En esta serie de artículos, cubriremos todo el edificio del clúster Hadoop de Cloudera. construyendo con Vendedor e Industriales mejores prácticas recomendadas.
Parte 1 :Mejores prácticas para implementar el servidor Hadoop en CentOS/RHEL 7Parte 2 :Configuración de los requisitos previos de Hadoop y refuerzo de la seguridadParte 3 :Cómo instalar y configurar Cloudera Manager en CentOS/RHEL 7Parte 4 :Cómo instalar CDH y configurar ubicaciones de servicios en CentOS/RHEL 7Parte 5 :Cómo configurar la alta disponibilidad para NamenodeParte 6 :Cómo configurar la alta disponibilidad para Resource ManagerParte 7 :Cómo instalar y configurar Hive con alta disponibilidadParte 8 :Cómo instalar y configurar Sentry (herramienta de autorización)Parte 9 :Cómo instalar Kerberos (Kerberización del clúster) para la autenticación de HadoopParte 10 :Cómo ajustar el clúster (ajuste de hilo) en CentOS/RHEL 7SO instalando y haciendo OS Los requisitos previos de nivel son los primeros pasos para crear un clúster de Hadoop . Hadoop puede ejecutarse en varios sabores de la plataforma Linux:CentOS , RedHat , Ubuntu , Debian , SUSE etc., en producción en tiempo real, la mayoría de los clústeres de Hadoop se basan en RHEL/CentOS , usaremos CentOS 7 para demostración en esta serie de tutoriales.
En una organización, la instalación del sistema operativo se puede realizar mediante kickstart . Si se trata de un clúster de 3 a 4 nodos, la instalación manual es posible, pero si construimos un clúster grande con más de 10 nodos, es tedioso instalar el sistema operativo uno por uno. En este escenario, el método Kickstart entra en escena, podemos continuar con la instalación masiva usando kickstart.
Lograr un buen rendimiento de un entorno Hadoop depende del aprovisionamiento del hardware y software correctos. Entonces, construir un clúster de Hadoop de producción implica mucha consideración con respecto al hardware y al software.
En este artículo, revisaremos varios puntos de referencia sobre la instalación del sistema operativo y algunas mejores prácticas para implementar Cloudera Hadoop Cluster Server en CentOS/RHEL 7 .
Consideraciones importantes y mejores prácticas para implementar el servidor Hadoop
Las siguientes son las mejores prácticas para configurar la implementación de Cloudera Hadoop Cluster Server en CentOS/RHEL 7 .
- Los servidores Hadoop no requieren servidores estándar empresariales para construir un clúster, requiere hardware básico.
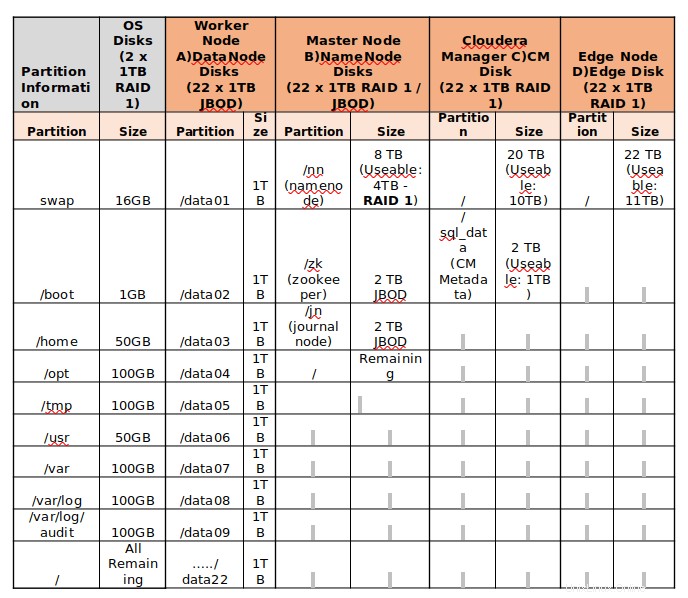
- En el clúster de producción, se recomienda tener de 8 a 12 discos de datos. De acuerdo con la naturaleza de la carga de trabajo, tenemos que decidir sobre esto. Si el clúster es para aplicaciones de cómputo intensivo, tener de 4 a 6 unidades es la mejor práctica para evitar problemas de E/S.
- Las unidades de datos deben particionarse individualmente, por ejemplo, a partir de /data01 a /data10 .
- La configuración de RAID no se recomienda para los nodos de trabajo, porque Hadoop proporciona tolerancia a fallas en los datos al replicar los bloques en 3 de manera predeterminada. Así que JBOD es mejor para los nodos trabajadores.
- Para servidores maestros, RAID 1 es la mejor práctica.
- El sistema de archivos predeterminado en CentOS/RHEL 7.x es XFS . Hadoop es compatible con XFS, ext3 y ext4. El sistema de archivos recomendado es ext3, ya que se ha probado su buen rendimiento.
- Todos los servidores deben tener la misma versión del sistema operativo, al menos la misma versión secundaria.
- La mejor práctica es tener un hardware homogéneo (todos los nodos trabajadores deben tener las mismas características de hardware (RAM, espacio en disco y núcleo, etc.).
- Según la carga de trabajo del clúster (carga de trabajo equilibrada, uso intensivo de cómputo, uso intensivo de E/S) y el tamaño, la planificación de recursos (RAM, CPU) por servidor será diferente.
Encuentre el siguiente ejemplo de partición de disco de los servidores de almacenamiento de 24 TB.
Instalación de CentOS 7 para la implementación del servidor Hadoop
Cosas que debe saber antes de instalar CentOS 7 servidor para Servidor Hadoop .
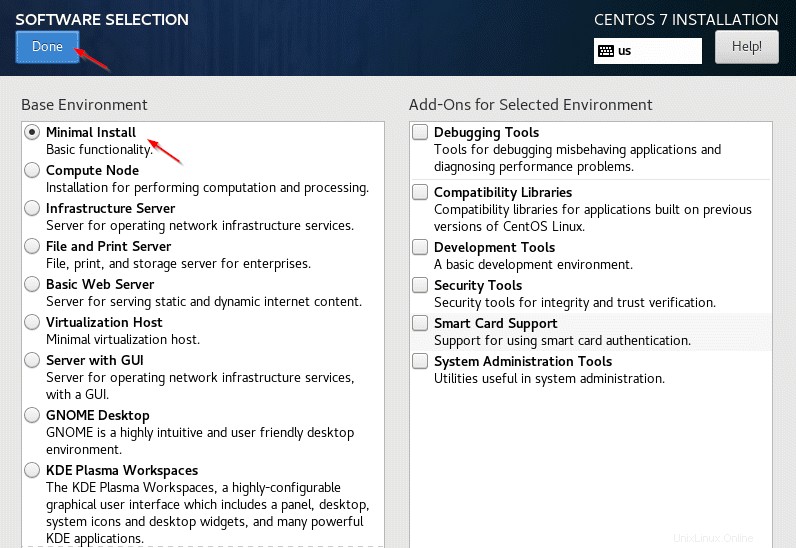
- Una instalación mínima es suficiente para Servidores Hadoop (nodos trabajadores ), en algunos casos, la GUI se puede instalar solo para servidores maestros o servidores de administración donde podemos usar navegadores para las IU web de las herramientas de administración.
- La configuración de redes, nombre de host y otras configuraciones relacionadas con el sistema operativo se pueden realizar después de la instalación del sistema operativo.
- En tiempo real, los proveedores de servidores tendrán su propia consola para interactuar y administrar los servidores, por ejemplo:los servidores Dell tienen iDRAC, que es un dispositivo integrado con los servidores. Usando esa interfaz iDRAC, podemos instalar el sistema operativo con una imagen del sistema operativo en nuestro sistema local.
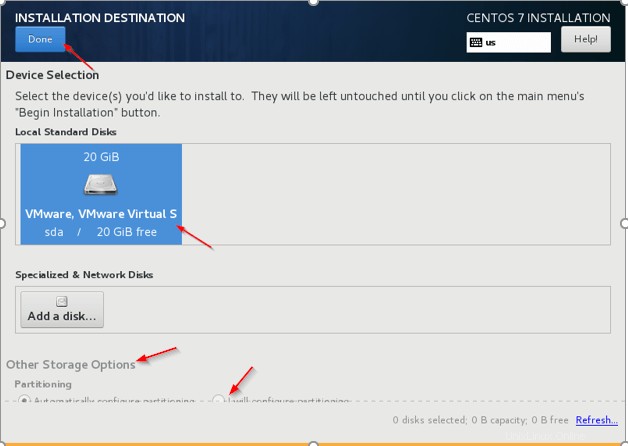
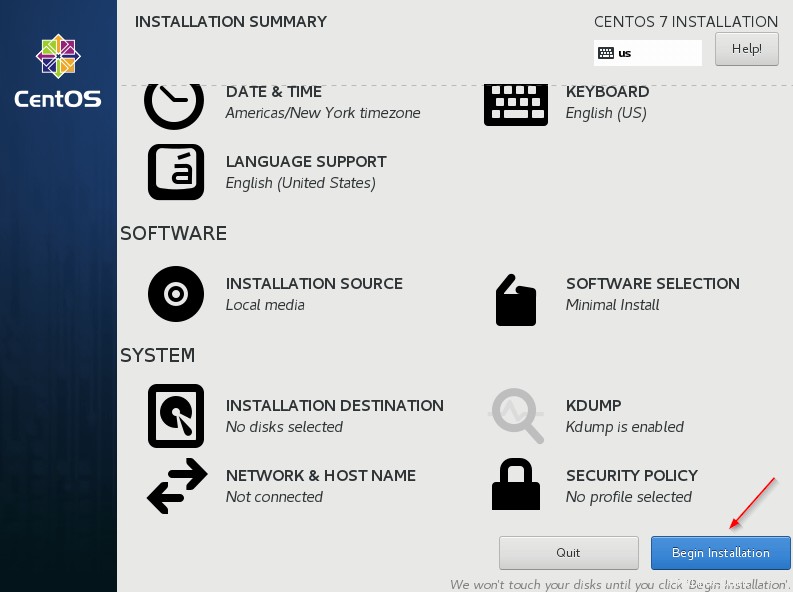
En este artículo, hemos instalado el sistema operativo (CentOS 7 ) en la máquina virtual de VMware. Aquí, no tendremos múltiples discos para realizar particiones. CentOS es similar a RHEL (misma funcionalidad), así que veremos los pasos para instalar CentOS .


# hostnamectl status # hostnamectl set-hostname tecmint # hostnamectl status
Resumen
En este artículo, hemos repasado los pasos de instalación del sistema operativo y las mejores prácticas para la partición del sistema de archivos. Todas estas son pautas generales, según la naturaleza de la carga de trabajo, es posible que debamos concentrarnos en más matices para lograr el mejor rendimiento del clúster. La planificación de clústeres es arte para Hadoop administrador. Profundizaremos en los requisitos previos del nivel del sistema operativo y el fortalecimiento de la seguridad en el próximo artículo.