El análisis forense de una imagen de disco de Linux suele ser parte de la respuesta a incidentes para determinar si se ha producido una infracción. El análisis forense de Linux es un mundo diferente y fascinante en comparación con el análisis forense de Microsoft Windows. En este artículo, analizaré una imagen de disco de un sistema Linux potencialmente comprometido para determinar quién, qué, cuándo, dónde, por qué y cómo del incidente y crear cronogramas de eventos y sistemas de archivos. Finalmente, extraeré artefactos de interés de la imagen del disco.
En este tutorial, utilizaremos algunas herramientas nuevas y algunas herramientas antiguas en formas nuevas y creativas de realizar un análisis forense de una imagen de disco.
El escenario
Más recursos de Linux
- Hoja de trucos de los comandos de Linux
- Hoja de trucos de comandos avanzados de Linux
- Curso en línea gratuito:Descripción general técnica de RHEL
- Hoja de trucos de red de Linux
- Hoja de trucos de SELinux
- Hoja de trucos de los comandos comunes de Linux
- ¿Qué son los contenedores de Linux?
- Nuestros últimos artículos sobre Linux
Premiere Fabrication Engineering (PFE) sospecha que ha habido un incidente o compromiso relacionado con el servidor principal de la empresa llamado pfe1. Creen que el servidor puede haber estado involucrado en un incidente y puede haber estado comprometido en algún momento entre el primero y el último de marzo. Han contratado mis servicios como examinador forense para investigar si el servidor se vio comprometido e involucrado en un incidente. La investigación determinará quién, qué, cuándo, dónde, por qué y cómo detrás del posible compromiso. Además, PFE ha solicitado mis recomendaciones para medidas de seguridad adicionales para sus servidores.
La imagen del disco
Para realizar el análisis forense del servidor, solicito a PFE que me envíe una imagen de disco forense de pfe1 en una unidad USB. Están de acuerdo y dicen:"el USB está en el correo". Llega la unidad USB y empiezo a examinar su contenido. Para realizar el análisis forense, utilizo una máquina virtual (VM) que ejecuta la distribución SANS SIFT. SIFT Workstation es un grupo de herramientas forenses y de respuesta a incidentes gratuitas y de código abierto diseñadas para realizar exámenes forenses digitales detallados en una variedad de entornos. SIFT tiene una amplia gama de herramientas forenses, y si no tiene la herramienta que quiero, puedo instalar una sin mucha dificultad ya que es una distribución basada en Ubuntu.
Tras examinarlo, descubrí que el USB no contiene una imagen de disco, sino copias de los archivos de host de VMware ESX, que son archivos VMDK de la nube híbrida de PFE. Esto no era lo que esperaba. Tengo varias opciones:
- Puedo comunicarme con PFE y ser más explícito sobre lo que espero de ellos. Al principio de un compromiso como este, puede que no sea lo mejor que se puede hacer.
- Puedo cargar los archivos VMDK en una herramienta de virtualización como VMPlayer y ejecutarlo como una VM en vivo usando sus programas nativos de Linux para realizar análisis forenses. Hay al menos tres razones para no hacerlo. Primero, las marcas de tiempo en los archivos y el contenido de los archivos se modificarán cuando se ejecuten los archivos VMDK como un sistema en vivo. En segundo lugar, dado que se cree que el servidor está comprometido, todos los archivos y programas de los sistemas de archivos VMDK deben considerarse comprometidos. En tercer lugar, el uso de programas nativos en un sistema comprometido para realizar un análisis forense puede tener consecuencias imprevistas.
- Para analizar los archivos VMDK, podría usar el paquete libvmdk-utils que contiene herramientas para acceder a los datos almacenados en los archivos VMDK.
- Sin embargo, un mejor enfoque es convertir el formato de archivo VMDK al formato RAW. Esto facilitará la ejecución de las diferentes herramientas de la distribución SIFT en los archivos de la imagen del disco.
Para convertir de VMDK a formato RAW, utilizo la utilidad qemu-img, que permite crear, convertir y modificar imágenes sin conexión. La siguiente figura muestra el comando para convertir el formato VMDK a formato RAW.

A continuación, necesito enumerar la tabla de particiones de la imagen del disco y obtener información sobre dónde comienza cada partición (sectores) usando la utilidad mmls. Esta utilidad muestra el diseño de las particiones en un sistema de volumen, incluidas las tablas de partición y las etiquetas de disco. Luego uso el sector inicial y consulto los detalles asociados con el sistema de archivos usando la utilidad fsstat, que muestra los detalles asociados con un sistema de archivos. Las siguientes figuras muestran los mmls y fsstat comandos en funcionamiento.
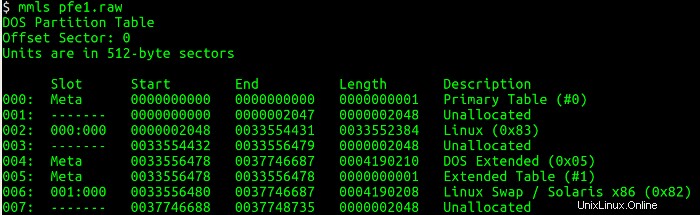
Aprendo varias cosas interesantes de los mmls salida:una partición primaria de Linux comienza en el sector 2048 y tiene un tamaño aproximado de 8 gigabytes. Una partición de DOS, probablemente la partición de arranque, tiene un tamaño aproximado de 8 megabytes. Finalmente, hay una partición de intercambio de aproximadamente 8 gigabytes.
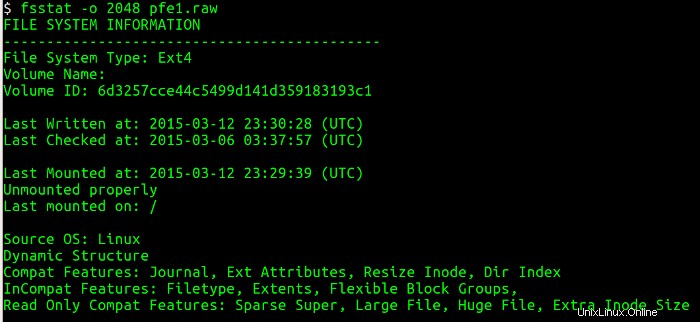
Ejecutando fsstat me dice muchas cosas útiles sobre la partición:el tipo de sistema de archivos, la última vez que se escribieron datos en el sistema de archivos, si el sistema de archivos se desmontó limpiamente y dónde se montó el sistema de archivos.
Estoy listo para montar la partición y comenzar el análisis. Para hacer esto, necesito leer las tablas de partición en la imagen sin procesar especificada y crear mapas de dispositivos sobre los segmentos de partición detectados. Podría hacerlo a mano con la información de mmls y fsstat —o podría usar kpartx para que lo haga por mí.

Uso opciones para crear un mapeo de solo lectura (-r ), agregar asignación de partición (-a ), y dar una salida detallada (-v ). El loop0p1 es el nombre de un archivo de dispositivo bajo /dev/mapper Puedo usar para acceder a la partición. Para montarlo, ejecuto:
$ mount -o ro -o loop=/dev/mapper/loop0p1 pf1.raw /mnt
Tenga en cuenta que estoy montando la partición como de solo lectura (-o ro ) para evitar la contaminación accidental.
Después de montar el disco, comienzo mi análisis e investigación forense creando una línea de tiempo. Algunos examinadores forenses no creen en la creación de una línea de tiempo. En cambio, una vez que tienen una partición montada, se arrastran por el sistema de archivos en busca de artefactos que puedan ser relevantes para la investigación. Etiqueto a estos examinadores forenses como "enredaderas". Si bien esta es una forma de realizar una investigación forense, está lejos de ser repetible, es propensa a errores y puede pasar por alto evidencia valiosa.
Creo que crear una línea de tiempo es un paso crucial porque incluye información útil sobre los archivos que se modificaron, accedieron, cambiaron y crearon en un formato legible por humanos, conocido como evidencia de tiempo MAC (modificado, accedido, cambiado). Esta actividad ayuda a identificar la hora específica y el orden en que se llevó a cabo un evento.
Notas sobre los sistemas de archivos de Linux
Los sistemas de archivos de Linux como ext2 y ext3 no tienen marcas de tiempo para la creación/hora de nacimiento de un archivo. La marca de tiempo de creación se introdujo en ext4. El libro Descubrimiento forense (primera edición) de Dan Farmer y Wietse Venema describe las diferentes marcas de tiempo.
- Hora de la última modificación: Para los directorios, esta es la última vez que se agregó, renombró o eliminó una entrada. Para otros tipos de archivos, es la última vez que se escribió el archivo.
- Hora del último acceso (lectura): Para directorios, esta es la última vez que se buscó. Para otros tipos de archivos, es la última vez que se leyó el archivo.
- Último cambio de estado: Ejemplos de cambios de estado son el cambio de propietario, el cambio de permiso de acceso, el cambio de recuento de enlaces fijos o un cambio explícito de cualquiera de los tiempos de MAC.
- Tiempo de eliminación: ext2 y ext3 registran la hora en que se eliminó un archivo en el
dtimemarca de tiempo, pero no todas las herramientas lo admiten. - Hora de creación: ext4fs registra la hora en que se creó el archivo en el
crtimemarca de tiempo, pero no todas las herramientas lo admiten.
Las diferentes marcas de tiempo se almacenan en los metadatos contenidos en los inodos. Los inodos son similares al número de entrada de MFT en el mundo de Windows. Una forma de leer los metadatos del archivo en un sistema Linux es obtener primero el número de inodo usando el comando ls -i file luego usa istat contra el dispositivo de partición y especifique el número de inodo. Esto le mostrará los diferentes atributos de los metadatos, incluidas las marcas de tiempo, el tamaño del archivo, el grupo del propietario y la identificación del usuario, los permisos y los bloques que contienen los datos reales.
Creación de la súper línea de tiempo
Mi siguiente paso es crear una súper línea de tiempo usando log2timeline/plaso. Plaso es una reescritura basada en Python de la herramienta log2timeline basada en Perl creada inicialmente por Kristinn Gudjonsson y mejorada por otros. Es fácil hacer una súper línea de tiempo con log2timeline, pero la interpretación es difícil. La última versión del motor plaso puede analizar ext4 así como diferentes tipos de artefactos, como mensajes de syslog, auditoría, utmp y otros.
Para crear la súper línea de tiempo, ejecuto log2timeline en la carpeta del disco montado y uso los analizadores de Linux. Este proceso lleva algún tiempo; cuando termina, tengo una línea de tiempo con los diferentes artefactos en formato de base de datos plaso, luego puedo usar psort.py para convertir la base de datos plaso en cualquier número de formatos de salida diferentes. Para ver los formatos de salida que psort.py admite, introduzca psort -o list . Usé psort.py para crear una súper línea de tiempo con formato de Excel. La siguiente figura describe los pasos para realizar esta operación.

(Nota:líneas superfluas eliminadas de las imágenes)

Importo la súper línea de tiempo a un programa de hoja de cálculo para facilitar la visualización, clasificación y búsqueda. Si bien puede ver una súper línea de tiempo en un programa de hoja de cálculo, es más fácil trabajar con ella en una base de datos real como MySQL o Elasticsearch. Creo una segunda súper línea de tiempo y la envío directamente a una instancia de Elasticsearch desde psort.py . Una vez que Elasticsearch indexó la súper línea de tiempo, puedo visualizar y analizar los datos con Kibana.

Investigando con Elasticsearch/Kibana
Como dijo el sargento mayor Farrell:"A través de la preparación y la disciplina, somos dueños de nuestro destino". Durante el análisis, vale la pena ser paciente y meticuloso y evitar ser un enredadera. Una cosa que ayuda a un análisis de línea de tiempo súper es tener una idea de cuándo pudo haber ocurrido el incidente. En este caso (juego de palabras), el cliente dice que el incidente pudo haber ocurrido en marzo. Todavía considero la posibilidad de que el cliente esté equivocado sobre el plazo. Armado con esta información, empiezo a reducir el marco de tiempo de la súper línea de tiempo y a reducirlo. Estoy buscando artefactos de interés que tengan una "proximidad temporal" con la supuesta fecha del incidente. El objetivo es recrear lo que sucedió en base a diferentes artefactos.
Para reducir el alcance de la súper línea de tiempo, utilizo la instancia de Elasticsearch/Kibana que configuré. Con Kibana, puedo configurar cualquier cantidad de paneles complejos para mostrar y correlacionar eventos forenses de interés, pero quiero evitar este nivel de complejidad. En su lugar, selecciono índices de interés para mostrar y creo un gráfico de barras de actividad por fecha:
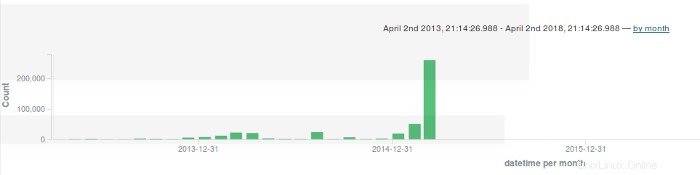
El siguiente paso es expandir la barra grande al final del gráfico:

Hay un bar grande el 5 de marzo. Amplío esa barra para ver la actividad en esa fecha en particular:
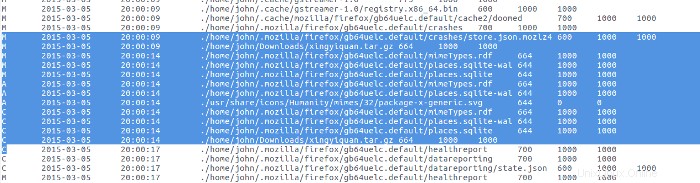
Mirando la actividad del archivo de registro de la línea de tiempo súper, veo que esta actividad fue de una instalación/actualización de software. Hay muy poco que encontrar en esta área de actividad.
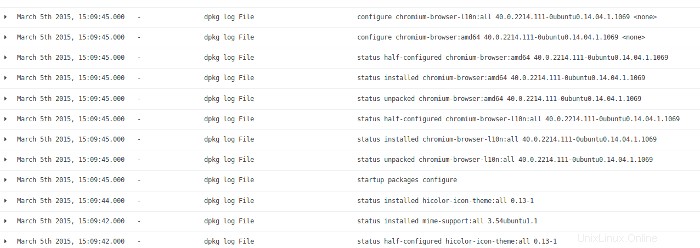
Vuelvo a Kibana para ver el último conjunto de actividades en el sistema y encuentro esto en los registros:
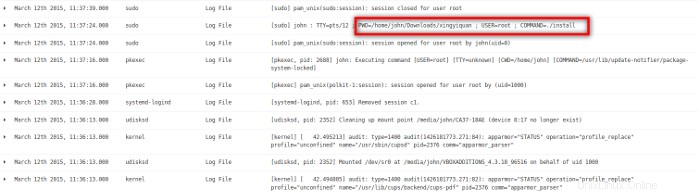
Una de las últimas actividades en el sistema fue que el usuario john instaló un programa desde un directorio llamado xingyiquan. Xing Yi Quan es un estilo de artes marciales chinas similar al Kung Fu y al Tai Chi Quan. Parece extraño que el usuario john instale un programa de artes marciales en un servidor de la empresa desde su propia cuenta de usuario. Uso la capacidad de búsqueda de Kibana para encontrar otras instancias de xingyiquan en los archivos de registro. Encontré tres períodos de actividad alrededor de la cuerda xingyiquan el 5 de marzo, el 9 de marzo y el 12 de marzo.

A continuación, miro las entradas de registro de estos días. Comienzo con el 5 de marzo y encuentro evidencia de una búsqueda en Internet usando el navegador Firefox y el motor de búsqueda de Google para un rootkit llamado xingyiquan. La búsqueda en Google encontró la existencia de un rootkit de este tipo en packagestormsecurity.com. Luego, el navegador fue a packagestormsecurity.com y descargó un archivo llamado xingyiquan.tar.gz desde ese sitio al directorio de descargas del usuario john.
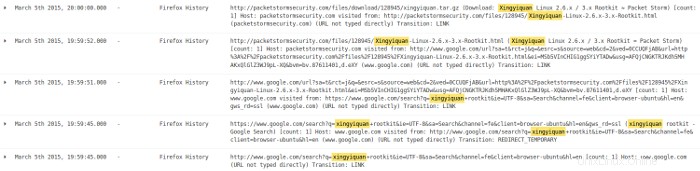
Aunque parece que el usuario john fue a google.com para buscar el rootkit y luego a packagestormsecurity.com para descargar el rootkit, estas entradas de registro no indican el usuario detrás de la búsqueda y la descarga. Necesito investigar más sobre esto.
El navegador Firefox mantiene la información de su historial en una base de datos SQLite bajo el .mozilla directorio en el directorio de inicio de un usuario (es decir, el usuario john) en un archivo llamado places.sqlite . Para ver la información en la base de datos, uso un programa llamado sqlitebrowser. Es una aplicación GUI que permite a un usuario profundizar en una base de datos SQLite y ver los registros almacenados allí. Lancé sqlitebrowser e importé places.sqlite desde el .mozilla directorio bajo el directorio de inicio del usuario john. Los resultados se muestran a continuación.

El número de la columna de la derecha es la marca de tiempo de la actividad de la izquierda. Como prueba de congruencia, convertí la marca de tiempo 1425614413880000 al tiempo humano y obtuvo el 5 de marzo de 2015, 8:00:13.880 p. m. Esto coincide estrechamente con la hora del 5 de marzo de 2015, 20:00:00.000 de Kibana. Podemos decir con certeza razonable que el usuario john buscó un rootkit llamado xingyiquan y descargó un archivo de packagestormsecurity.com llamado xingyiquan.tar.gz al directorio de descargas del usuario john.
Investigando con MySQL
En este punto, decido importar la súper línea de tiempo a una base de datos MySQL para obtener una mayor flexibilidad en la búsqueda y manipulación de datos de lo que permite Elasticsearch/Kibana por sí solo.
Construyendo el rootkit xingyiquan
Cargo la super línea de tiempo que creé desde la base de datos plaso en una base de datos MySQL. Por trabajar con Elasticsearch/Kibana, sé que el usuario john descargó el rootkit xingyiquan.tar.gz desde packagestormsecurity.com al directorio de descarga. Aquí hay evidencia de la actividad de descarga de la base de datos de la línea de tiempo de MySQL:
Poco después de descargar el rootkit, la fuente de tar.gz se extrajo el archivo.
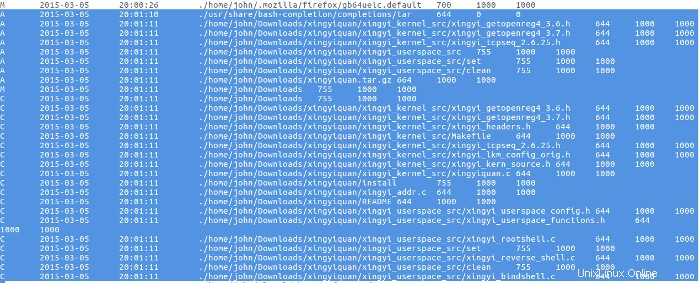
No se hizo nada con el rootkit hasta el 9 de marzo, cuando el malhechor leyó el archivo README del rootkit con el programa More, luego compiló e instaló el rootkit.
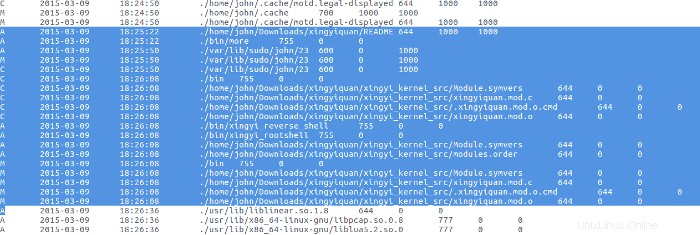
Historial de comandos
Cargo historiales de todos los usuarios en pfe1 que tienen bash historiales de comandos en una tabla en la base de datos MySQL. Una vez que se cargan los historiales, puedo mostrarlos fácilmente mediante una consulta como:
select * from histories order by recno; Para obtener un historial de un usuario específico, utilizo una consulta como:
select historyCommand from histories where historyFilename like '%<username>%' order by recno;
Encuentro varios comandos interesantes del bash del usuario john historia. Es decir, el usuario john creó la cuenta johnn, la eliminó, la creó de nuevo, copió /bin/true a /bin/false , dio contraseñas a las cuentas whoopsie y lightdm, copió /bin/bash a /bin/false , editó la contraseña y los archivos de grupo, movió el directorio de inicio del usuario johnn de johnn a .johnn , (haciéndolo un directorio oculto), cambió el archivo de contraseña usando sed después de buscar cómo usar
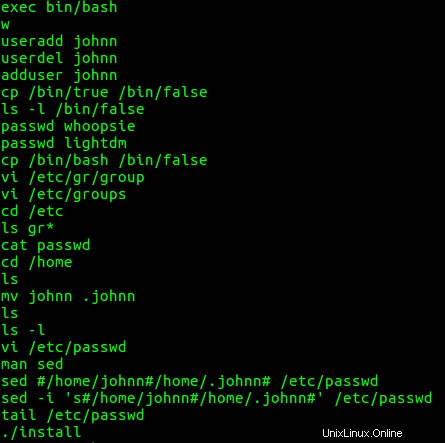
A continuación, miro el bash historial de comandos para el usuario johnn. No mostró ninguna actividad inusual.
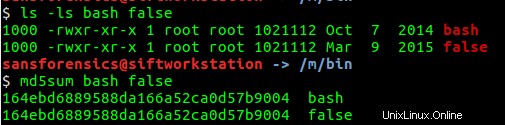
Notando que el usuario john copió /bin/bash a /bin/false , pruebo si esto era cierto comprobando los tamaños de estos archivos y obteniendo un hash MD5 de los archivos. Como se muestra a continuación, los tamaños de archivo y los valores hash MD5 son los mismos. Por lo tanto, los archivos son los mismos.
Investigación de inicios de sesión exitosos y fallidos
Para responder parte de la pregunta "cuándo", cargo los archivos de registro que contienen datos sobre inicios de sesión, cierres de sesión, inicios y apagados del sistema en una tabla en la base de datos MySQL. Usando una consulta simple como:
select * from logins order by start Encuentro la siguiente actividad:

A partir de esta figura, veo que el usuario john inició sesión en pfe1 desde la dirección IP 192.168.56.1 . Cinco minutos después, el usuario johnn inició sesión en pfe1 desde la misma dirección IP. Dos inicios de sesión del usuario lightdm siguieron cuatro minutos después y otro un minuto después, luego el usuario johnn inició sesión menos de un minuto después. Luego se reinició pfe1.
Mirando los inicios de sesión fallidos, encuentro esta actividad:

Nuevamente, el usuario lightdm intentó iniciar sesión en pfe1 desde la dirección IP 192.168.56.1 . A la luz de las cuentas falsas que inician sesión en pfe1, una de mis recomendaciones para PFE será verificar el sistema con la dirección IP 192.168.56.1 para evidencia de compromiso.
Investigando archivos de registro
Este análisis de inicios de sesión exitosos y fallidos brinda información valiosa sobre cuándo ocurrieron los eventos. Dirijo mi atención a investigar los archivos de registro en pfe1, particularmente la actividad de autenticación y autorización en /var/log/auth* . Cargo todos los archivos de registro en pfe1 en una tabla de base de datos MySQL y uso una consulta como:
select logentry from logs where logfilename like '%auth%' order by recno;
y guárdelo en un archivo. Abro ese archivo con mi editor favorito y busco 192.168.56.1 . A continuación se muestra una sección de la actividad:
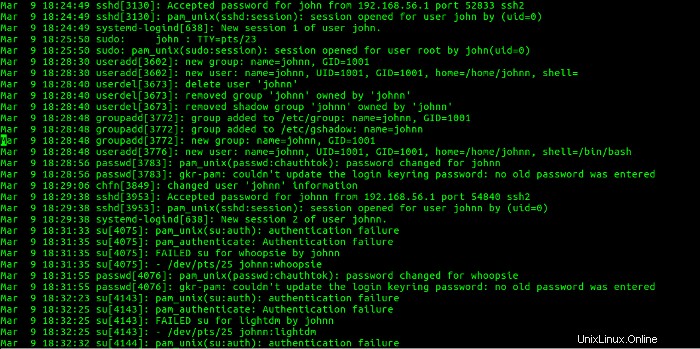
Esta sección muestra que el usuario john inició sesión desde la dirección IP 192.168.56.1 y creó la cuenta de johnn, eliminó la cuenta de johnn y la volvió a crear. Luego, el usuario johnn inició sesión en pfe1 desde la dirección IP 192.168.56.1 . A continuación, el usuario johnn intentó convertirse en usuario whoopsie con un su comando, que falló. Luego, se cambió la contraseña del usuario whoopsie. El usuario johnn luego intentó convertirse en usuario lightdm con un su comando, que también falló. Esto se correlaciona con la actividad que se muestra en las Figuras 21 y 22.
Conclusiones de mi investigación
- El usuario john buscó, descargó, compiló e instaló un rootkit llamado xingyiquan en el servidor pfe1. El rootkit xingyiquan oculta procesos, archivos, directorios, procesos y conexiones de red; agrega puertas traseras; y más.
- El usuario john creó, eliminó y volvió a crear otra cuenta en pfe1 llamada johnn. El usuario john convirtió el directorio de inicio del usuario johnn en un archivo oculto para ocultar la existencia de esta cuenta de usuario.
- El usuario john copió el archivo
/bin/truesobre/bin/falsey luego/bin/bashsobre/bin/falsepara facilitar los inicios de sesión de cuentas del sistema que normalmente no se utilizan para inicios de sesión interactivos. - El usuario john creó contraseñas para las cuentas del sistema whoopsie y lightdm. Estas cuentas normalmente no tienen contraseñas.
- Se inició sesión con éxito en la cuenta de usuario johnn y el usuario johnn intentó sin éxito convertirse en usuarios whoopsie y lightdm.
- El servidor pfe1 se ha visto seriamente comprometido.
Mis recomendaciones para PFE
- Reconstruya el servidor pfe1 a partir de la distribución original y aplique todos los parches pertinentes al sistema antes de volver a ponerlo en servicio.
- Configure un servidor syslog centralizado y haga que todos los sistemas en la nube híbrida de PFE se registren en el servidor syslog centralizado y a los registros locales para consolidar los datos de registro y evitar la manipulación de los registros del sistema. Use un producto de monitoreo de eventos e información de seguridad (SIEM) para facilitar la revisión y correlación de eventos de seguridad.
- Implementar
bashmarcas de tiempo de comandos en todos los servidores de la empresa. - Habilite el registro de auditoría de la cuenta raíz en todos los servidores PFE y dirija los registros de auditoría al servidor syslog centralizado donde se pueden correlacionar con otra información de registro.
- Investigar el sistema con la dirección IP
192.168.56.1por infracciones y compromisos, ya que se utilizó como punto de pivote en el compromiso de pfe1.
Si ha utilizado análisis forenses para analizar su sistema de archivos Linux en busca de compromisos, comparta sus consejos y recomendaciones en los comentarios.
Gary Smith hablará en LinuxFest Northwest este año. Vea los aspectos destacados del programa o regístrese para asistir.