Colmena es un almacén de datos modelo en Hadoop Ecosistema. Puede funcionar como una herramienta ETL además de Hadoop . Habilitar alta disponibilidad (HA) en Hive no es similar a lo que hacemos en Master Services como Namenode y Resource Manager.
La conmutación por error automática no ocurrirá en Hive (Hiveservidor2 ). Si hay Hiveserver2 (HS2 ) falla, ejecutando trabajos en ese HS2 fallido conseguirá fallar. Necesitamos volver a enviar el trabajo para que pueda ejecutarse en otro HiveServer2 . Entonces, habilitar HA en HS2 no es más que aumentar el número de HS2 componentes en Cluster .
En este artículo veremos los pasos para instalar y habilitar la Alta Disponibilidad de Colmena .
Requisitos
- Prácticas recomendadas para implementar el servidor Hadoop en CentOS/RHEL 7:parte 1
- Configuración de los requisitos previos de Hadoop y fortalecimiento de la seguridad:Parte 2
- Cómo instalar y configurar Cloudera Manager en CentOS/RHEL 7:parte 3
- Cómo instalar CDH y configurar ubicaciones de servicios en CentOS/RHEL 7:Parte 4
- Cómo configurar alta disponibilidad para Namenode - Parte 5
- Cómo configurar la alta disponibilidad para Resource Manager:parte 6
Empecemos...
Instalación y configuración de Hive
http://13.233.129.39:7180/cmf/home
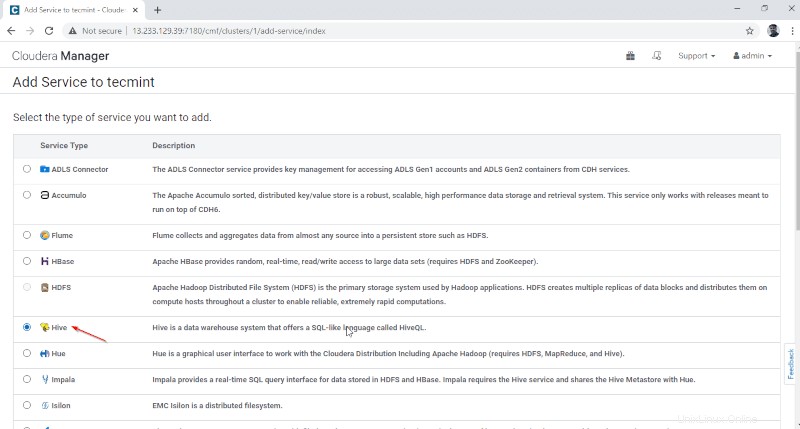
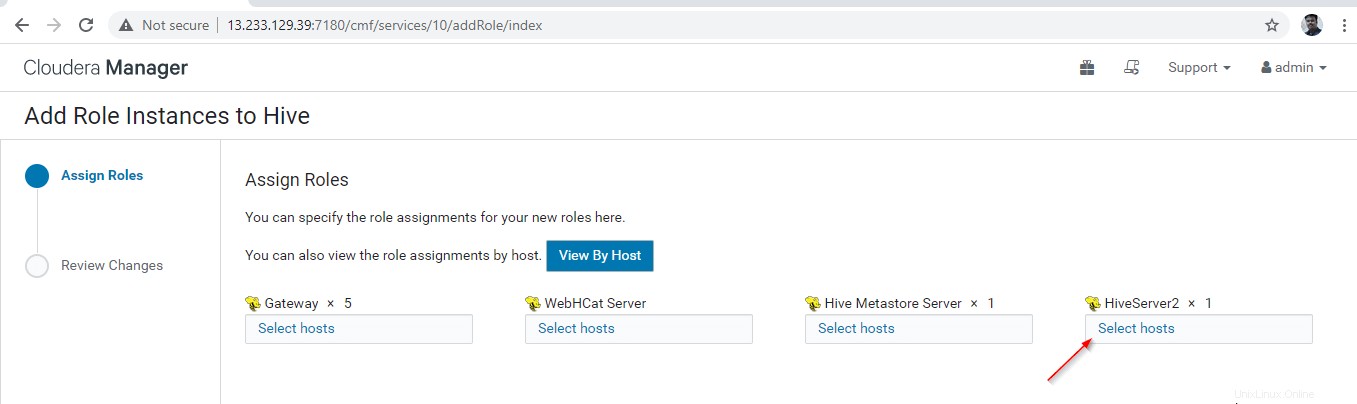
- Puerta de enlace – Es el servicio de atención al cliente donde el usuario puede acceder al Hive. Por lo general, este servicio se colocará en Edge nodos dedicados a los usuarios.
- Metastore de Hive – Es un depósito central para almacenar metadatos de Hive.
- Servidor WebHCat – Es una API web para HCatalog y otros servicios de Hadoop.
- Hiveservidor2 – Es una interfaz de clientes para la ejecución de consultas en Hive.
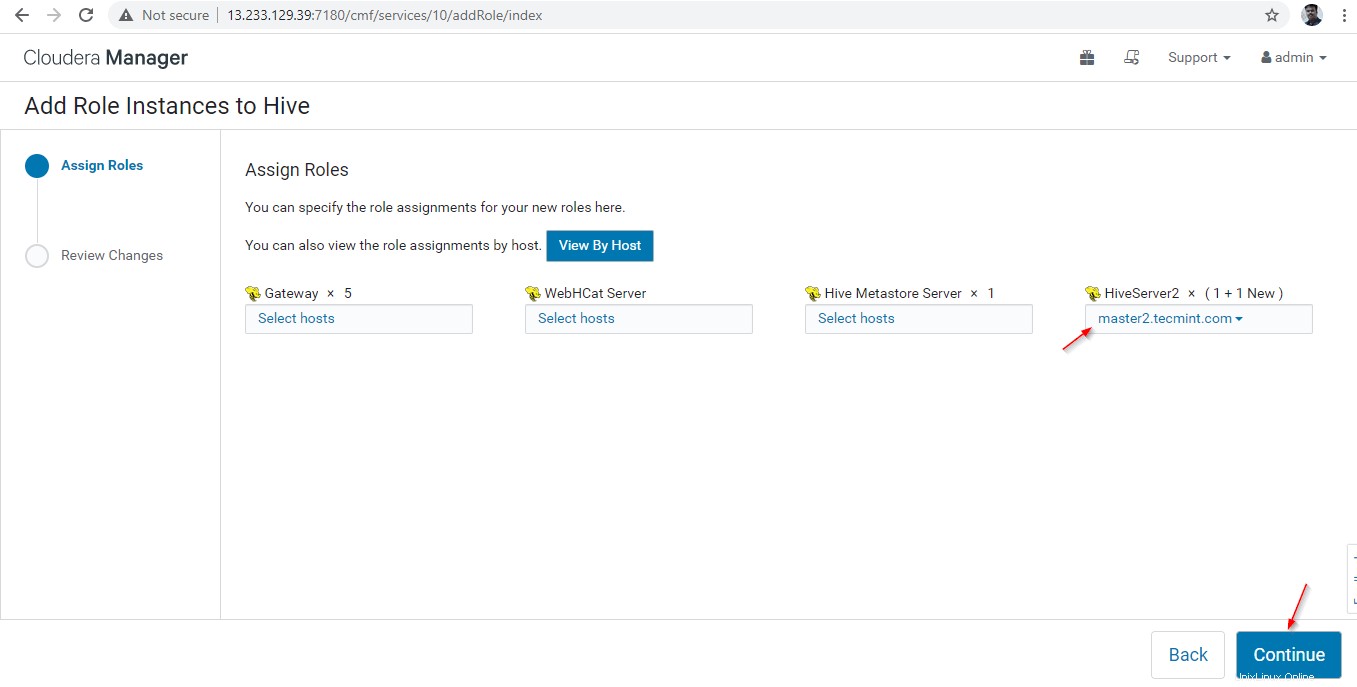
Una vez seleccionados los servidores, haga clic en 'Continuar ‘ para proceder.
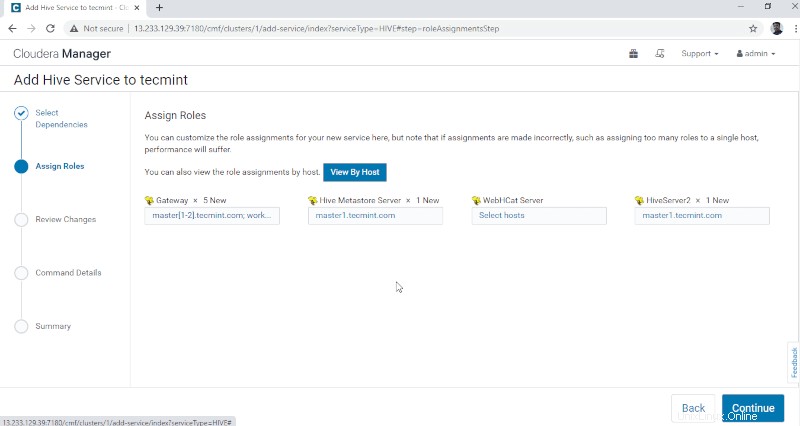
Los detalles de la base de datos mencionados a continuación se ingresarán automáticamente, 'Probar conexión ' se omitirá ya que la base de datos mencionada se creará sobre la marcha. En tiempo real, necesitamos crear la base de datos en la base de datos externa y probar la conexión para continuar. Una vez hecho esto, haga clic en 'Continuar '.
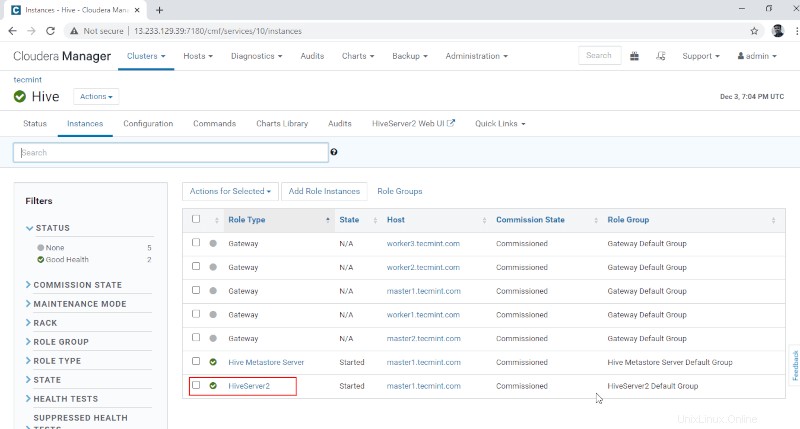
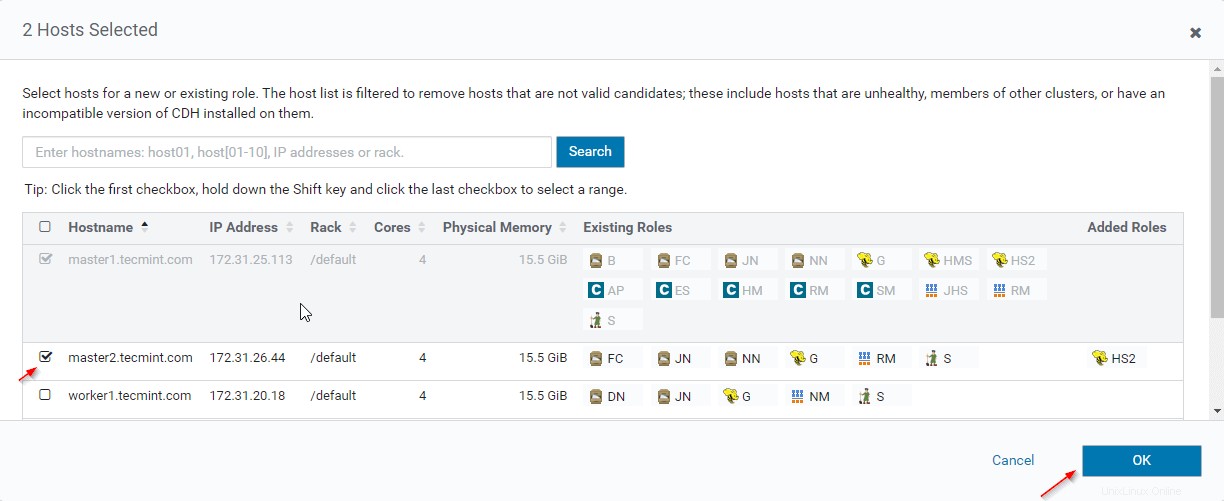
Administrador de Cloudera –> Colmena –> Instancias –> Hiveservidor2 .
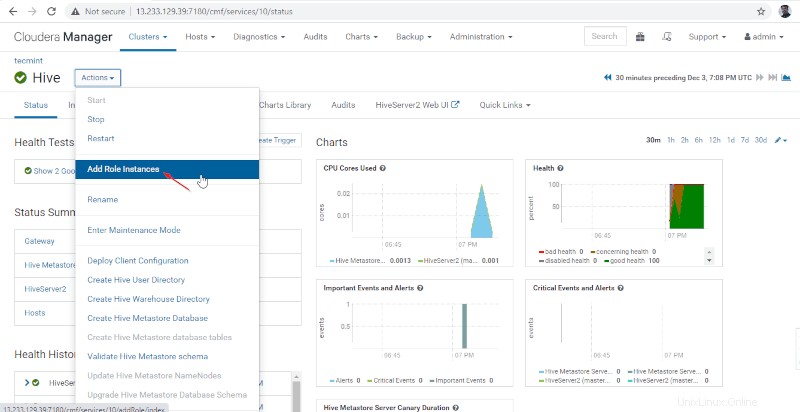
Habilitación de alta disponibilidad en Hive
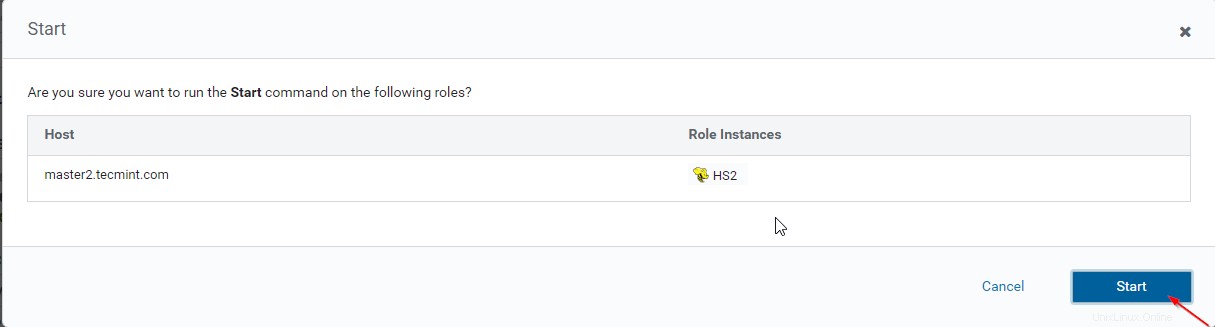
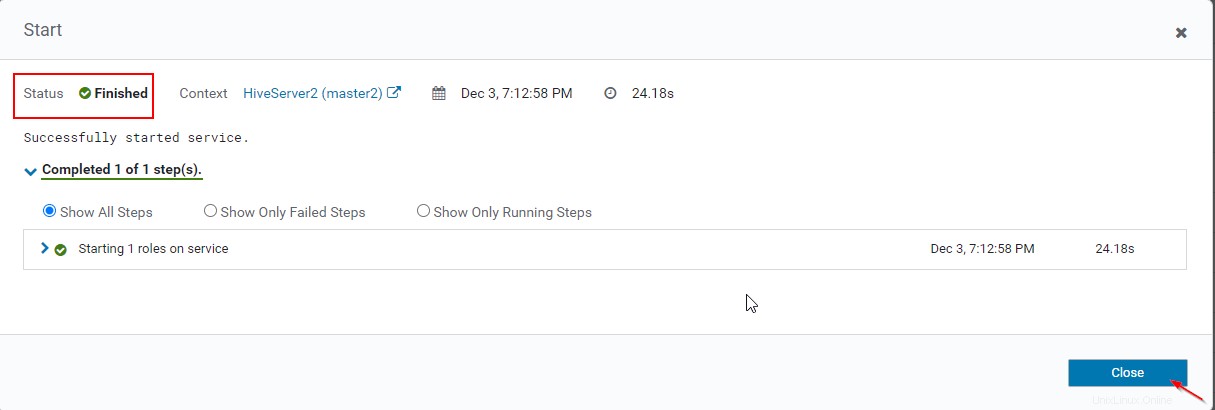
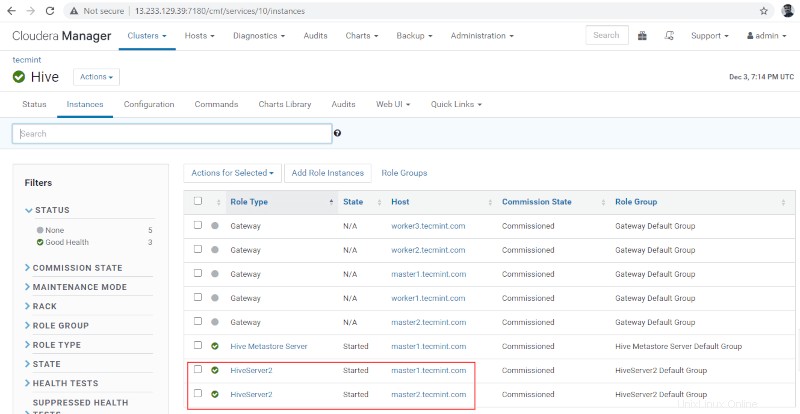
Verificación de la disponibilidad de Hive
Podemos conectar el Hiveserver2 a través de beeline, que es un cliente ligero y una línea de comandos. Utiliza el controlador JDBC para establecer la conexión.
[[email protected] ~]$ beeline

beeline> !connect "jdbc:hive2://master1.tecmint.com:10000"
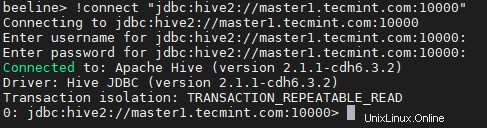
0: jdbc:hive2://master1.tecmint.com:10000> show databases;
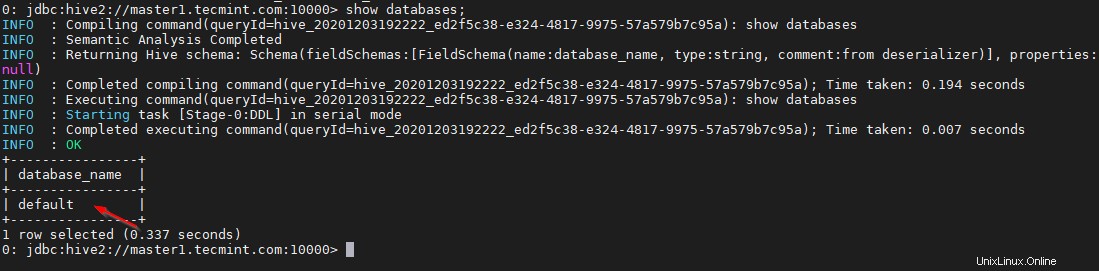
Esta es la base de datos predeterminada que viene incorporada.
0: jdbc:hive2://master1.tecmint.com:10000> !quit

beeline> !connect "jdbc:hive2://master2.tecmint.com:10000"
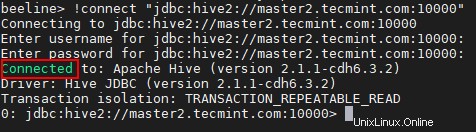
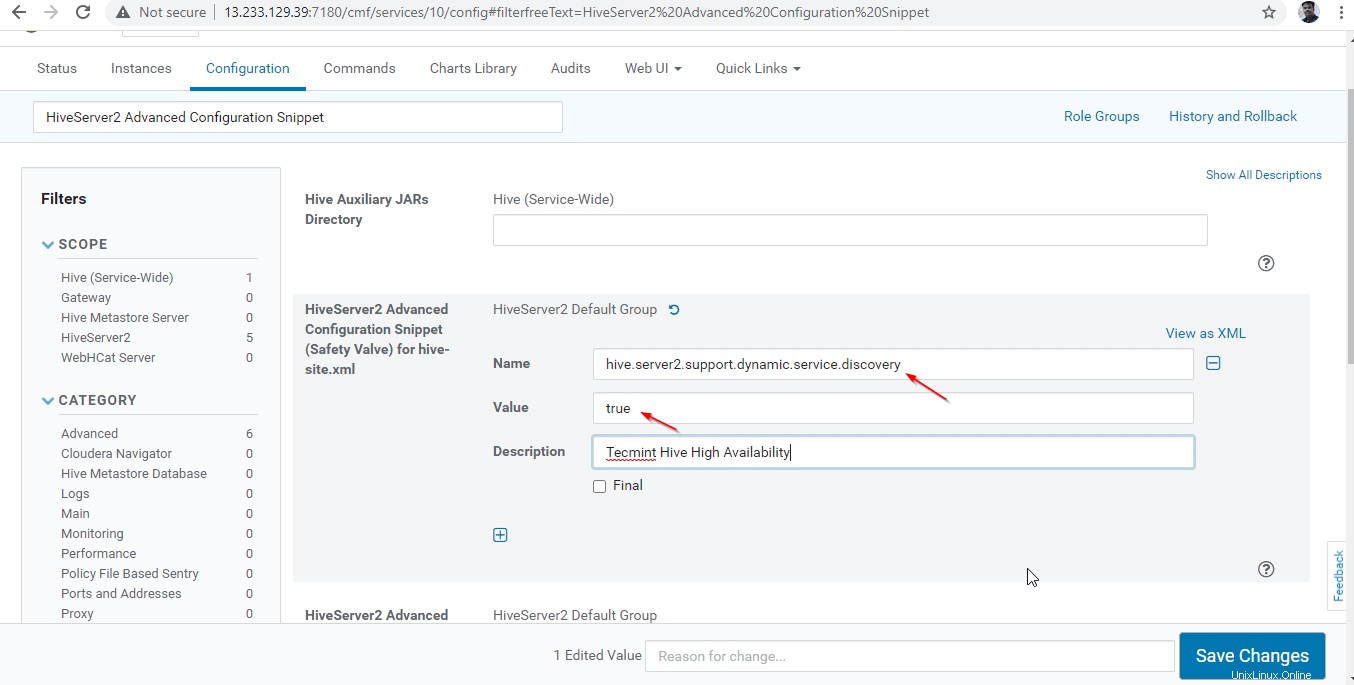
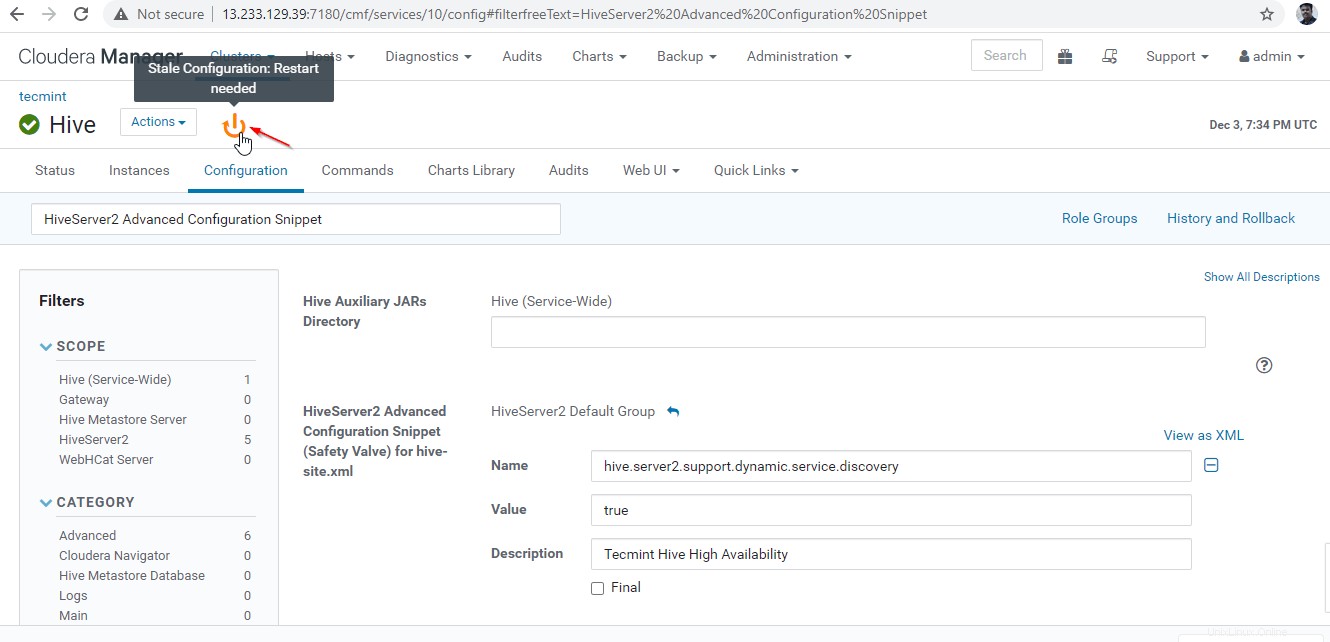
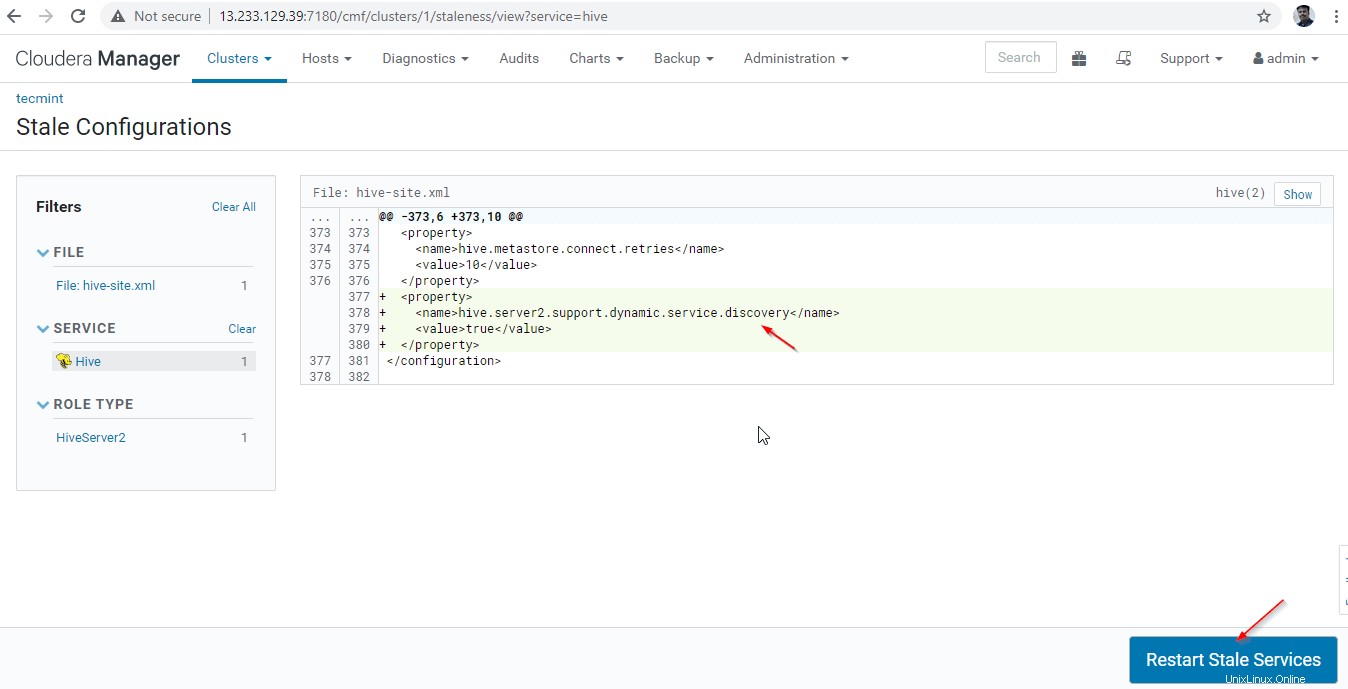
Aquí podemos usar un equilibrador de carga de terceros para equilibrar la carga entre los Hiverserver2 disponibles . La siguiente configuración es necesaria para habilitar el Modo de detección de Zookeeper yendo a Administrador de Cloudera –> Colmena –> Configuración .
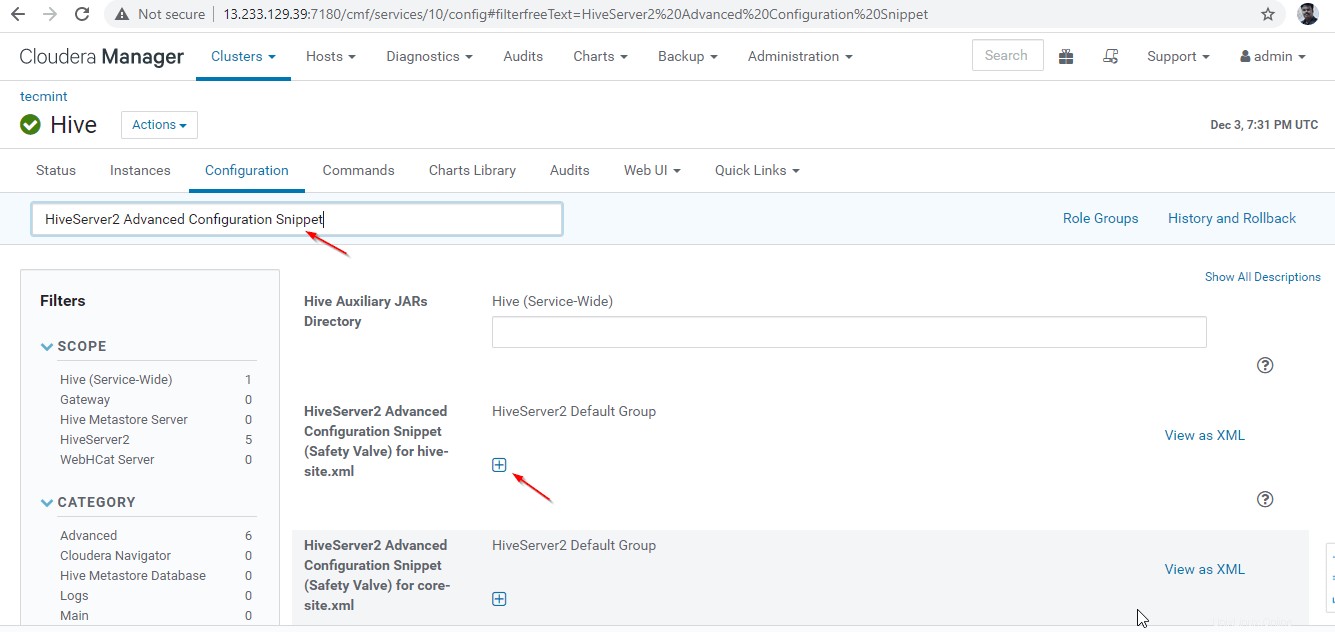
+ símbolo para agregar la siguiente propiedad.
Name : hive.server2.support.dynamic.service.discovery Value : true Description : <any description>
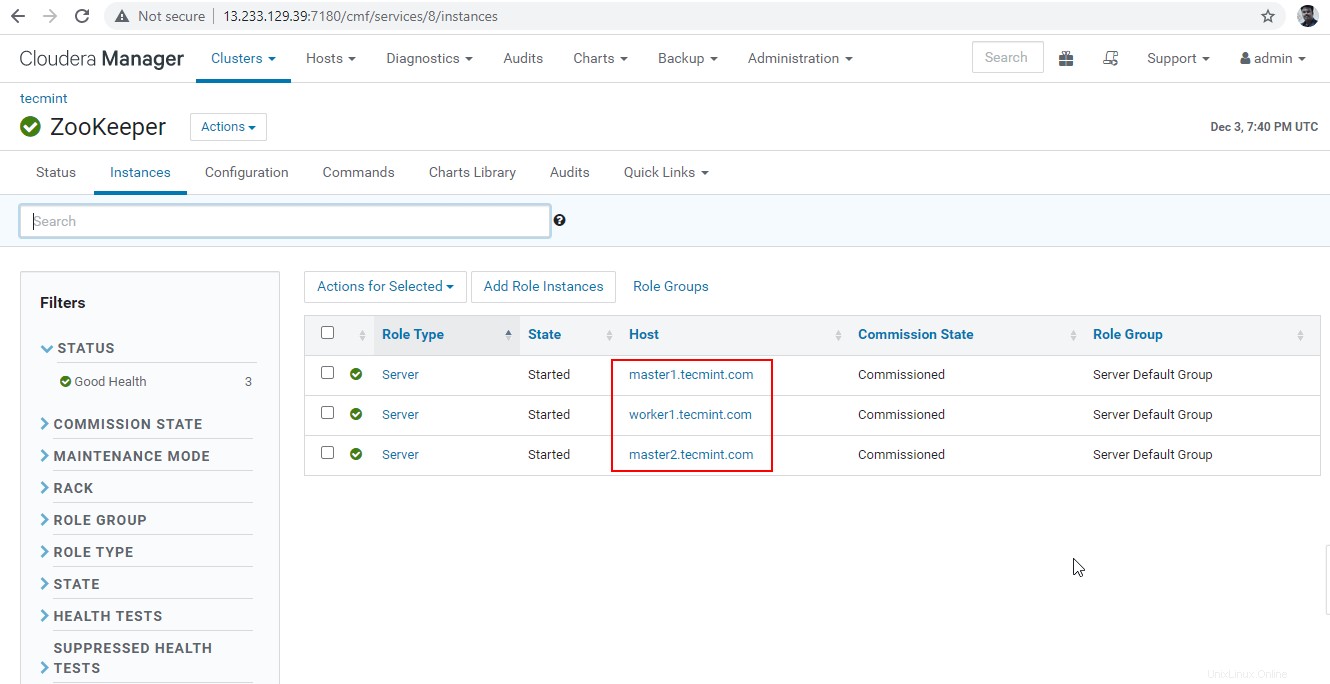
Estos son los tres servidores que tienen Zookeeper, 2181 es el número de puerto.
master1.tecmint.com:2181 master2.tecmint.com:2181 worker1.tecmint.com:2181
[[email protected] ~]$ beeline

beeline>!connect "jdbc:hive2://master1.tecmint.com:2181,master2.tecmint.com:2181,worker1.tecmint.com:2181/;serviceDiscoveryMode=zookeeper;zookeeperNamespace=hiveserver2"

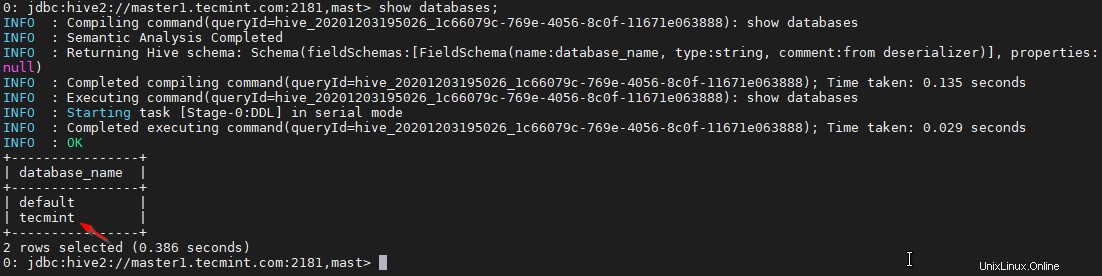
0: jdbc:hive2://master1.tecmint.com:2181,mast> create database tecmint;

0: jdbc:hive2://master1.tecmint.com:2181,mast> show databases;
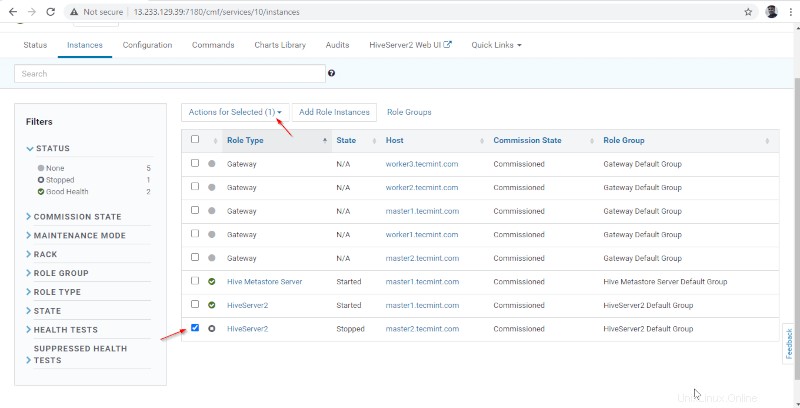
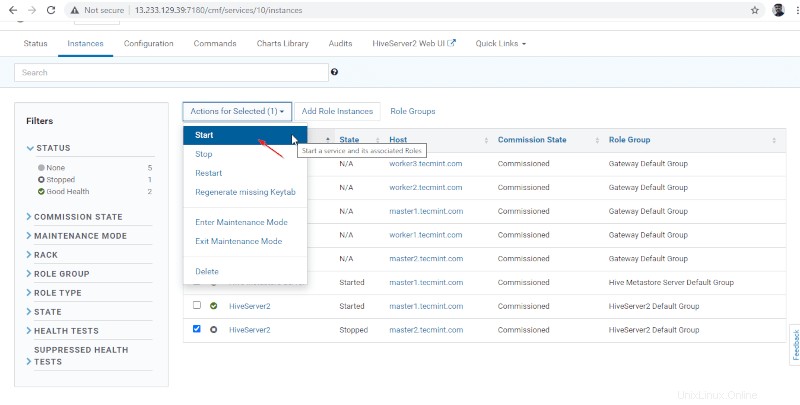
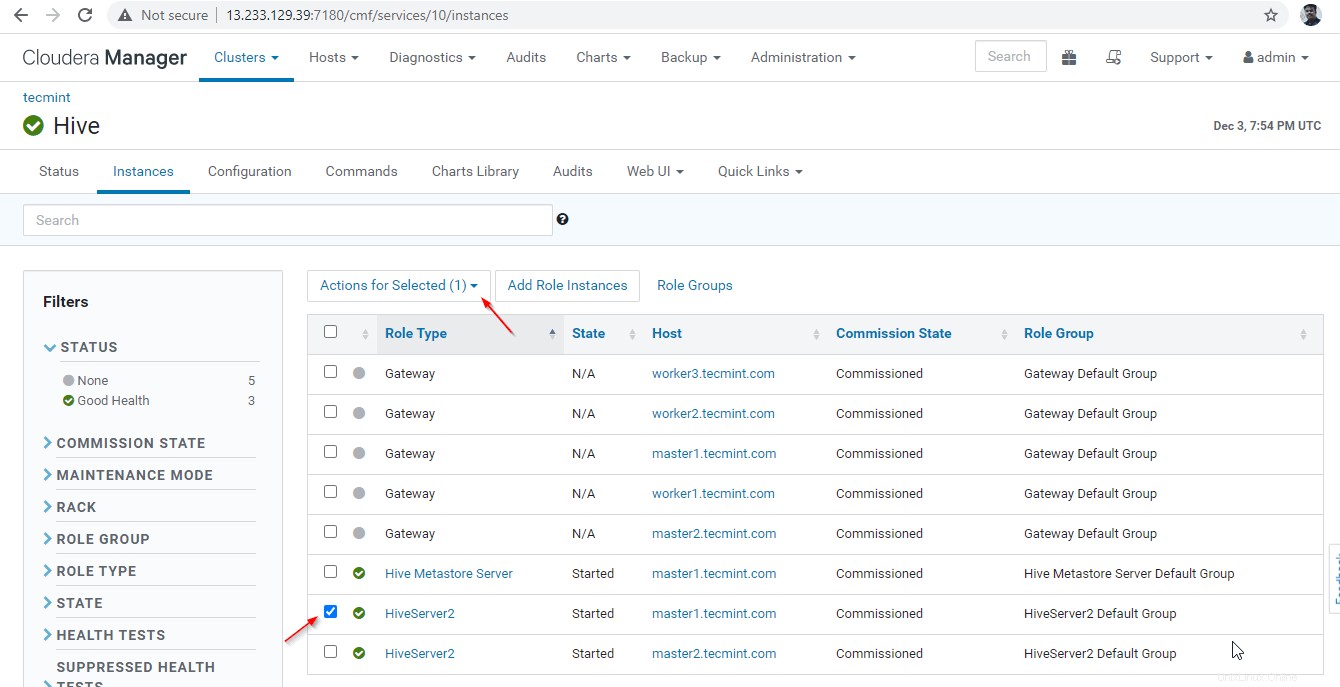
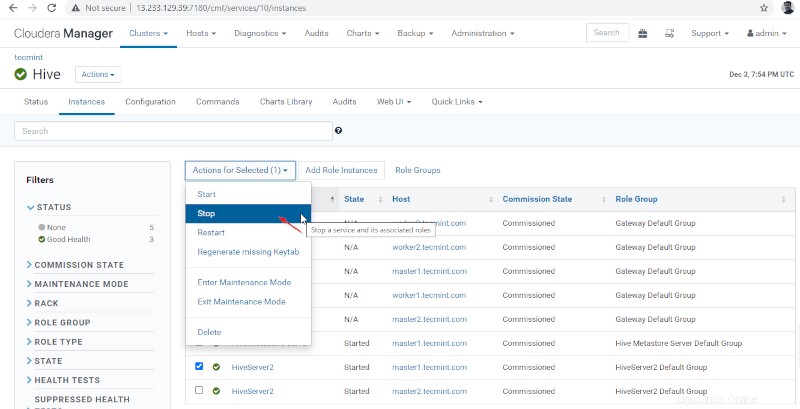
Administrador de Cloudera –> Colmena –> Instancias –> (seleccione Hiveserver2 en maestro1 ) –> Acción para seleccionados –> Parar .
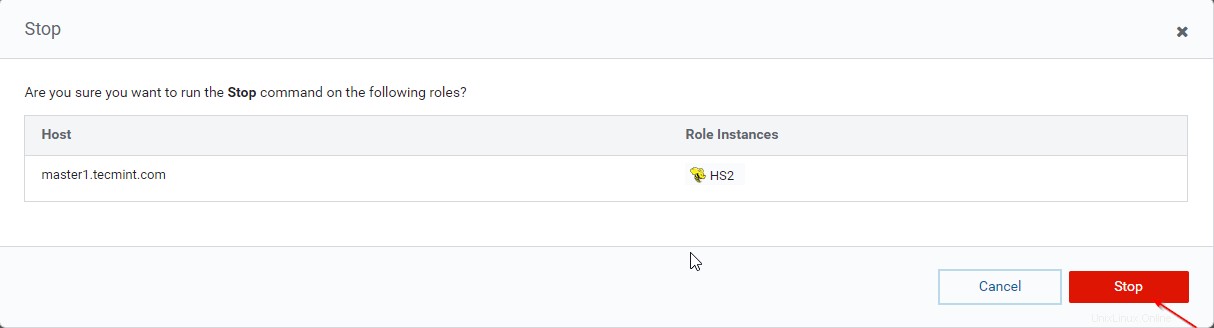
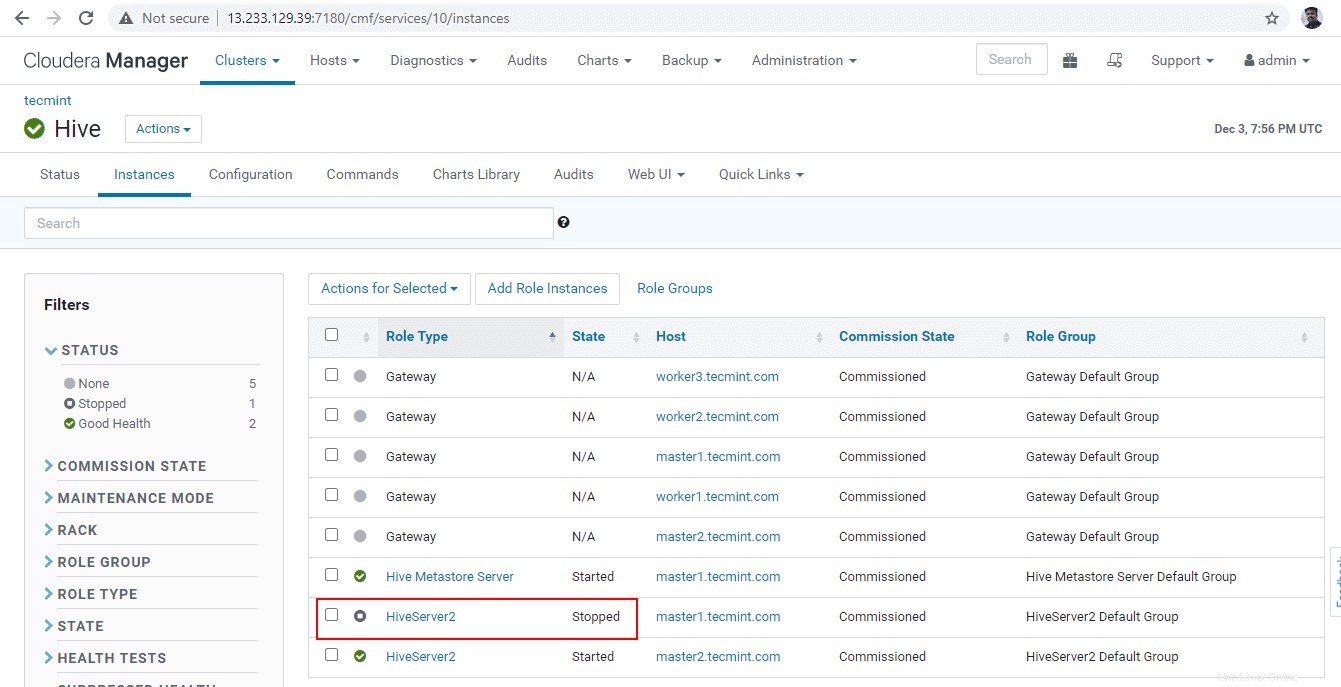
[[email protected] ~]$ beeline beeline>!connect "jdbc:hive2://master1.tecmint.com:2181,master2.tecmint.com:2181,worker1.tecmint.com:2181/;serviceDiscoveryMode=zookeeper;zookeeperNamespace=hiveserver2"

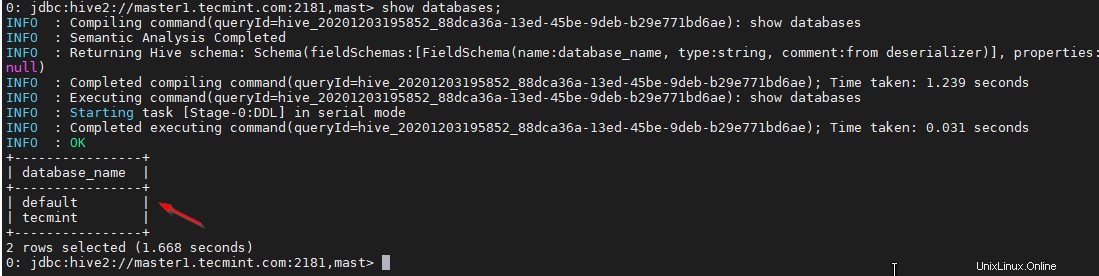
Ahora estará conectado a Hiveserver2 ejecutándose en master2 .
0: jdbc:hive2://master1.tecmint.com:2181,mast> show databases;
Conclusión
En este artículo, hemos seguido los pasos detallados para tener el almacén de datos de Hive modelo en nuestro Cluster con alta disponibilidad . En un entorno de producción en tiempo real, más de tres Hiveserver2 se colocará con Modo de descubrimiento de Zookeeper activado.
Aquí, todos los Hiveserver2 se están registrando en Zookeeper bajo un espacio de nombres común . Zookeeper dinámicamente descubre el Hiveserver2 disponible y establece la sesión de Hive.