Introducción
La falta de datos es un problema común cuando se trabaja con conjuntos de datos realistas. Conocer y analizar las causas de los valores faltantes ayuda a proporcionar una imagen más clara de los pasos para resolver el problema. Python proporciona muchos métodos para analizar y resolver el problema de los datos no contabilizados.
Este tutorial explica las causas y soluciones de la falta de datos a través de un ejemplo práctico en Python.

Requisitos previos
- Python 3 instalado y configurado
- Módulos Pandas y NumPy instalados
- Un conjunto de datos con valores perdidos
¿Cómo afecta la falta de datos a su algoritmo?
Hay tres formas en que los datos faltantes afectan su algoritmo e investigación:
- Los valores faltantes brindan una idea incorrecta sobre los datos en sí, lo que genera ambigüedad. . Por ejemplo, calcular un promedio para una columna con la mitad de la información no disponible o establecida en cero da una métrica incorrecta.
- Cuando los datos no están disponibles, algunos algoritmos no funcionan. Algunos algoritmos de aprendizaje automático con conjuntos de datos que contienen NaN (No es un número) los valores arrojan un error.
- El patrón de datos faltantes es un factor esencial. Si faltan datos de un conjunto de datos al azar, la información sigue siendo útil en la mayoría de los casos. Sin embargo, si sistemáticamente falta información, todo el análisis está sesgado.
¿Qué puede causar la falta de datos?
La causa de la falta de datos depende de los métodos de recopilación de datos. Identificar la causa ayuda a determinar qué camino tomar al analizar un conjunto de datos.
Estos son algunos ejemplos de por qué los conjuntos de datos tienen valores perdidos:
Encuestas . Los datos recopilados a través de encuestas a menudo tienen información faltante. Ya sea por razones de privacidad o simplemente por no saber la respuesta a una pregunta específica, los cuestionarios a menudo tienen datos faltantes.
Internet de las Cosas . Surgen muchos problemas cuando se trabaja con dispositivos IoT y se recopilan datos de sistemas de sensores a servidores informáticos de borde. Una pérdida temporal de comunicación o un sensor que funciona mal a menudo hace que se pierdan datos.
Acceso restringido . Algunos datos tienen acceso limitado, especialmente los datos protegidos por HIPAA, GDPR y otras regulaciones.
Error manual . Los datos ingresados manualmente generalmente tienen inconsistencias debido a la naturaleza del trabajo o la gran cantidad de información.
¿Cómo manejar los datos que faltan?
Para analizar y explicar el proceso de cómo manejar los datos faltantes en Python, usaremos:
- Conjunto de datos de permisos de construcción de San Francisco
- Entorno de Jupyter Notebook
Las ideas se aplican a diferentes conjuntos de datos, así como a otros IDE y editores de Python.
Importar y ver los datos
Descargue el conjunto de datos y copie la ruta del archivo Utilizando la biblioteca de Pandas, importar y almacenar los Permisos_de_construcción.csv datos en una variable:
import pandas as pd
data = pd.read_csv('<path to Building_Permits.csv>')Para confirmar que los datos se importaron correctamente, ejecute:
data.head()El comando muestra las primeras líneas de los datos en formato tabular:
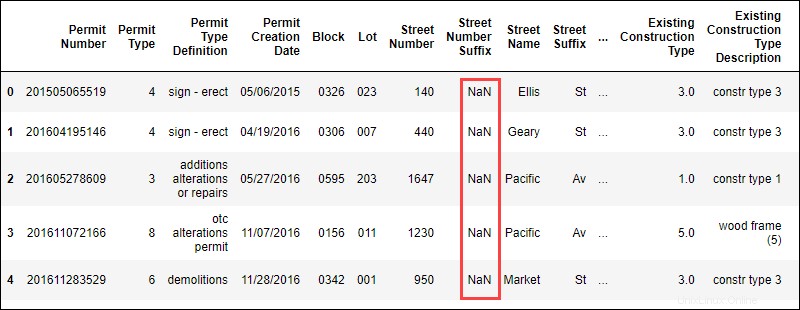
La presencia de NaN valores indica que faltan datos en este conjunto de datos.
Buscar valores faltantes
Encuentre cuántos valores faltantes hay por columna ejecutando:
data.isnull().sum()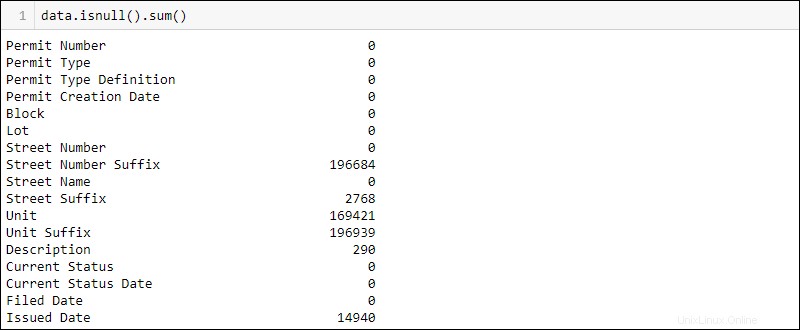
Los números proporcionan más significado cuando se muestran como porcentajes. Para mostrar las sumas como un porcentaje, divida el número por la longitud total del conjunto de datos:
data.isnull().sum()/len(data)
Para mostrar primero las columnas con el mayor porcentaje de datos faltantes, agregue .sort_values(ascending=False) a la línea de código anterior:
data.isnull().sum().sort_values(ascending = False)/len(data)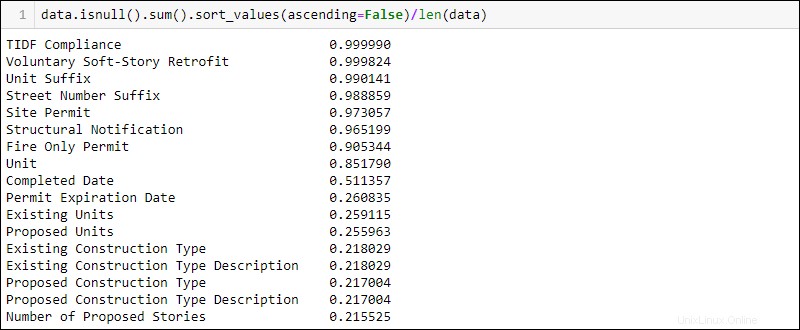
Antes de eliminar o alterar cualquier valor, verifique la documentación por cualquier razón por la que falten datos. Por ejemplo, en la columna Cumplimiento de TIDF faltan casi todos los datos. Sin embargo, la documentación establece que este es un nuevo requisito legal, por lo que tiene sentido que falten la mayoría de los valores.
Marcar valores faltantes
Muestre los datos estadísticos generales para un conjunto de datos ejecutando:
data.describe()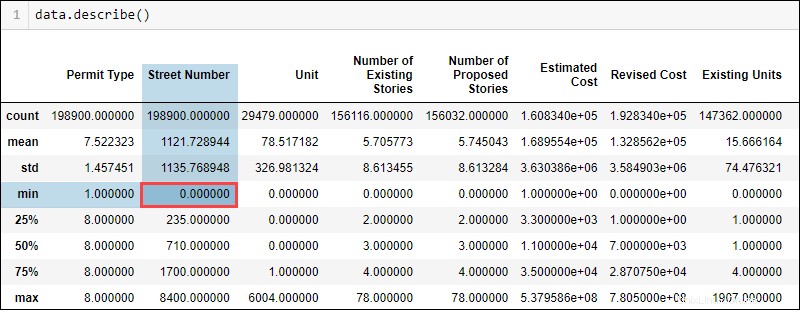
Según el tipo de datos y el conocimiento del dominio, algunos valores no encajan lógicamente. Por ejemplo, un número de calle no puede ser cero. Sin embargo, el valor mínimo muestra cero, lo que indica valores probables que faltan en la columna del número de calle.
Para ver cuántos Número de calle los valores son 0, ejecute:
(data['Street Number'] == 0).sum()Usando la biblioteca NumPy, intercambie el valor por NaN para indicar la información que falta:
import numpy as np
data['Street Number'] = data['Street Number'].replace(0, np.nan)La comprobación de los datos estadísticos actualizados ahora indica que el número de calle mínimo es 1.
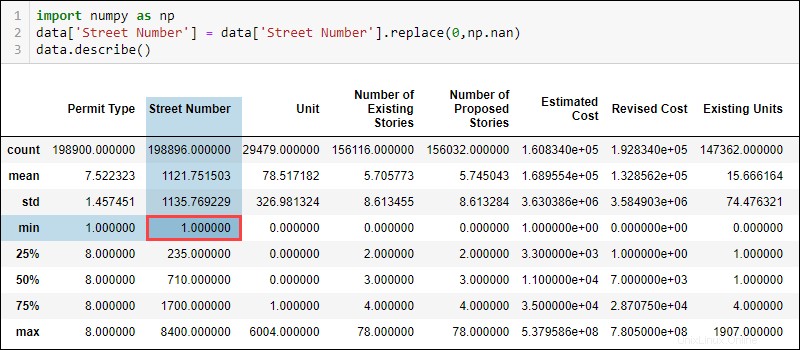
Del mismo modo, la suma de los valores de NaN ahora muestra que faltan datos en la columna del número de calle.
También cambian otros valores de la columna Número de calle, como el recuento y la media. La diferencia no es enorme debido a que solo unos pocos valores son 0. Sin embargo, con cantidades más significativas de datos mal etiquetados, las diferencias en las métricas también son más notables.
Eliminar valores faltantes
La forma más fácil de manejar los valores faltantes en Python es deshacerse de las filas o columnas donde falta información.
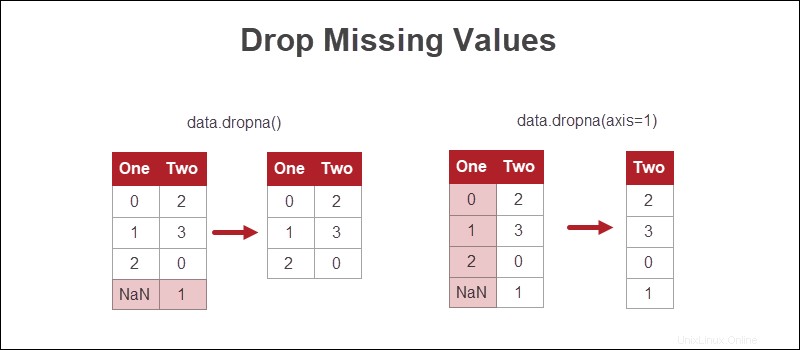
Aunque este enfoque es el más rápido, perder datos no es la opción más viable. Si es posible, son preferibles otros métodos.
Soltar filas con valores faltantes
Para eliminar filas con valores faltantes, use el dropna función:
data.dropna()Cuando se aplicó al conjunto de datos de ejemplo, la función eliminó todas las filas de datos porque cada fila de datos contiene al menos una Valor NaN.
Soltar columnas con valores faltantes
Para eliminar columnas con valores faltantes, utilice dropna función y proporcionar el eje:
data.dropna(axis = 1)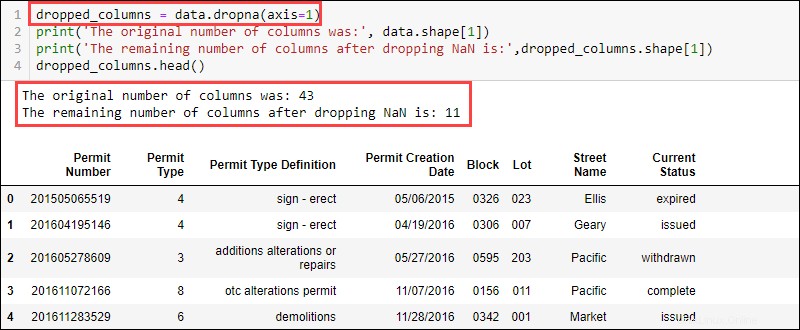
El conjunto de datos ahora contiene 11 columnas en comparación con las 43 inicialmente disponibles.
Imputación de valores perdidos
La imputación es un método para llenar valores faltantes con números usando una estrategia específica. Algunas opciones a considerar para la imputación son:
- Un valor de media, mediana o moda de esa columna.
- Un valor distinto, como 0 o -1.
- Un valor seleccionado al azar del conjunto existente.
- Valores estimados utilizando un modelo predictivo.
El módulo Pandas DataFrame proporciona un método para completar los valores de NaN utilizando varias estrategias. Por ejemplo, para reemplazar todos los valores de NaN con 0:
data.fillna(0)
El fillna La función proporciona diferentes métodos para reemplazar los valores que faltan. La reposición es un método común que completa la información que falta con el valor que viene después:
data.fillna(method = 'bfill')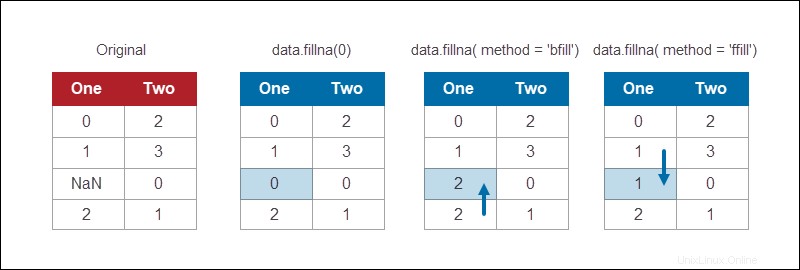
Si falta el último valor, complete todos los NaN restantes con el valor deseado. Por ejemplo, para rellenar todos los valores posibles y rellenar el resto con 0, utilice:
data.fillna(method = 'bfill', axis = 0).fillna(0)Del mismo modo, use rellenar para llenar los valores hacia adelante. Tanto el método de relleno hacia adelante como el de relleno hacia atrás funcionan cuando los datos tienen un orden lógico.
Algoritmos que admiten valores perdidos
Hay algoritmos de aprendizaje automático que son robustos con datos faltantes. Algunos ejemplos incluyen:
- kNN (k-vecino más cercano)
- Bayes ingenuo
Otros algoritmos, como los árboles de clasificación o regresión, utilizan la información no disponible como un identificador único.