Apache Hadoop es un marco de código abierto que se utiliza para el almacenamiento distribuido, así como para el procesamiento distribuido de grandes datos en grupos de computadoras que se ejecutan en hardware básico. Hadoop almacena datos en Hadoop Distributed File System (HDFS) y el procesamiento de estos datos se realiza mediante MapReduce. YARN proporciona una API para solicitar y asignar recursos en el clúster de Hadoop.
Este artículo explica cómo instalar la versión 2 de Hadoop en RHEL 8 o CentOS 8. Instalaremos HDFS (Namenode y Datanode), YARN, MapReduce en el clúster de un solo nodo en modo pseudodistribuido, que es una simulación distribuida en una sola máquina. Cada demonio de Hadoop, como hdfs, yarn, mapreduce, etc., se ejecutará como un proceso java independiente/individual.
Arquitectura HDFS.
Requisitos de software y convenciones de la línea de comandos de Linux | Categoría | Requisitos, convenciones o versión de software utilizada |
|---|
| Sistema | RHEL 8 / CentOS 8 |
| Software | Hadoop 2.8.5, Oracle JDK 1.8 |
| Otro | Acceso privilegiado a su sistema Linux como root o a través de sudo comando. |
| Convenciones | # – requiere que los comandos de Linux dados se ejecuten con privilegios de root, ya sea directamente como usuario root o mediante el uso de sudo comando
$ – requiere que los comandos de Linux dados se ejecuten como un usuario normal sin privilegios |
Añadir usuarios para el entorno Hadoop
Cree el nuevo usuario y grupo usando el comando:
# useradd hadoop
# passwd hadoop
[root@hadoop ~]# useradd hadoop
[root@hadoop ~]# passwd hadoop
Changing password for user hadoop.
New password:
Retype new password:
passwd: all authentication tokens updated successfully.
[root@hadoop ~]# cat /etc/passwd | grep hadoop
hadoop:x:1000:1000::/home/hadoop:/bin/bash
Instalar y configurar Oracle JDK
Descargue e instale el paquete oficial jdk-8u202-linux-x64.rpm para instalar Oracle JDK.
[root@hadoop ~]# rpm -ivh jdk-8u202-linux-x64.rpm
warning: jdk-8u202-linux-x64.rpm: Header V3 RSA/SHA256 Signature, key ID ec551f03: NOKEY
Verifying... ################################# [100%]
Preparing... ################################# [100%]
Updating / installing...
1:jdk1.8-2000:1.8.0_202-fcs ################################# [100%]
Unpacking JAR files...
tools.jar...
plugin.jar...
javaws.jar...
deploy.jar...
rt.jar...
jsse.jar...
charsets.jar...
localedata.jar...
Después de la instalación para verificar que Java se haya configurado correctamente, ejecute los siguientes comandos:
[root@hadoop ~]# java -version
java version "1.8.0_202"
Java(TM) SE Runtime Environment (build 1.8.0_202-b08)
Java HotSpot(TM) 64-Bit Server VM (build 25.202-b08, mixed mode)
[root@hadoop ~]# update-alternatives --config java
There is 1 program that provides 'java'.
Selection Command
-----------------------------------------------
*+ 1 /usr/java/jdk1.8.0_202-amd64/jre/bin/java
Configurar SSH sin contraseña
Instale Open SSH Server y Open SSH Client o, si ya está instalado, mostrará una lista de los siguientes paquetes.
[root@hadoop ~]# rpm -qa | grep openssh*
openssh-server-7.8p1-3.el8.x86_64
openssl-libs-1.1.1-6.el8.x86_64
openssl-1.1.1-6.el8.x86_64
openssh-clients-7.8p1-3.el8.x86_64
openssh-7.8p1-3.el8.x86_64
openssl-pkcs11-0.4.8-2.el8.x86_64
Genere pares de claves públicas y privadas con el siguiente comando. El terminal le pedirá que ingrese el nombre del archivo. Presiona ENTER y proceder. Después de eso, copie el formulario de claves públicas id_rsa.pub a authorized_keys .
$ ssh-keygen -t rsa
$ cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
$ chmod 640 ~/.ssh/authorized_keys
[hadoop@hadoop ~]$ ssh-keygen -t rsa
Generating public/private rsa key pair.
Enter file in which to save the key (/home/hadoop/.ssh/id_rsa):
Created directory '/home/hadoop/.ssh'.
Enter passphrase (empty for no passphrase):
Enter same passphrase again:
Your identification has been saved in /home/hadoop/.ssh/id_rsa.
Your public key has been saved in /home/hadoop/.ssh/id_rsa.pub.
The key fingerprint is:
SHA256:H+LLPkaJJDD7B0f0Je/NFJRP5/FUeJswMmZpJFXoelg hadoop@hadoop.sandbox.com
The key's randomart image is:
+---[RSA 2048]----+
| .. ..++*o .o|
| o .. +.O.+o.+|
| + . . * +oo==|
| . o o . E .oo|
| . = .S.* o |
| . o.o= o |
| . .. o |
| .o. |
| o+. |
+----[SHA256]-----+
[hadoop@hadoop ~]$ cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
[hadoop@hadoop ~]$ chmod 640 ~/.ssh/authorized_keys
Verifique la configuración de ssh sin contraseña con el comando:
$ ssh
[hadoop@hadoop ~]$ ssh hadoop.sandbox.com
Web console: https://hadoop.sandbox.com:9090/ or https://192.168.1.108:9090/
Last login: Sat Apr 13 12:09:55 2019
[hadoop@hadoop ~]$
Instalar Hadoop y configurar archivos xml relacionados
Descargue y extraiga Hadoop 2.8.5 del sitio web oficial de Apache.
# wget https://archive.apache.org/dist/hadoop/common/hadoop-2.8.5/hadoop-2.8.5.tar.gz
# tar -xzvf hadoop-2.8.5.tar.gz
[root@rhel8-sandbox ~]# wget https://archive.apache.org/dist/hadoop/common/hadoop-2.8.5/hadoop-2.8.5.tar.gz
--2019-04-13 11:14:03-- https://archive.apache.org/dist/hadoop/common/hadoop-2.8.5/hadoop-2.8.5.tar.gz
Resolving archive.apache.org (archive.apache.org)... 163.172.17.199
Connecting to archive.apache.org (archive.apache.org)|163.172.17.199|:443... connected.
HTTP request sent, awaiting response... 200 OK
Length: 246543928 (235M) [application/x-gzip]
Saving to: ‘hadoop-2.8.5.tar.gz’
hadoop-2.8.5.tar.gz 100%[=====================================================================================>] 235.12M 1.47MB/s in 2m 53s
2019-04-13 11:16:57 (1.36 MB/s) - ‘hadoop-2.8.5.tar.gz’ saved [246543928/246543928]
Configuración de las variables de entorno
Edite el bashrc para el usuario de Hadoop mediante la configuración de las siguientes variables de entorno de Hadoop:
export HADOOP_HOME=/home/hadoop/hadoop-2.8.5
export HADOOP_INSTALL=$HADOOP_HOME
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib/native"
Fuente el .bashrc en la sesión de inicio de sesión actual.
$ source ~/.bashrc
Edite el hadoop-env.sh archivo que está en /etc/hadoop dentro del directorio de instalación de Hadoop y realice los siguientes cambios y verifique si desea cambiar alguna otra configuración.
export JAVA_HOME=${JAVA_HOME:-"/usr/java/jdk1.8.0_202-amd64"}
export HADOOP_CONF_DIR=${HADOOP_CONF_DIR:-"/home/hadoop/hadoop-2.8.5/etc/hadoop"}
Cambios de configuración en el archivo core-site.xml
Edite el core-site.xml con vim o puede usar cualquiera de los editores. El archivo está en /etc/hadoop dentro de hadoop directorio de inicio y agregue las siguientes entradas.
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop.sandbox.com:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/hadooptmpdata</value>
</property>
</configuration>
Además, cree el directorio bajo hadoop carpeta de inicio.
$ mkdir hadooptmpdata
Cambios de configuración en el archivo hdfs-site.xml
Edite el hdfs-site.xml que está presente en la misma ubicación, es decir, /etc/hadoop dentro de hadoop directorio de instalación y cree el Namenode/Datanode directorios bajo hadoop directorio de inicio del usuario.
$ mkdir -p hdfs/namenode
$ mkdir -p hdfs/datanode
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.name.dir</name>
<value>file:///home/hadoop/hdfs/namenode</value>
</property>
<property>
<name>dfs.data.dir</name>
<value>file:///home/hadoop/hdfs/datanode</value>
</property>
</configuration>
Cambios de configuración en el archivo mapred-site.xml
Copie el mapred-site.xml de mapred-site.xml.template usando cp y luego edite el mapred-site.xml colocado en /etc/hadoop en hadoop directorio de instilación con los siguientes cambios.
$ cp mapred-site.xml.template mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
Cambios de configuración en el archivo yarn-site.xml
Editar yarn-site.xml con las siguientes entradas.
<configuration>
<property>
<name>mapreduceyarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
Inicio del clúster de Hadoop
Formatee el namenode antes de usarlo por primera vez. Como usuario de hadoop, ejecute el siguiente comando para formatear el Namenode.
$ hdfs namenode -format
[hadoop@hadoop ~]$ hdfs namenode -format
19/04/13 11:54:10 INFO namenode.NameNode: STARTUP_MSG:
/************************************************************
STARTUP_MSG: Starting NameNode
STARTUP_MSG: user = hadoop
STARTUP_MSG: host = hadoop.sandbox.com/192.168.1.108
STARTUP_MSG: args = [-format]
STARTUP_MSG: version = 2.8.5
19/04/13 11:54:17 INFO namenode.FSNamesystem: dfs.namenode.safemode.threshold-pct = 0.9990000128746033
19/04/13 11:54:17 INFO namenode.FSNamesystem: dfs.namenode.safemode.min.datanodes = 0
19/04/13 11:54:17 INFO namenode.FSNamesystem: dfs.namenode.safemode.extension = 30000
19/04/13 11:54:18 INFO metrics.TopMetrics: NNTop conf: dfs.namenode.top.window.num.buckets = 10
19/04/13 11:54:18 INFO metrics.TopMetrics: NNTop conf: dfs.namenode.top.num.users = 10
19/04/13 11:54:18 INFO metrics.TopMetrics: NNTop conf: dfs.namenode.top.windows.minutes = 1,5,25
19/04/13 11:54:18 INFO namenode.FSNamesystem: Retry cache on namenode is enabled
19/04/13 11:54:18 INFO namenode.FSNamesystem: Retry cache will use 0.03 of total heap and retry cache entry expiry time is 600000 millis
19/04/13 11:54:18 INFO util.GSet: Computing capacity for map NameNodeRetryCache
19/04/13 11:54:18 INFO util.GSet: VM type = 64-bit
19/04/13 11:54:18 INFO util.GSet: 0.029999999329447746% max memory 966.7 MB = 297.0 KB
19/04/13 11:54:18 INFO util.GSet: capacity = 2^15 = 32768 entries
19/04/13 11:54:18 INFO namenode.FSImage: Allocated new BlockPoolId: BP-415167234-192.168.1.108-1555142058167
19/04/13 11:54:18 INFO common.Storage: Storage directory /home/hadoop/hdfs/namenode has been successfully formatted.
19/04/13 11:54:18 INFO namenode.FSImageFormatProtobuf: Saving image file /home/hadoop/hdfs/namenode/current/fsimage.ckpt_0000000000000000000 using no compression
19/04/13 11:54:18 INFO namenode.FSImageFormatProtobuf: Image file /home/hadoop/hdfs/namenode/current/fsimage.ckpt_0000000000000000000 of size 323 bytes saved in 0 seconds.
19/04/13 11:54:18 INFO namenode.NNStorageRetentionManager: Going to retain 1 images with txid >= 0
19/04/13 11:54:18 INFO util.ExitUtil: Exiting with status 0
19/04/13 11:54:18 INFO namenode.NameNode: SHUTDOWN_MSG:
/************************************************************
SHUTDOWN_MSG: Shutting down NameNode at hadoop.sandbox.com/192.168.1.108
************************************************************/
Una vez que se haya formateado Namenode, inicie HDFS usando start-dfs.sh guión.
$ start-dfs.sh
[hadoop@hadoop ~]$ start-dfs.sh
Starting namenodes on [hadoop.sandbox.com]
hadoop.sandbox.com: starting namenode, logging to /home/hadoop/hadoop-2.8.5/logs/hadoop-hadoop-namenode-hadoop.sandbox.com.out
hadoop.sandbox.com: starting datanode, logging to /home/hadoop/hadoop-2.8.5/logs/hadoop-hadoop-datanode-hadoop.sandbox.com.out
Starting secondary namenodes [0.0.0.0]
The authenticity of host '0.0.0.0 (0.0.0.0)' can't be established.
ECDSA key fingerprint is SHA256:e+NfCeK/kvnignWDHgFvIkHjBWwghIIjJkfjygR7NkI.
Are you sure you want to continue connecting (yes/no)? yes
0.0.0.0: Warning: Permanently added '0.0.0.0' (ECDSA) to the list of known hosts.
hadoop@0.0.0.0's password:
0.0.0.0: starting secondarynamenode, logging to /home/hadoop/hadoop-2.8.5/logs/hadoop-hadoop-secondarynamenode-hadoop.sandbox.com.out
Para iniciar los servicios de YARN, debe ejecutar el script de inicio de hilo, es decir, start-yarn.sh
$ start-yarn.sh
[hadoop@hadoop ~]$ start-yarn.sh
starting yarn daemons
starting resourcemanager, logging to /home/hadoop/hadoop-2.8.5/logs/yarn-hadoop-resourcemanager-hadoop.sandbox.com.out
hadoop.sandbox.com: starting nodemanager, logging to /home/hadoop/hadoop-2.8.5/logs/yarn-hadoop-nodemanager-hadoop.sandbox.com.out
Para verificar que todos los servicios/daemons de Hadoop se hayan iniciado correctamente, puede utilizar jps comando.
$ jps
2033 NameNode
2340 SecondaryNameNode
2566 ResourceManager
2983 Jps
2139 DataNode
2671 NodeManager
Ahora podemos verificar la versión actual de Hadoop que puede usar a continuación:
$ hadoop version
o
$ hdfs version
[hadoop@hadoop ~]$ hadoop version
Hadoop 2.8.5
Subversion https://git-wip-us.apache.org/repos/asf/hadoop.git -r 0b8464d75227fcee2c6e7f2410377b3d53d3d5f8
Compiled by jdu on 2018-09-10T03:32Z
Compiled with protoc 2.5.0
From source with checksum 9942ca5c745417c14e318835f420733
This command was run using /home/hadoop/hadoop-2.8.5/share/hadoop/common/hadoop-common-2.8.5.jar
[hadoop@hadoop ~]$ hdfs version
Hadoop 2.8.5
Subversion https://git-wip-us.apache.org/repos/asf/hadoop.git -r 0b8464d75227fcee2c6e7f2410377b3d53d3d5f8
Compiled by jdu on 2018-09-10T03:32Z
Compiled with protoc 2.5.0
From source with checksum 9942ca5c745417c14e318835f420733
This command was run using /home/hadoop/hadoop-2.8.5/share/hadoop/common/hadoop-common-2.8.5.jar
[hadoop@hadoop ~]$
Interfaz de línea de comandos HDFS
Para acceder a HDFS y crear algunos directorios en la parte superior de DFS, puede usar HDFS CLI.
$ hdfs dfs -mkdir /testdata
$ hdfs dfs -mkdir /hadoopdata
$ hdfs dfs -ls /
[hadoop@hadoop ~]$ hdfs dfs -ls /
Found 2 items
drwxr-xr-x - hadoop supergroup 0 2019-04-13 11:58 /hadoopdata
drwxr-xr-x - hadoop supergroup 0 2019-04-13 11:59 /testdata
Acceda a Namenode y YARN desde el navegador
Puede acceder tanto a la interfaz de usuario web para NameNode como a YARN Resource Manager a través de cualquiera de los navegadores como Google Chrome/Mozilla Firefox.
Interfaz de usuario web de Namenode:http://<hadoop cluster hostname/IP address>:50070
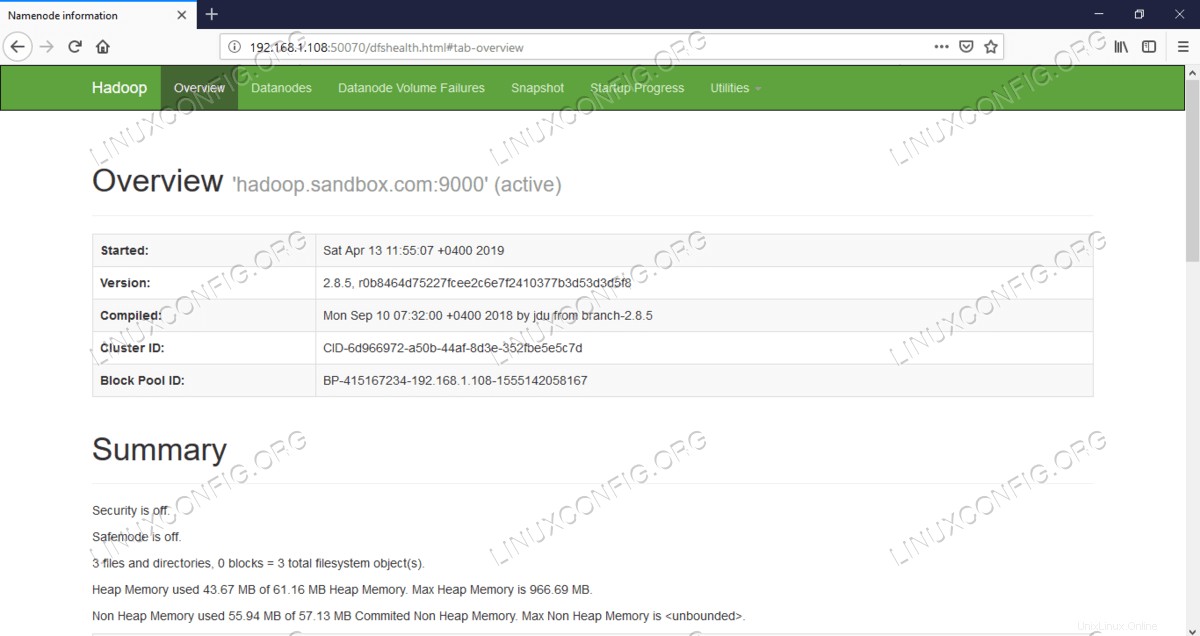 Interfaz de usuario web de Namenode.
Interfaz de usuario web de Namenode. 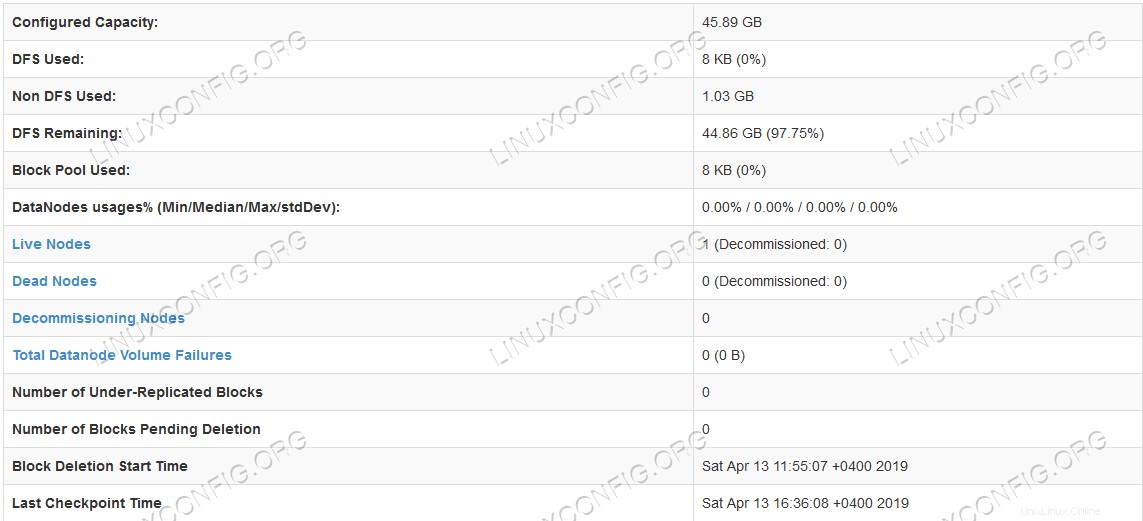 Información detallada de HDFS.
Información detallada de HDFS. 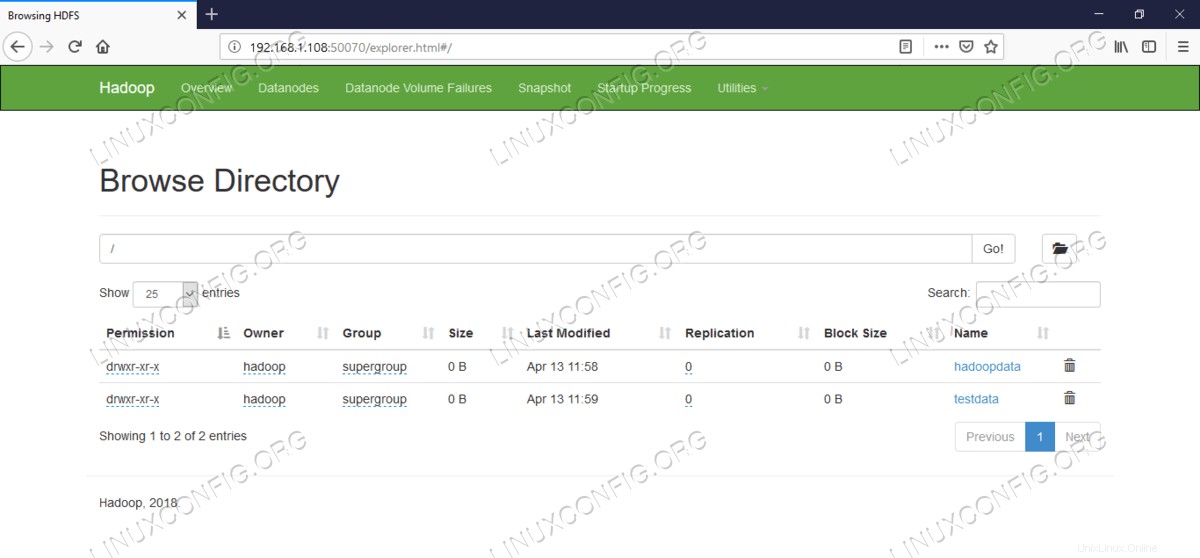 Exploración de directorios HDFS.
Exploración de directorios HDFS.
La interfaz web de YARN Resource Manager (RM) mostrará todos los trabajos en ejecución en Hadoop Cluster actual.
Interfaz de usuario web de Resource Manager:http://<hadoop cluster hostname/IP address>:8088
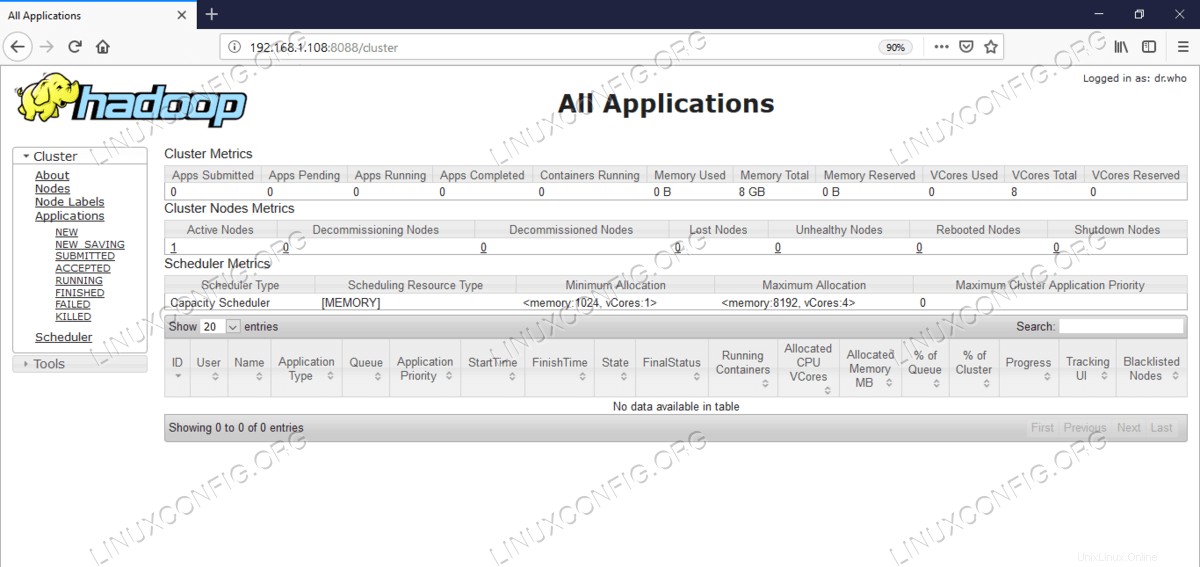 Interfaz de usuario web del administrador de recursos (YARN).
Interfaz de usuario web del administrador de recursos (YARN). Conclusión
El mundo está cambiando la forma en que opera actualmente y Big-data está jugando un papel importante en esta fase. Hadoop es un marco que nos facilita la vida mientras trabajamos en grandes conjuntos de datos. Hay mejoras en todos los frentes. El futuro es emocionante.
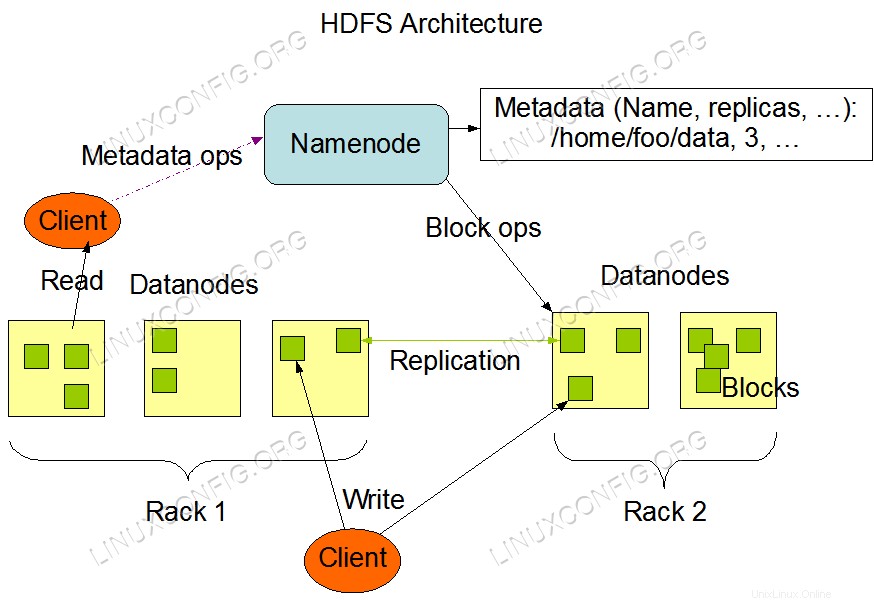 Arquitectura HDFS.
Arquitectura HDFS.