADOOP_HOME=/usr/local/hadoop export HADOOP_INSTALL=$HADOOP_HOME export HADOOP_MAPRED_HOME=$HADOOP_HOME export HADOOP_COMMON_HOME=$HADOOP_HOME export HADOOP_HDFS_HOME=$HADOOP_HOME export YARN_HOME=$HADOOP_HOME export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib/native"
Aplicar variables ambientales a la sesión que se está ejecutando actualmente:
source ~/.bashrc
A continuación, deberá definir las variables de entorno de Java en hadoop-env.sh para configurar los ajustes de proyectos relacionados con YARN, HDFS, MapReduce y Hadoop:
sudo nano $HADOOP_HOME/etc/hadoop/hadoop-env.sh
Agregue las siguientes líneas:
export JAVA_HOME=/usr/lib/jvm/java-11-openjdk-amd64 export HADOOP_CLASSPATH+=" $HADOOP_HOME/lib/*.jar"
Ahora puede verificar la versión de Hadoop usando el siguiente comando:
hadoop version
Paso 6. Configure core-site.xml archivo.
Abra el core-site.xml archivo en un editor de texto:
sudo nano $HADOOP_HOME/etc/hadoop/core-site.xml
Agregue las siguientes líneas:
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://0.0.0.0:9000</value>
<description>The default file system URI</description>
</property>
</configuration>
Paso 7. Configure hdfs-site.xml Archivo.
Use el siguiente comando para abrir hdfs-site.xml archivo para editar:
sudo nano $HADOOP_HOME/etc/hadoop/hdfs-site.xml
Agregue las siguientes líneas:
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.name.dir</name>
<value>file:///home/hadoop/hdfs/namenode</value>
</property>
<property>
<name>dfs.data.dir</name>
<value>file:///home/hadoop/hdfs/datanode</value>
</property>
</configuration>
Paso 8. Configure mapred-site.xml Archivo.
Use el siguiente comando para acceder al mapred-site.xml archivo:
sudo nano $HADOOP_HOME/etc/hadoop/mapred-site.xml
Agregue las siguientes líneas:
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
Paso 9. Configure yarn-site.xml Archivo.
Abra el yarn-site.xml archivo en un editor de texto:
sudo nano $HADOOP_HOME/etc/hadoop/yarn-site.xml
Agregue las siguientes líneas:
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration> Paso 10. Dar formato a HDFS NameNode.
Ahora iniciamos sesión con un usuario de Hadoop y formateamos el NameNode de HDFS con el siguiente comando:
su - hadoop hdfs namenode -format
Paso 11. Inicie el clúster de Hadoop.
Ahora inicie NameNode y DataNode con el siguiente comando:
start-dfs.sh
Luego, inicie el recurso YARN y los administradores de nodos:
start-yarn.sh
Debe observar la salida para asegurarse de que intenta iniciar el nodo de datos en los nodos esclavos uno por uno. Para verificar si todos los servicios se iniciaron correctamente, use 'jps ‘ comando:
jps
Paso 12. Acceso a Apache Hadoop.
El número de puerto predeterminado 9870 le da acceso a la interfaz de usuario de Hadoop NameNode:
http://your-server-ip:9870
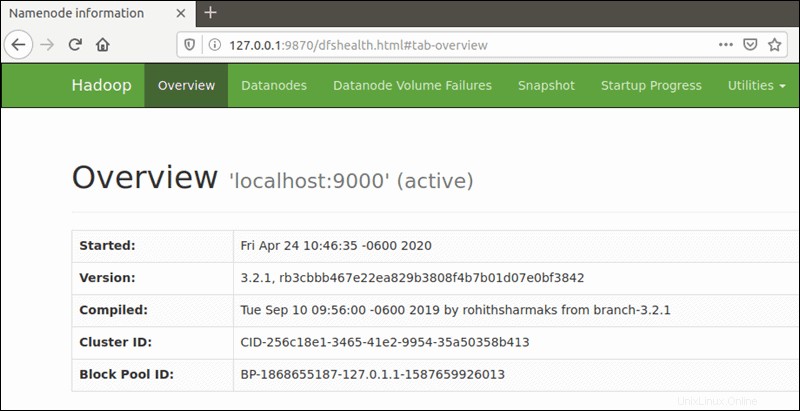
El puerto predeterminado 9864 se usa para acceder a DataNodes individuales directamente desde su navegador:
http://your-server-ip:9864
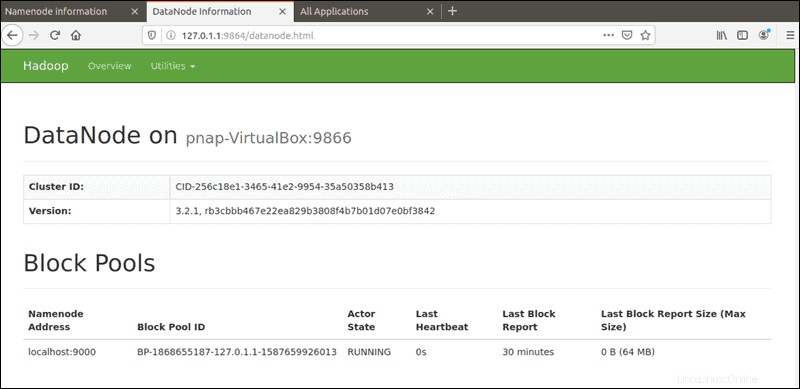
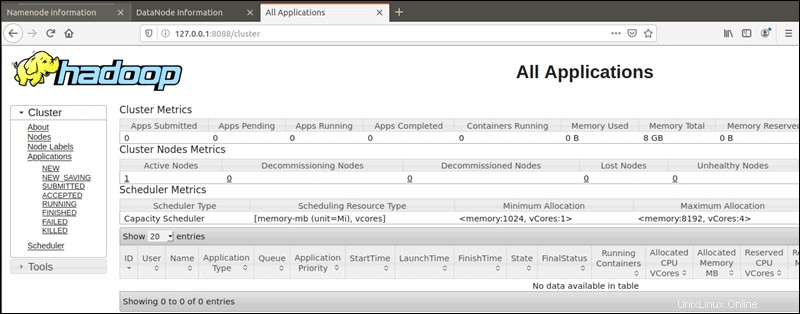
Se puede acceder al administrador de recursos de YARN en el puerto 8088:
http://your-server-ip:8088
¡Felicitaciones! Has instalado correctamente Hadoop. Gracias por usar este tutorial para instalar Apache Hadoop en tu sistema Ubuntu 20.04 LTS Focal Fossa. Para obtener ayuda adicional o información útil, te recomendamos que consultes el sitio web oficial Sitio web de Apache Hadoop.