Introducción
Las funciones de cadena de MySQL permiten a los usuarios manipular cadenas de datos o consultar información sobre una cadena devuelta por SELECT consulta.
En este artículo, aprenderá a utilizar las funciones de cadena de MySQL.

Requisitos previos
- MySQL Server y MySQL Shell instalados
- Una cuenta de usuario de MySQL con privilegios de root
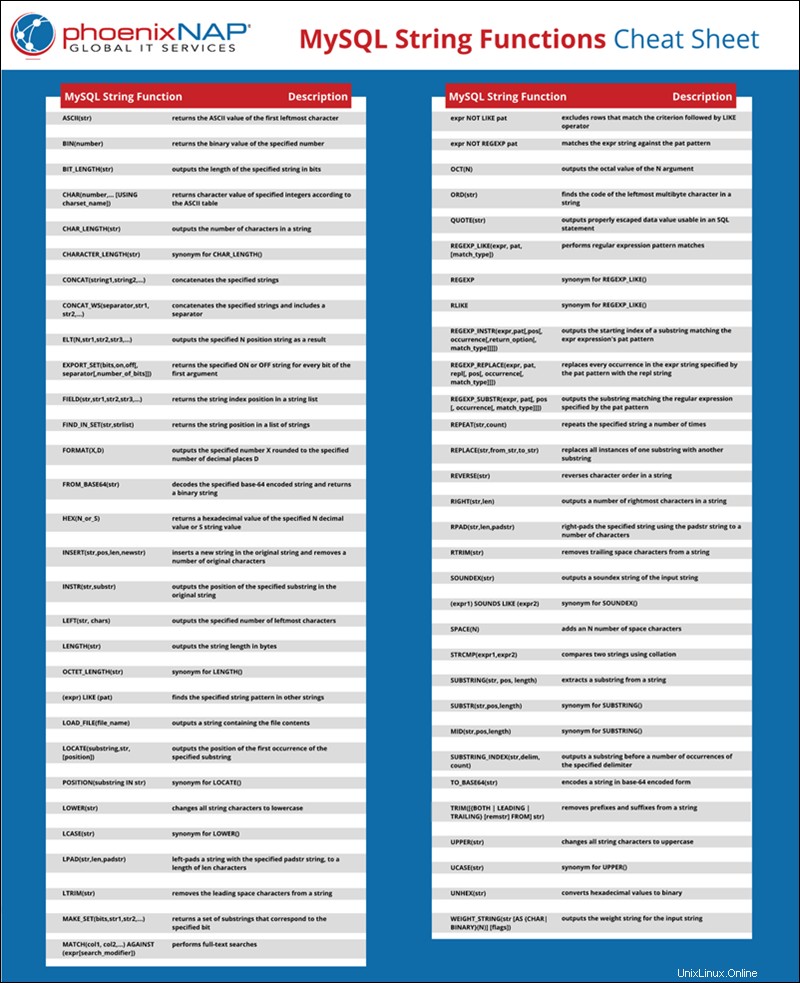
Hoja de referencia de funciones de cadena de MySQL
Cada función de cadena se explica y ejemplifica en el siguiente artículo. Si le resulta más conveniente, puede guardar la hoja de trucos en formato PDF haciendo clic en Descargar hoja de trucos de MySQL String Functions. enlace.
Descargue la hoja de referencia de funciones de cadenas de MySQL
ASCII()
La sintaxis del ASCII() la función es:
ASCII('str')
El ASCII() string devuelve el valor ASCII (numérico) del carácter más a la izquierda del str especificado cuerda. La función devuelve 0 si no str está especificado. Devuelve NULL si str es NULL .
Usa ASCII() para caracteres con valores numéricos de 0 a 255.
Por ejemplo:

En este ejemplo, el ASCII() la función devuelve el valor numérico de p , el carácter más a la izquierda del str especificado cadena.
BIN()
La sintaxis de BIN() la función es:
BIN(number)
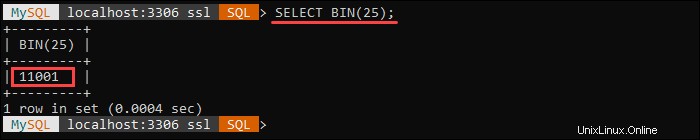
El BIN() la función devuelve un valor binario del number especificado argumento, donde el number es un BIGINTEGER número. Devuelve NULL si el number el argumento es NULL .
Por ejemplo, la siguiente consulta devuelve una representación binaria del número 25:
BIT_LENGTH()
La sintaxis de BIT_LENGTH() la función es:
BIT_LENGTH('str')
La función genera la longitud del str especificado cadena en bits.
Por ejemplo, la siguiente consulta devuelve la longitud en bits del 'ejemplo especificado ' cadena:

CARÁCTER()
La sintaxis de CHAR() la función es:
CHAR(number,... [USING charset_name])
CHAR() interpreta cada number especificado argumento como un entero y genera una cadena binaria de caracteres de la tabla ASCII. La función salta NULL valores.
Por ejemplo:

Si desea producir una salida que no sea binaria, use el USING opcional cláusula y especifique el juego de caracteres deseado. MySQL emite una advertencia si la cadena de resultados no es válida para el conjunto de caracteres especificado.
CHAR_LENGTH(), es decir, CHARACTER_LENGTH()
La sintaxis para CHAR_LENGTH la función es:
CHAR_LENGTH(str)
La función genera la longitud del str especificado cadena, medida en caracteres.
CHAR_LENGTH() trata un carácter multibyte como un solo carácter, lo que significa que una cadena que contiene cuatro caracteres de 2 bytes devuelve 4 como resultado, mientras que LENGTH() devuelve 8.
Por ejemplo:

CHARACTER_LENGTH() es un sinónimo de CHAR_LENGTH() .
CONCAT()
El CONCAT() La función concatena dos o más cadenas especificadas. La sintaxis es:
CONCAT(string1,string2,...)
El CONCAT La función convierte todos los argumentos al tipo de cadena antes de concatenar. Si todos los argumentos son cadenas no binarias, el resultado es una cadena no binaria. Por otro lado, la concatenación de cadenas binarias da como resultado una cadena binaria. Un argumento numérico se convierte a su forma de cadena no binaria equivalente.
Si alguno de los argumentos especificados es NULL , CONCAT() devuelve NULL como resultado.
Por ejemplo:

La función une las cadenas especificadas en una, en este caso, 'phoenixNAP '.
CONCAT_WS()
La sintaxis de CONCAT_WS() es:
CONCAT_WS(separator,str1,str2,...)
CONCAT_WS() es una forma especial de CONCAT() que junta dos o más expresiones e incluye un separador. El separador divide las cadenas que desea concatenar. Si el separador es NULL , el resultado es NULL .
Por ejemplo:

En este ejemplo, el separador es un espacio en blanco que separa las cadenas especificadas en la salida.
ELT()
La sintaxis para el ELT() la función es:
ELT(N,str1,str2,str3,...)
El N El argumento define cuál de las cadenas especificadas se devolverá como resultado. ELT() devuelve NULL si N es menor que 1 o mayor que el número de cadenas especificadas.
Por ejemplo:

EXPORTAR_SET()
La sintaxis de EXPORT_SET() es:
EXPORT_SET(bits,on,off[,separator[,number_of_bits]])
El EXPORT_SET() la función devuelve un ON o OFF cadena para cada bit del primer argumento, comprobando de derecha a izquierda. El argumento es un número entero, pero la función lo convierte en bits.
Si el bit es 1, la función devuelve ON cuerda. Si el bit es 0, la función devuelve OFF . EXPORT_SET() coloca un separador entre los valores devueltos. El separador predeterminado es una coma, pero puede especificar uno diferente como cuarto argumento.
Las cadenas se agregan al resultado de salida de izquierda a derecha, separadas por la cadena separadora. El number_of_bits argumento especifica cuántos bits examinar.
Por ejemplo:

Explicación:
1. Después de la conversión, el primer argumento 5 representa 00000101.
2. Comprobando de derecha a izquierda, el primer bit es 1, por lo que la función devuelve el 'Sí ' argumento (el ON cuerda). El segundo bit es 0, por lo que la función devuelve 'No ' (el OFF cuerda). Para el tercer bit, devuelve 'Sí .' Para todos los bits restantes (ceros), devuelve 'No .'
3. El cuarto argumento '- ' se especifica como separador en el resultado devuelto.
CAMPO()
La sintaxis para FIELD() la sintaxis es:
FIELD(str,str1,str2,str3,...)
La función devuelve la posición de índice de una cadena en una lista de cadenas. Si no existe tal cadena, la salida es 0. Si la cadena es NULL , la función devuelve 0. El FIELD() la función no distingue entre mayúsculas y minúsculas.
Por ejemplo:

La función devuelve 6, que es la posición de la cadena 'f ' en la lista.
FIND_IN_SET()
La sintaxis de FIND_IN_SET() la función es:
FIND_IN_SET(str,strlist)La función devuelve la posición de una cadena en una lista de cadenas. Si hay varias instancias de cadena, la salida devuelve solo la primera posición de la cadena especificada.
Por ejemplo:

FORMATO()
La sintaxis para FORMAT() la función es:
FORMAT(X,D)
La función genera el número especificado X en un formato como '#,###,###.##', redondeado al número especificado de lugares decimales D . El resultado no tiene punto decimal si D es 0.
Los usuarios también pueden especificar la configuración regional después de D argumento, que afecta la salida.
Por ejemplo:

La salida redondea el número a 3 lugares decimales y la configuración regional alemana genera un . símbolo para denotar miles y el , carácter para indicar fracciones.
DESDE_BASE64()
La sintaxis para FROM_BASE64() la función es:
FROM_BASE64(str)
La función decodifica la cadena codificada en base 64 especificada y devuelve el resultado como una cadena binaria. Si el argumento es NULL o una cadena de base 64 no válida, el resultado es NULL .
FROM_BASE64() es el reverso de TO_BASE64() como TO_BASE64() codifica una consulta en base64.
Por ejemplo:
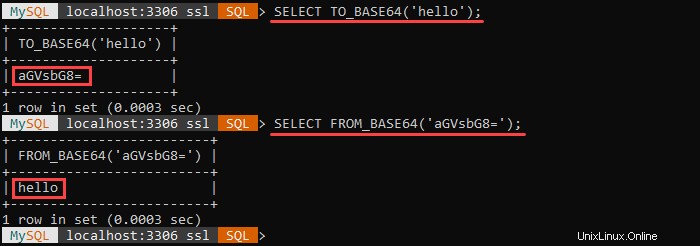
La primera consulta codifica la cadena especificada en base64. La segunda consulta decodifica la cadena codificada en base64 y devuelve el valor original.
HEXAGONAL()
La sintaxis de HEX() la función es:
HEX(N_or_S)
La función devuelve una representación de cadena de un valor hexadecimal del N especificado valor decimal o S valor de cadena.
Si el argumento es una str , HEX convierte cada carácter en dos dígitos hexadecimales. Por otro lado, si el argumento es un decimal , la salida es una representación de cadena hexadecimal del argumento y lo trata como BIGINTEGER número.
El HEX() la función de cadena es equivalente a la función matemática CONV(N,10,16) .
Por ejemplo:

La salida devuelve el valor hexadecimal de la cadena especificada.
INSERTAR()
La sintaxis de INSERT() la función es:
INSERT(str,pos,len,newstr)
La función inserta un newstr cadena dentro de str cadena y elimina el len número de caracteres originales a partir de pos posición.
Si el pos el argumento no está dentro de la longitud de la cadena original, INSERT() devuelve la cadena original.
Si el len el argumento no está dentro de la longitud del resto de la cadena, INSERT() reemplaza el resto de la cadena de pos posición.
Si algún argumento es NULL , INSERT() devuelve NULL .
Por ejemplo:

El resultado es la cadena original con la nueva cadena insertada en la posición 5, sin eliminar los caracteres originales.
INSTR()
La sintaxis de INSTR() la función es:
INSTR(str,substr)
La función genera la posición de la primera aparición del substr subcadena en el str original cadena.
La función funciona de la misma manera que LOCATE() , excepto que se invierte el orden de los argumentos.
Por ejemplo:

La salida indica la ubicación de la subcadena:posición 8.
IZQUIERDA()
La sintaxis de LEFT() la función es:
LEFT('str', chars)
La función genera el número de caracteres más a la izquierda chars de la str especificada cadena.
Si algún argumento es NULL , la salida también es NULL .
Por ejemplo:

LONGITUD(), es decir, OCTET_LENGTH()
La sintaxis de LENGTH() la función es:
LENGTH(str)
La función genera el str longitud de la cadena en bytes. Los caracteres de varios bytes cuentan como varios bytes.
Por ejemplo:

El OCTET_LENGTH() función es sinónimo de LENGTH() .
ME GUSTA
La sintaxis de LIKE la función es:
expr LIKE patLa función realiza la coincidencia de patrones al encontrar el patrón de cadena especificado dentro de otras cadenas.
LIKE admite comodines:
%-Coincide con cualquier número de caracteres, incluso cero._- Coincide exactamente con un carácter.
LIKE devuelve 1 (verdadero) o 0 (falso). Si expr expresión o pat el patrón es NULL , la salida también es NULL .
Por ejemplo:
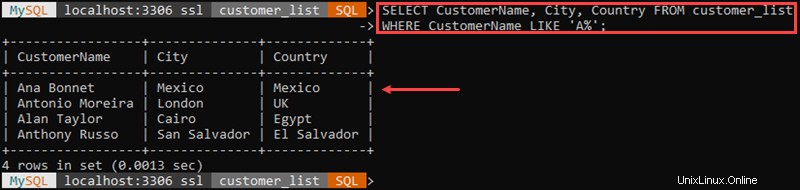
En este ejemplo, recuperamos todos los clientes cuyo nombre comienza con 'A '.
CARGAR_ARCHIVO()
La sintaxis de LOAD_FILE() la función es:
LOAD_FILE(file_name)La función lee el archivo y genera una cadena que contiene el contenido del archivo. Los requisitos previos para esta función son:
- Tener el archivo en el host del servidor.
- Especificar la ruta completa del archivo en lugar del argumento nombre_archivo.
- Tener el privilegio FILE .
El servidor debe poder leer el archivo y su tamaño debe ser inferior a max_allowed_packet bytes Si secure_file_priv variable del sistema es un nombre de directorio no vacío, coloque el archivo en ese directorio.
Si el archivo no existe o la función no puede leerlo por uno de los motivos anteriores, el resultado es NULL .
Por ejemplo:

LOCALIZAR(), es decir, POSICIONAR()
La sintaxis de LOCATE() la función es:
LOCATE(substring,str,[position])
La función genera la posición de la primera aparición de la substring especificada argumento dentro de str cuerda. La position El argumento es opcional y se usa para especificar de qué str posición de la cadena para comenzar a buscar. Omitir la position argumento comienza a buscar desde el principio.
Si la substring no está en str cadena, LOCATE() devuelve 0. Si algún argumento es NULL , la función devuelve NULL .
Por ejemplo:

La POSITION(substring IN str) función es un sinónimo de LOCATE(substr,str) .
INFERIOR(), es decir, LCASE()
La sintaxis de LOWER() la función es:
LOWER(str)
La función cambia todos los caracteres del str especificado cadena a minúsculas y emite el resultado. El mapeo de juego de caracteres predeterminado que usa es utf8mb4. LOWER() es multibyte seguro.
Por ejemplo:

El LCASE() función es sinónimo de LOWER() .
LPAD()
La sintaxis para LPAD() la función es:
LPAD(str,len,padstr)
La función genera el str especificado cadena, rellenada a la izquierda con padstr cadena, hasta una longitud de len caracteres. La función acorta la salida a len caracteres si str el argumento es más largo que len .
LPAD() es multibyte seguro.
Por ejemplo:

En este ejemplo, el LPAD() la función rellena a la izquierda el argumento especificado con el padstr especificado , hasta 10 caracteres.
LTRIM()
La sintaxis de LTRIM() la función es:
LTRIM(str)
La función genera el str especificado cadena sin los caracteres de espacio iniciales.
Por ejemplo:

MAKE_SET()
La sintaxis de MAKE_SET() la función es:
MAKE_SET(bits,str1,str2,...)
La función genera un valor establecido, es decir, una cadena que contiene las subcadenas especificadas con el bit correspondiente especificado en los bits argumento.
El str1 el argumento corresponde al bit 0, str2 corresponde al bit 1, etc. Si alguno de los argumentos es NULL , no aparecen en el resultado.
Por ejemplo:

En este ejemplo, el primer bit es 1, es decir, 001. El dígito más a la derecha es 1, por lo que la función devuelve 'phoenix .' El segundo bit es 2, es decir, 010, el número del medio es 1, por lo que la función devuelve 'NAP ', completando así la salida.
PARTIDO()
La sintaxis de MATCH() la función es:
MATCH(col1, col2,…) AGAINST(expr[search_modifier])
La función permite a los usuarios realizar búsquedas de texto completo especificando una lista de columnas separadas por comas. Introduzca una cadena que desee buscar en lugar de expr argumento.
El search_modifier El argumento es opcional e indica el tipo de búsqueda. Los valores aceptados son:
IN NATURAL LANGUAGE MODE(predeterminado)IN NATURAL LANGUAGE MODE WITH QUERY EXPANSIONIN BOOLEAN MODEWITH QUERY EXPANSION
Por ejemplo:
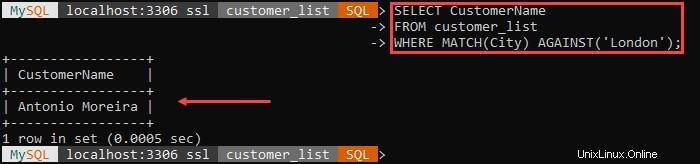
NO ME GUSTA
La sintaxis de NOT LIKE la función es:
expr NOT LIKE pat [ESCAPE 'escape_char']
NOT LIKE es una negación de LIKE , lo que significa que opera bajo las mismas condiciones que LIKE y utiliza los mismos comodines.
Por ejemplo:
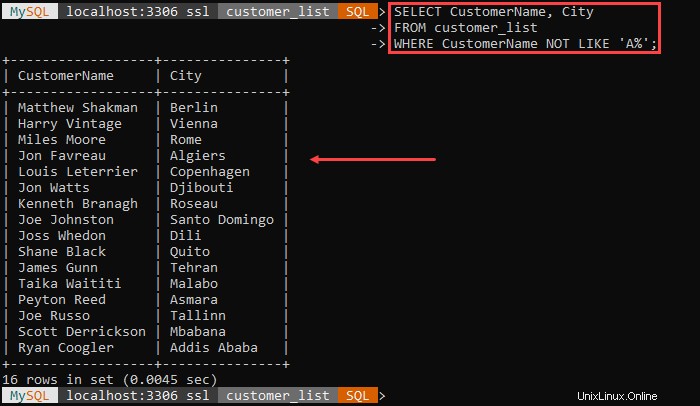
El resultado enumera todos los clientes y su ciudad excepto los clientes cuyo nombre comienza con 'A .'
NO REGEXP
La sintaxis para NOT REGEXP la función es:
expr NOT REGEXP pat
La función realiza una coincidencia de patrón de expr cadena contra el pat patrón. El patrón puede ser una expresión regular extendida.
NOT REGEXP es una negación de REGEXP .
Si expr el argumento coincide con pat argumento, la salida es 1. De lo contrario, la salida es 0. Si alguno de los argumentos es NULL , la salida es NULL .
Por ejemplo:
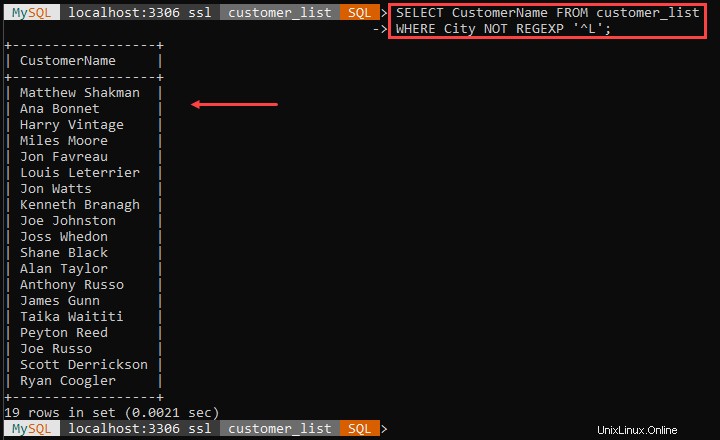
El ejemplo anterior genera todos los clientes que no viven en ciudades que comienzan con L. El '^ El carácter ' marca el inicio del nombre de la ciudad.
OCT()
La sintaxis de OCT() la función es:
OCT(N)
La función genera el valor octal del N especificado argumento, donde N es un BIGINTEGER número. Si N es NULL , la función devuelve NULL .
Por ejemplo:

ORD()
La sintaxis de ORD() la función es:
ORD(str)
La función encuentra el código del carácter multibyte más a la izquierda en una cadena. Si el carácter más a la izquierda no es multibyte, ORD() devuelve el valor ASCII del carácter.
La función calcula el código de carácter a partir de los valores numéricos de sus bytes constituyentes. La fórmula utilizada para esta operación es:
(código de 1er byte) + (código de 2do byte * 256) + (código de 3er byte * 256^2) ...
Por ejemplo:

COTIZACIÓN()
La sintaxis de QUOTE() la función es:
QUOTE(str)La función genera una cadena que representa el valor de datos con escape adecuado que se puede utilizar en una instrucción SQL. Las comillas simples encierran la cadena y contiene una barra invertida (\ ) antes de cada instancia de barra invertida (\ ), comillas simples (' ), ASCII NULO y Control+Z .
Si str el argumento es NULL , la salida es NULL .
Por ejemplo:
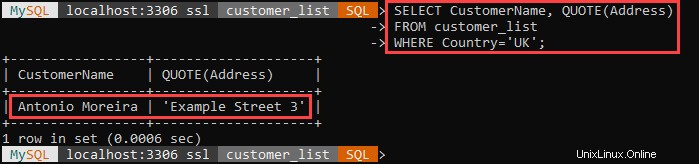
El ejemplo anterior selecciona todos los clientes que viven en el Reino Unido y encierra sus direcciones entre comillas simples.
REGEXP_LIKE(), REGEXP, RLIKE
La sintaxis de REGEXP_LIKE() la función es:
REGEXP_LIKE(expr, pat, [match_type])
La función genera 1 si expr cadena coincide con la expresión especificada en lugar de pat argumento. De lo contrario, la salida es 0. Si expr o pat el argumento es NULL , el valor de salida es NULL .
El match_type El argumento es opcional y representa una cadena que puede contener cualquiera o todas las siguientes marcas que especifican el tipo coincidente:
- Coincidencia que distingue entre mayúsculas y minúsculas (
c). Maneje los argumentos como cadenas binarias con distinción entre mayúsculas y minúsculas si cualquiera de los argumentos es una cadena binaria. Elcsignifica que se adopta la distinción entre mayúsculas y minúsculas incluso siitambién se especifica la bandera. - Coincidencia que no distingue entre mayúsculas y minúsculas (
i). Manejar los argumentos sin distinguir entre mayúsculas y minúsculas. - Modo de varias líneas (
m). Reconocer los terminadores de línea dentro de la cadena. La configuración predeterminada es hacer coincidir los terminadores de línea solo al principio y al final de la expresión de cadena. El . el carácter coincide con los terminadores de línea ( n). Se utiliza para modificar el . (punto) para que coincida con los terminadores de línea. Por defecto, . paradas coincidentes al final de una línea.- Finales de línea exclusivos de Unix (
u). Terminaciones de línea exclusivas de Unix que reconocen únicamente el carácter de nueva línea mediante los operadores de coincidencia ., ^ y $.
Si se especifican banderas contradictorias dentro de match_type , el que está más a la derecha tiene prioridad.
REGEXP y RLIKE son sinónimos de REGEXP_LIKE() .
Por ejemplo:

En este ejemplo, la expresión regular puede especificar cualquier carácter en lugar del punto, por lo que la función genera un 1 para indicar una coincidencia.
REGEXP_INSTR()
La sintaxis de REGEXP_INSTR() la función es:
REGEXP_INSTR(expr, pat[, pos[, occurrence[, return_option[, match_type]]]])
La función genera el índice inicial de una subcadena que coincide con expr pat de la expresión patrón. Si no hay ninguna coincidencia, el resultado es 0. Si alguno de los argumentos es NULL , la salida es NULL . Los índices de caracteres comienzan en 1.
Los argumentos opcionales son:
pos- Especificar la posición enexprdonde comenzar la búsqueda. Si se omite, el valor predeterminado es 1.occurrence- Especifique qué ocurrencia de una coincidencia buscar. Si se omite, el valor predeterminado es 1.return_option- Qué tipo de posición devolver. Si se establece en 0,REGEXP_INSTR()devuelve la posición del primer carácter de la subcadena coincidente. Si se establece en 1,REGEXP_INSTR()devuelve la posición que sigue a la subcadena coincidente. Si se omite, el valor predeterminado es 0.match_type- Especifica cómo hacer coincidir. El argumento es el mismo que enREGEXP_LIKE()y toma las mismas banderas.
Por ejemplo:

En este ejemplo, hay una coincidencia y la subcadena comienza en la posición 1.
REGEXP_REPLACE()
La sintaxis de REGEXP_REPLACE() la función es:
REGEXP_REPLACE(expr, pat, repl[, pos[, occurrence[, match_type]]])
La función reemplaza cada ocurrencia en expr cadena especificada por pat patrón con repl cadena y genera la cadena resultante. Si hay una coincidencia, la salida es la cadena completa con los reemplazos. Si no hay ninguna coincidencia, la salida es la expr original cuerda. Si algún argumento es NULL , la salida es NULL .
El REGEXP_REPLACE() opcional los argumentos son:
pos- La posición enexprdonde comenzar la búsqueda. Si se omite, el valor predeterminado es 1.occurrence- Qué ocurrencia de coincidencia reemplazar. Si se omite, el valor predeterminado es 0 y reemplaza todas las ocurrencias.match_type- Especifica cómo hacer coincidir. El argumento es el mismo que enREGEXP_LIKE()y toma las mismas banderas.
Por ejemplo:

REGEXP_SUBSTR()
La sintaxis de REGEXP_SUBSTR() la función es:
REGEXP_SUBSTR(expr, pat[, pos[, occurrence[, match_type]]])
La función genera la subcadena de expr cadena que coincide con la expresión regular especificada por pat patrón. Si no hay ninguna coincidencia, el resultado es NULL . Si algún argumento es NULL , la salida es NULL .
Los argumentos opcionales son:
pos- La posición enexprdonde comenzar la búsqueda. Si se omite, el valor predeterminado es 1.occurrence- Qué ocurrencia de coincidencia reemplazar. Si se omite, el valor predeterminado es 1.match_type- Especifica cómo hacer coincidir. El argumento es el mismo que enREGEXP_LIKE()y toma las mismas banderas.
Por ejemplo:

En este ejemplo, el resultado genera la subcadena coincidente del expr especificado cadena.
REPETIR()
La sintaxis de REPEAT() la función es:
REPEAT(str,count)
La función genera una cadena que repite str cadena count veces. Si el count argumento es menor que 1, la función genera una cadena vacía. Si alguno de los argumentos es NULL , el resultado es NULL .
Por ejemplo:

En el ejemplo anterior, la función genera una cadena que consiste en 'Trabajo ' cadena repetida seis veces.
REEMPLAZAR()
La sintaxis de REPLACE() la función es:
REPLACE(str,from_str,to_str)
La función reemplaza todas las instancias de from_str dentro de str cadena con el to_str especificado cuerda. La función distingue entre mayúsculas y minúsculas y es segura para varios bytes.
Por ejemplo:

RETROCESO()
La sintaxis de REVERSE() la función es:
REVERSE(str)
La función genera el str cadena con un orden de caracteres inverso. REVERSE() es una función multibyte segura.
Por ejemplo:

DERECHA()
La sintaxis de RIGHT() la función es:
RIGHT(str,len)
La función genera el len más a la derecha número de caracteres de str cuerda. Si algún argumento es NULL , el resultado es NULL . RIGHT() es una función multibyte segura.
Por ejemplo:

RPAD()
La sintaxis de RPAD() la función es:
RPAD(str,len,padstr)
La función genera el str especificado cadena, rellenada a la derecha con padstr cadena, hasta una longitud de len caracteres. El str el argumento es más largo que len acorta la salida a len personajes.
RPAD() es multibyte seguro.
Por ejemplo:

RTRIM()
La sintaxis de RTRIM() la función es:
RTRIM(str)
La función genera el str cadena sin los caracteres de espacio final. El RTRIM() la función es multibyte segura.
Por ejemplo:

SOUNDEX(), es decir, SUENA COMO
La sintaxis de SOUNDEX() la función es:
SOUNDEX(str)
La función genera una cadena soundex, es decir, una representación fonética de la entrada str cuerda. El SOUNDEX() function allows users to compare English words that are spelled differently but sound alike.
SOUNDEX() ignores all non-alphabetic characters in the input string and treats all characters outside the A-Z range as vowels.
Importante: The SOUNDEX() function works well only with strings in English. Results are unreliable for strings in other languages and for strings that use multibyte character sets, including utf-8.
Por ejemplo:

The (expr1) SOUNDS LIKE (expr2) function is the same as SOUNDEX(expr1) = SOUNDEX(expr2) .
SPACE()
The syntax for the SPACE() function is:
SPACE(N)
The function outputs a string consisting of N number of space characters.
Por ejemplo:

STRCMP()
The syntax for the STRCMP() function is:
STRCMP(expr1,expr2)The function compares the two expressions and outputs:
0- If the two expressions are the same.-1- If the first expression is smaller than the second depending on the current sort order.1- If the second expression is smaller than the first one.
Por ejemplo:

In this example, the output is 1 because the second argument is smaller than the first one.
SUBSTRING(), i.e., SUBSTR(), MID()
The syntax for the SUBSTRING() function is:
SUBSTRING(str, pos, length)o:
SUBSTRING(str FROM pos FOR length)The function extracts a substring from a string, starting at a specified position.
The length argument is optional and used to return a substring length characters long from the str string, starting at pos position.
The pos argument specifies from which position to extract the substring. If pos is a positive number, the function extracts a substring from the beginning of the string. If pos is a negative number, the function extracts a substring from the end of the string.
Por ejemplo:

MID(str,pos,length) and SUBSTR() are synonyms for SUBSTRING(str,pos,length) .
SUBSTRING_INDEX()
The syntax for the SUBSTRING_INDEX() function is:
SUBSTRING_INDEX(str,delim,count)
The function outputs a substring from the str string before a specified count number of delim delimiter occurs.
If the count argument is positive, the function outputs everything left of the final delimiter, counting from the left side.
If the count argument is negative, the function outputs everything right of the final delimiter, counting from the right side.
SUBSTRING_INDEX() searches for the delimiter in a case-sensitive fashion, and it is multibyte safe.
Por ejemplo:
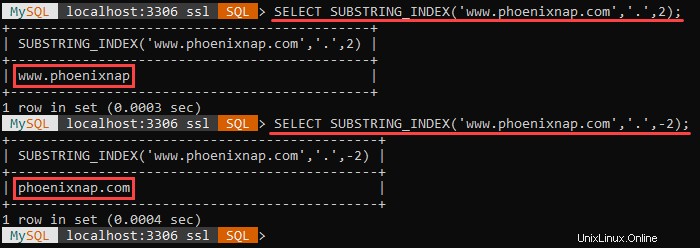
The example above shows the different outputs when the count argument is positive and negative.
TO_BASE64()
The syntax for the TO_BASE64() function is:
TO_BASE64(str)The function encodes a string argument to a base-64 encoded form and returns the result. If the argument isn't a string, the function converts it to a string before base-64 encoding.
If the argument is NULL , the result is NULL .
TO_BASE64() is the reverse of FROM_BASE64() .
Por ejemplo:

The output is a base-64 encoded string.
TRIM()
The syntax for the TRIM() function is:
TRIM([{BOTH | LEADING | TRAILING} [remstr] FROM] str)
The function removes all remstr prefixes and suffixes from the specified str string and outputs the result.
Unless specifying the BOTH, LEADING ,or TRAILING specifiers, the function assumes BOTH .
The remstr argument is optional, and omitting it removes the space characters from the string.
TRIM() is multibyte safe.
Por ejemplo:

In this example, the function removes the specified leading prefix from the string.
UPPER(), i.e., UCASE()
The syntax for the UPPER() function is:
UPPER(str)
The function changes all characters of the specified str string to uppercase and outputs the result. The default character set mapping it uses is utf8mb4. UPPER() is multibyte safe.
Por ejemplo:

The UCASE() function is a synonym for UPPER() .
UNHEX()
The syntax for the UNHEX() function is:
UNHEX(str)The function interprets each pair of characters in a string argument as a hexadecimal number and converts it to the byte represented by the number. The output is a binary result.
If the str argument contains non-hexadecimal digits, the output is NULL . A NULL output can also occur if the argument is a BINARY column.
UNHEX() is the opposite of HEX() . However, you shouldn't use UNHEX() to inverse the HEX() result of numeric arguments. Instead, use the mathematical function CONV(HEX(N),16,10) .
Por ejemplo:

WEIGHT_STRING()
The syntax for the WEIGHT_STRING() function is:
WEIGHT_STRING(str [AS {CHAR|BINARY}(N)] [flags])str- The input string argument.AS- Optional clause, permits casting the input string to a binary or non-binary string, and to a specific length.flags- Optional argument, currently unused.
The function outputs the weight string for the input str cuerda. The output value represents the string's sorting and comparison value.
If used, the AS BINARY(N) argument measures the length in bytes rather than characters, and right-pads with 0x00 bytes to the specified length.
On the other hand, the AS CHAR(N) argument measures the characters' length and right-pads with spaces to the specified length.
N has a minimum value of 1. If N is less than the input string length, the string is truncated without issuing a warning.
If the input string is a non-binary value (CHAR , VARCHAR , or TEXT ) , the output contains the collation weights for the string. If the input string is a binary value (BINARY , VARBINARY , or BLOB ), the output is the same as the input string because the weight for each byte in a binary string is the byte value.
If the input string is NULL , the output is NULL .
Important:WEIGHT_STRING() is a debugging function intended for internal use and collation testing and debugging. Its behavior is subject to change between different MySQL versions.
Por ejemplo:

In this example, we used HEX() to display the output because HEX() can display binary results containing nonprinting values in a printable form.