Trabajo a tiempo parcial como auditor de datos. Piense en mí como un corrector de pruebas que trabaja con tablas de datos en lugar de páginas de prosa. Las tablas se exportan desde bases de datos relacionales y suelen tener un tamaño bastante modesto:de 100 000 a 1 000 000 de registros y de 50 a 200 campos.
Nunca he visto una tabla de datos sin errores. El desorden no se limita, como se podría pensar, a registros duplicados, errores ortográficos y de formato, y elementos de datos colocados en el campo incorrecto. También encuentro:
- registros rotos repartidos en varias líneas porque los elementos de datos tenían saltos de línea incrustados
- elementos de datos en un campo que no están de acuerdo con elementos de datos en otro campo, en el mismo registro
- registros con elementos de datos truncados, a menudo porque cadenas muy largas se calzaron en campos con límites de 50 o 100 caracteres
- fallas en la codificación de caracteres que producen el galimatías conocido como mojibake
- caracteres de control invisibles, algunos de los cuales pueden causar errores de procesamiento de datos
- Caracteres de reemplazo y signos de interrogación misteriosos insertados por el último programa que no entendió la codificación de caracteres de los datos
Limpiar estos problemas no es difícil, pero existen obstáculos no técnicos para encontrarlos. El primero es la renuencia natural de todos a lidiar con errores de datos. Antes de ver una tabla, es posible que los propietarios o administradores de datos hayan pasado por las cinco etapas de Data Grief:
- No hay errores en nuestros datos.
- Bueno, tal vez haya algunos errores, pero no son tan importantes.
- Bien, hay muchos errores; haremos que nuestra gente interna se encargue de ellos.
- Hemos comenzado a corregir algunos de los errores, pero lleva mucho tiempo; lo haremos cuando migremos al nuevo software de base de datos.
- No tuvimos tiempo de limpiar los datos al pasar a la nueva base de datos; nos vendría bien un poco de ayuda.
La segunda actitud que bloquea el progreso es la creencia de que la limpieza de datos requiere aplicaciones dedicadas, ya sean costosos programas propietarios o el excelente programa de código abierto OpenRefine. Para lidiar con problemas que las aplicaciones dedicadas no pueden resolver, los administradores de datos pueden pedir ayuda a un programador, alguien que sepa usar Python o R.
Pero la auditoría y la limpieza de datos generalmente no requieren aplicaciones dedicadas. Las tablas de datos de texto sin formato existen desde hace muchas décadas, al igual que las herramientas de procesamiento de texto. Abra un shell Bash y tendrá una caja de herramientas cargada con potentes procesadores de texto como grep , cut , paste , sort , uniq , tr y awk . Son rápidos, confiables y fáciles de usar.
Realizo todas mis auditorías de datos en la línea de comandos, y puse muchos de mis trucos de auditoría de datos en un sitio web de "libro de cocina". Las operaciones que realizo regularmente se almacenan como funciones y scripts de shell (consulte el ejemplo a continuación).
Sí, un enfoque de línea de comandos requiere que los datos que se van a auditar se hayan exportado desde la base de datos. Y sí, los resultados de la auditoría deben editarse más tarde dentro de la base de datos o (si la base de datos lo permite) los elementos de datos limpios deben importarse como reemplazo de los desordenados.
Pero las ventajas son notables. awk procesará algunos millones de registros en segundos en una computadora de escritorio o portátil de nivel de consumidor. Las expresiones regulares sin complicaciones encontrarán todos los errores de datos que pueda imaginar. Y todo esto sucederá de manera segura afuera la estructura de la base de datos:la auditoría de línea de comandos no puede afectar la base de datos, porque funciona con datos liberados de su prisión de base de datos.
Los lectores que entrenaron en Unix estarán sonriendo con aire de suficiencia en este punto. Recuerdan haber manipulado datos en la línea de comandos hace muchos años de esta manera. Lo que ha sucedido desde entonces es que la potencia de procesamiento y la memoria RAM han aumentado espectacularmente, y las herramientas de línea de comandos estándar se han vuelto sustancialmente más eficientes. La auditoría de datos nunca ha sido más rápida o fácil. Y ahora que Microsoft Windows 10 puede ejecutar programas Bash y GNU/Linux, los usuarios de Windows pueden apreciar el lema de Unix y Linux para manejar datos desordenados:Mantenga la calma y abra una terminal.

Un ejemplo
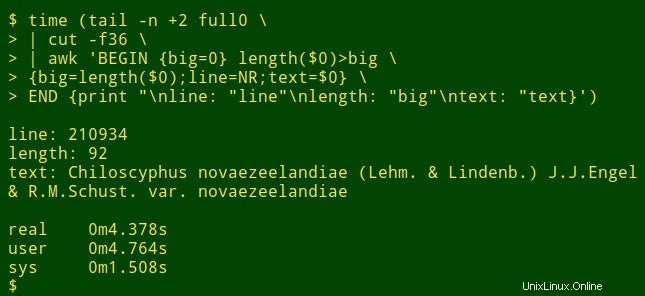
Supongamos que quiero encontrar el elemento de datos más largo en un campo particular de una tabla grande. Esa no es realmente una tarea de auditoría de datos, pero mostrará cómo funcionan las herramientas de shell. Para fines de demostración, usaré la tabla separada por tabuladores full0 , que tiene 1 122 023 registros (más una línea de encabezado) y 49 campos, y buscaré en el campo número 36. (Obtengo números de campo con una función explicada en mi sitio de libros de cocina).
El comando comienza usando tail para eliminar la línea de encabezado de full0 . El resultado se canaliza a cut , que extrae el campo decapitado 36. El siguiente en la canalización es awk . Aquí la variable big se inicializa a un valor de 0; entonces awk comprueba la longitud del elemento de datos en el primer registro. Si la longitud es mayor que 0, awk restablece big a la nueva longitud y almacena el número de línea (NR) en la variable line y el elemento de datos completo en la variable text . awk luego procesa cada uno de los 1.122.022 registros restantes por turno, restableciendo las tres variables cuando encuentra un elemento de datos más largo. Finalmente, imprime una lista claramente separada de números de línea, longitud del elemento de datos y texto completo del elemento de datos más largo. (En el siguiente código, los comandos se han dividido en varias líneas para mayor claridad).
<code>tail -n +2 full0 \
> | cut -f36 \
> | awk 'BEGIN {big=0} length($0)>big \
> {big=length($0);line=NR;text=$0} \
> END {print "\nline: "line"\nlength: "big"\ntext: "text}' </code>
¿Cuánto tiempo lleva esto? Unos 4 segundos en mi escritorio (core i5, 8 GB de RAM):
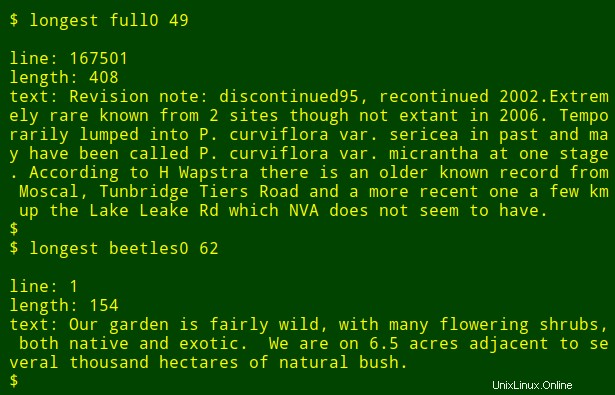
Ahora, la parte ordenada:puedo insertar ese comando largo en una función de shell, longest , que toma como argumentos el nombre de archivo ($1) y el número de campo ($2) :

Luego puedo volver a ejecutar el comando como una función, encontrando elementos de datos más largos en otros campos y en otros archivos sin necesidad de recordar cómo está escrito el comando:
Como ajuste final, puedo agregar a la salida el nombre del campo numerado que estoy buscando. Para hacer esto, uso head para extraer la línea de encabezado de la tabla, canalice esa línea a tr para convertir tabulaciones en líneas nuevas y canalizar la lista resultante a tail y head para imprimir el $2th nombre de campo en la lista, donde $2 es el argumento del número de campo. El nombre del campo se almacena en la variable de shell field y pasó a awk para imprimir como el awk interno variable fld .
<code>longest() { field=$(head -n 1 "$1" | tr '\t' '\n' | tail -n +"$2" | head -n 1); \
tail -n +2 "$1" \
| cut -f"$2" | \
awk -v fld="$field" 'BEGIN {big=0} length($0)>big \
{big=length($0);line=NR;text=$0}
END {print "\nfield: "fld"\nline: "line"\nlength: "big"\ntext: "text}'; }</code> 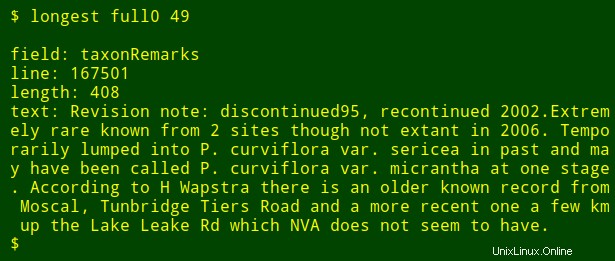
Tenga en cuenta que si estoy buscando el elemento de datos más largo en varios campos diferentes, todo lo que tengo que hacer es presionar la tecla de flecha hacia arriba para obtener el último longest comando, luego retroceda el número de campo e ingrese uno nuevo.