¿Qué es Apache Kafka?
Kafka es un sistema de mensajería que recopila y procesa grandes cantidades de datos en tiempo real, lo que lo convierte en un componente de integración vital para las aplicaciones que se ejecutan en un clúster de Kubernetes. La eficiencia de las aplicaciones implementadas en un clúster se puede aumentar aún más con una plataforma de transmisión de eventos como Apache Kafka. .
Este tutorial detallado le muestra cómo configurar un servidor Kafka en un clúster de Kubernetes.

¿Cómo funciona Apache Kafka?
Apache Kafka se basa en un modelo de publicación y suscripción:
- Productores producir mensajes y publicarlos en temas .
- Kafka clasifica los mensajes en temas y los almacena para que sean inmutables.
- Los consumidores se suscriben a un tema específico y absorber los mensajes proporcionados por los productores.
Los productores y consumidores en este contexto representan aplicaciones que producen mensajes basados en eventos y aplicaciones que consumen esos mensajes. Los mensajes se almacenan en los agentes de Kafka, ordenados por temas definidos por el usuario .
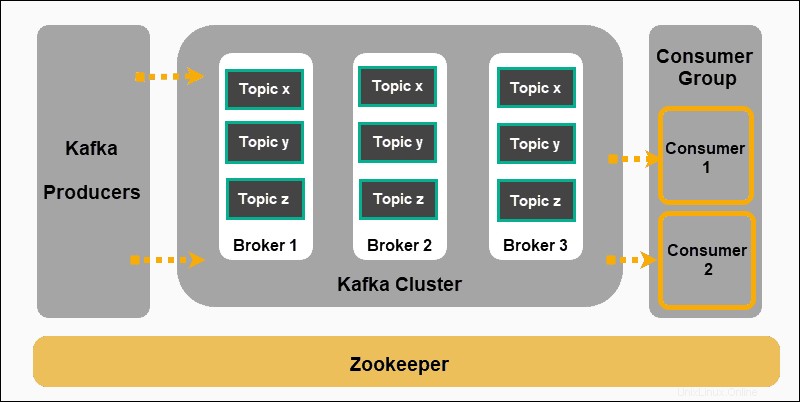
Zookeeper es un componente indispensable de una configuración de Kafka. Coordina a los productores, intermediarios, consumidores y miembros de clústeres de Kafka.
Implementar Zookeeper
Kafka no puede funcionar sin Zookeeper. El servicio de Kafka sigue reiniciando hasta que se detecta una implementación de Zookeeper en funcionamiento.
Implemente Zookeeper de antemano creando un archivo YAML zookeeper.yml . Este archivo inicia un servicio y una implementación que programan pods de Zookeeper en un clúster de Kubernetes.
Use su editor de texto preferido para agregar los siguientes campos a zookeeper.yml :
apiVersion: v1
kind: Service
metadata:
name: zk-s
labels:
app: zk-1
spec:
ports:
- name: client
port: 2181
protocol: TCP
- name: follower
port: 2888
protocol: TCP
- name: leader
port: 3888
protocol: TCP
selector:
app: zk-1
---
kind: Deployment
apiVersion: extensions/v1beta1
metadata:
name: zk-deployment-1
spec:
template:
metadata:
labels:
app: zk-1
spec:
containers:
- name: zk1
image: bitnami/zookeeper
ports:
- containerPort: 2181
env:
- name: ZOOKEEPER_ID
value: "1"
- name: ZOOKEEPER_SERVER_1
value: zk1
Ejecute el siguiente comando en su clúster de Kubernetes para crear el archivo de definición:
kubectl create -f zookeeper.ymlCrear servicio Kafka
Ahora necesitamos crear un archivo de definición de Kafka Service. Este archivo administra las implementaciones de Kafka Broker equilibrando la carga de los nuevos pods de Kafka. Un kafka-service.yml básico El archivo contiene los siguientes elementos:
apiVersion: v1
kind: Service
metadata:
labels:
app: kafkaApp
name: kafka
spec:
ports:
-
port: 9092
targetPort: 9092
protocol: TCP
-
port: 2181
targetPort: 2181
selector:
app: kafkaApp
type: LoadBalancer
Una vez que haya guardado el archivo, cree el servicio ingresando el siguiente comando:
kubectl create -f kafka-service.ymlDefinir el controlador de replicación de Kafka
Cree un .yml adicional para que sirva como controlador de replicación para Kafka. Un archivo de controlador de replicación, en nuestro ejemplo kafka-repcon.yml, contiene los siguientes campos:
---
apiVersion: v1
kind: ReplicationController
metadata:
labels:
app: kafkaApp
name: kafka-repcon
spec:
replicas: 1
selector:
app: kafkaApp
template:
metadata:
labels:
app: kafkaApp
spec:
containers:
-
command:
- zookeeper-server-start.sh
- /config/zookeeper.properties
image: "wurstmeister/kafka"
name: zk1
ports:
-
containerPort: 2181
Guarde el archivo de definición del controlador de replicación y créelo con el siguiente comando:
kubectl create -f kafka-repcon.ymlIniciar servidor Kafka
Las propiedades de configuración para un servidor Kafka se definen en config/server.properties expediente. Como ya hemos configurado el servidor Zookeeper, inicie el servidor Kafka con:
kafka-server-start.sh config/server.propertiesCómo crear un tema de Kafka
Kafka tiene una utilidad de línea de comandos llamada kafka-topics.sh . Utilice esta utilidad para crear temas en el servidor. Abra una nueva ventana de terminal y escriba:
kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic Topic-NameCreamos un tema llamado Topic-Name con una única partición y una instancia de réplica.
Cómo iniciar un productor de Kafka
config/server.properties El archivo contiene la identificación del puerto del intermediario. El intermediario en el ejemplo está escuchando en el puerto 9092. Es posible especificar el puerto de escucha directamente usando la línea de comando:
kafka-console-producer.sh --topic kafka-on-kubernetes --broker-list localhost:9092 --topic Topic-Name Ahora usa la terminal para agregar varias líneas de mensajes.
Cómo iniciar un consumidor de Kafka
Al igual que con las propiedades del Productor, la configuración predeterminada del Consumidor se especifica en config/consumer.properties expediente. Abra una nueva ventana de terminal y escriba el comando para consumir mensajes:
kafka-console-consumer.sh --topic Topic-Name --from-beginning --zookeeper localhost:2181
El --from-beginning El comando enumera los mensajes cronológicamente. Ahora puede ingresar mensajes desde la terminal del productor y verlos aparecer en la terminal del consumidor.
Cómo escalar un clúster de Kafka
Utilice el terminal de comandos y administre directamente Kafka Cluster mediante kubectl . Ingrese el siguiente comando y escale su clúster de Kafka rápidamente aumentando la cantidad de pods de uno (1) a seis (6):
kubectl scale rc kafka-rc --replicas=6