Cuando usa un procesador de texto, formatear el texto para que las líneas quepan en el espacio disponible en el dispositivo de destino no debería ser un problema. Pero cuando se trabaja en la terminal, las cosas no son tan fáciles.
Por supuesto, siempre puede dividir las líneas a mano con su editor de texto favorito, pero esto rara vez es deseable e incluso está fuera de discusión para el procesamiento automatizado.
Con suerte, el POSIX fold utilidad y GNU/BSD fmt El comando puede ayudarlo a redistribuir un texto para que las líneas no excedan una longitud determinada.
¿Qué es una línea en Unix, otra vez?
Antes de entrar en los detalles del fold y fmt comandos, definamos primero de qué estamos hablando. En un archivo de texto, una línea se compone de una cantidad arbitraria de caracteres, seguida de la secuencia de control especial de nueva línea (a veces llamada EOL, por fin de línea )
En los sistemas similares a Unix, la secuencia de control de fin de línea se compone del (único) carácter avance de línea , a veces abreviado LF o escrito \n siguiendo una convención heredada del lenguaje C. A nivel binario, el carácter de avance de línea se representa como un byte que contiene el 0a valor hexadecimal.
Puede verificarlo fácilmente usando el hexdump utilidad que usaremos mucho en este artículo. Así que esa puede ser una buena ocasión para familiarizarse con esa herramienta. Puede, por ejemplo, examinar los volcados hexadecimales a continuación para averiguar cuántos caracteres de nueva línea ha enviado cada comando de eco. Una vez que crea que tiene la solución, vuelva a intentar esos comandos sin el | hexdump -C parte para ver si lo has adivinado correctamente.
sh$ echo hello | hexdump -C
00000000 68 65 6c 6c 6f 0a |hello.|
00000006
sh$ echo -n hello | hexdump -C
00000000 68 65 6c 6c 6f |hello|
00000005
sh$ echo -e 'hello\n' | hexdump -C
00000000 68 65 6c 6c 6f 0a 0a |hello..|
00000007
Vale la pena mencionar en este punto que los diferentes sistemas operativos pueden seguir diferentes reglas con respecto a la secuencia de nueva línea. Como hemos visto anteriormente, los sistemas operativos similares a Unix utilizan el avance de línea carácter, pero Windows, como la mayoría de los protocolos de Internet, utiliza dos caracteres:el retorno de carro+avance de línea par (CRLF, o 0d 0a , o \r\n ). En Mac OS "clásico" (hasta MacOS 9.2 incluido a principios de la década de 2000), las computadoras Apple usaban CR solo como el carácter de nueva línea. Otras computadoras heredadas también usaban el par LFCR, o incluso secuencias de bytes completamente diferentes en el caso de sistemas incompatibles con ASCII más antiguos. Afortunadamente, estos últimos son reliquias del pasado, ¡y dudo que vea alguna computadora EBCDIC en uso hoy!
Hablando de historia, si tiene curiosidad, el uso de los caracteres de control de "retorno de carro" y "salto de línea" se remonta al código Baudot utilizado en la era de los teletipos. Es posible que haya visto el teletipo representado en películas antiguas como una interfaz para una computadora del tamaño de una habitación. Pero incluso antes de eso, los teletipos se usaban "independientes" para la comunicación punto a punto o multipunto. En ese momento, una terminal típica parecía una máquina de escribir pesada con un teclado mecánico, papel y un carro móvil que sostenía el cabezal de impresión. Para comenzar una nueva línea, el carro debe regresar al extremo izquierdo y el papel debe moverse hacia arriba girando la platina (a veces llamada "cilindro"). Esos dos movimientos estaban controlados por dos sistemas electromecánicos independientes, los caracteres de control de avance de línea y retorno de carro estaban conectados directamente a esas dos partes del dispositivo. Dado que mover el carro requiere más tiempo que rotar la platina, era lógico iniciar primero el retorno del carro. Separar las dos funciones también tuvo un par de efectos secundarios interesantes, como permitir la sobreimpresión (enviando solo el CR) o la transmisión eficiente de "doble interlínea" (un CR + dos LF).
La definición al comienzo de esta sección describe principalmente lo que un lógico la línea es. La mayoría de las veces, sin embargo, esa línea lógica "arbitrariamente larga" tiene que enviarse en un físico dispositivo como una pantalla o una impresora, donde el espacio disponible es limitado. Mostrar líneas lógicas cortas en un dispositivo que tiene líneas físicas más grandes no es un problema. Simplemente hay un espacio sin usar a la derecha del texto. Pero, ¿qué sucede si intenta mostrar una línea de texto más grande que el espacio disponible en el dispositivo? En realidad, hay dos soluciones, cada una con su cuota de inconvenientes:
- Primero, el dispositivo puede truncar las líneas en su tamaño físico, ocultando así parte del contenido al usuario. Algunas impresoras hacen eso, especialmente las impresoras tontas (y sí, todavía hay impresoras de matriz de puntos básicas en uso hoy en día, ¡especialmente en entornos hostiles o sucios!)
- La segunda opción para mostrar líneas lógicas largas es dividirlas en varias líneas físicas. Esto se llama ajuste de línea. porque las líneas parecen envolver el espacio disponible, un efecto particularmente visible si puede cambiar el tamaño de la pantalla como cuando trabaja con un emulador de terminal.
Esos comportamientos automáticos son bastante útiles, pero todavía hay ocasiones en las que desea romper líneas largas en una posición determinada, independientemente del tamaño físico del dispositivo. Por ejemplo, puede ser útil porque desea que los saltos de línea se produzcan en la misma posición tanto en la pantalla como en la impresora. O porque desea que su texto se use en una aplicación que no realiza ajuste de línea (por ejemplo, si incrusta texto mediante programación en un archivo SVG). Finalmente, lo crea o no, todavía hay muchos protocolos de comunicación que imponen un ancho de línea máximo en las transmisiones, incluidos los populares como IRC y SMTP (si alguna vez vio el error 550 Longitud máxima de línea excedida, sabe a lo que me refiero). hablando sobre). Entonces, hay muchas ocasiones en las que necesita dividir líneas largas en trozos más pequeños. Este es el trabajo del POSIX fold comando.
El comando doblar
Cuando se usa sin ninguna opción, el fold El comando agrega secuencias de control de nueva línea adicionales para garantizar que ninguna línea exceda el límite de 80 caracteres. Para que quede claro, una línea contendrá como máximo 80 caracteres más la secuencia de nueva línea.
Si ha descargado el material de apoyo para ese artículo, puede intentarlo usted mismo:
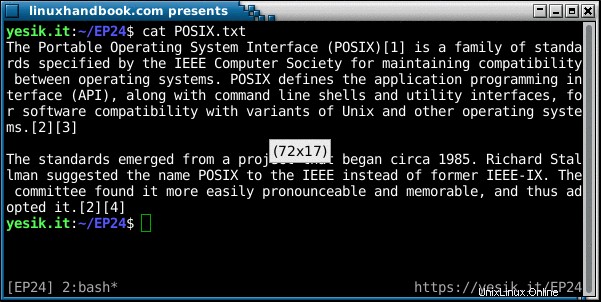
sh$ fold POSIX.txt | head -5
The Portable Operating System Interface (POSIX)[1] is a family of standards spec
ified by the IEEE Computer Society for maintaining compatibility between operati
ng systems. POSIX defines the application programming interface (API), along wit
h command line shells and utility interfaces, for software compatibility with va
riants of Unix and other operating systems.[2][3]
# Using AWK to prefix each line by its length:
sh$ fold POSIX.txt | awk '{ printf("%3d %s\n", length($0), $0) }'
80 The Portable Operating System Interface (POSIX)[1] is a family of standards spec
80 ified by the IEEE Computer Society for maintaining compatibility between operati
80 ng systems. POSIX defines the application programming interface (API), along wit
80 h command line shells and utility interfaces, for software compatibility with va
49 riants of Unix and other operating systems.[2][3]
0
80 The standards emerged from a project that began circa 1985. Richard Stallman sug
80 gested the name POSIX to the IEEE instead of former IEEE-IX. The committee found
71 it more easily pronounceable and memorable, and thus adopted it.[2][4]
Puede cambiar la longitud máxima de la línea de salida usando -w opción. Más interesante probablemente es el uso de -s opción para garantizar que las líneas se rompan en un límite de palabra. Comparemos el resultado sin y con -s opción cuando se aplica al segundo párrafo de nuestro texto de muestra:
# Without `-s` option: fold will break lines at the specified position
# Broken lines have exactly the required width
sh$ awk -vRS='' 'NR==2' POSIX.txt |
fold -w 30 | awk '{ printf("%3d %s\n", length($0), $0) }'
30 The standards emerged from a p
30 roject that began circa 1985.
30 Richard Stallman suggested the
30 name POSIX to the IEEE instea
30 d of former IEEE-IX. The commi
30 ttee found it more easily pron
30 ounceable and memorable, and t
21 hus adopted it.[2][4]
# With `-s` option: fold will break lines at the last space before the specified position
# Broken lines are shorter or equal to the required width
awk -vRS='' 'NR==2' POSIX.txt |
fold -s -w 30 | awk '{ printf("%3d %s\n", length($0), $0) }'
29 The standards emerged from a
25 project that began circa
23 1985. Richard Stallman
28 suggested the name POSIX to
27 the IEEE instead of former
29 IEEE-IX. The committee found
29 it more easily pronounceable
24 and memorable, and thus
17 adopted it.[2][4]
Obviamente, si su texto contiene palabras más largas que la longitud máxima de la línea, el comando de plegado no podrá respetar la -s bandera. En ese caso, el fold La utilidad dividirá las palabras de gran tamaño en la posición máxima, siempre asegurándose de que ninguna línea exceda el ancho máximo permitido.
sh$ echo "It's Supercalifragilisticexpialidocious!" | fold -sw 10
It's
Supercalif
ragilistic
expialidoc
ious!Caracteres multibyte
Como la mayoría de las utilidades principales, si no todas, el fold El comando se diseñó en un momento en que un carácter equivalía a un byte. Sin embargo, este ya no es el caso en la informática moderna, especialmente con la adopción generalizada de UTF-8. Algo que conduce a problemas desafortunados:
# Just in case, check first the relevant locale
# settings are properly defined
debian-9.4$ locale | grep LC_CTYPE
LC_CTYPE="en_US.utf8"
# Everything is OK, unfortunately...
debian-9.4$ echo élève | fold -w2
é
l�
�v
e
La palabra “élève” (la palabra francesa para “estudiante”) contiene dos letras acentuadas:é (LETRA E MINÚSCULA LATINA CON AGUDO) y è (LETRA E MINÚSCULA LATINA CON TUMBA). Usando el conjunto de caracteres UTF-8, esas letras se codifican usando dos bytes cada una (respectivamente, c3 a9 y c3 a8 ), en lugar de un solo byte como es el caso de las letras latinas sin acento. Puede verificar eso examinando los bytes sin procesar usando el hexdump utilidad. Debería poder identificar las secuencias de bytes correspondientes al é y è caracteres. Por cierto, también puede ver en ese volcado a nuestro viejo amigo el carácter de avance de línea cuyo código hexadecimal se mencionó anteriormente:
debian-9.4$ echo élève | hexdump -C
00000000 c3 a9 6c c3 a8 76 65 0a |..l..ve.|
00000008Examinemos ahora la salida producida por el comando fold:
debian-9.4$ echo élève | fold -w2
é
l�
�v
e
debian-9.4$ echo élève | fold -w 2 | hexdump -C
00000000 c3 a9 0a 6c c3 0a a8 76 0a 65 0a |...l...v.e.|
0000000b
Obviamente, el resultado producido por el fold El comando es un poco más largo que la cadena original de caracteres debido a las nuevas líneas adicionales:respectivamente, 11 bytes de largo y 8 bytes de largo, incluidas las nuevas líneas. Hablando de eso, en la salida del fold comando, es posible que haya visto el salto de línea (0a ) carácter que aparece cada dos bytes. Y este es exactamente el problema:el comando fold rompió líneas en byte posiciones, no en personaje posiciones. ¡Incluso si esa ruptura ocurre en medio de un carácter de varios bytes! No es necesario mencionar que la salida resultante ya no es un flujo de bytes UTF-8 válido, de ahí el uso del carácter de reemplazo Unicode (� ) por mi terminal como marcador de posición para las secuencias de bytes no válidas.
Me gusta para el cut comando sobre el que escribí hace unas semanas, esta es una limitación en la implementación GNU del fold utilidad y esto está claramente en oposición con las especificaciones POSIX que establecen explícitamente que “Una línea no debe romperse en medio de un carácter”.
Entonces aparece el GNU fold La implementación solo trata correctamente con codificaciones de caracteres de un byte de longitud fija (US-ASCII, Latin1, etc.). Como solución alternativa, si existe un conjunto de caracteres adecuado, puede transcodificar el texto a una codificación de caracteres de un byte antes de procesarlo y volver a transcodificarlo a UTF-8 después. Sin embargo, esto es engorroso, por decir lo menos:
debian-9.4$ echo élève |
iconv -t latin1 | fold -w 2 |
iconv -f latin1 | hexdump -C
00000000 c3 a9 6c 0a c3 a8 76 0a 65 0a |..l...v.e.|
0000000a
debian-9.4$ echo élève |
iconv -t latin1 | fold -w 2 |
iconv -f latin1
él
èv
e
Siendo todo eso bastante decepcionante, decidí comprobar el comportamiento de otras implementaciones. Como suele ser el caso, la implementación de OpenBSD del fold La utilidad es mucho mejor en ese sentido, ya que es compatible con POSIX y respetará el LC_CTYPE configuración local para manejar correctamente los caracteres de varios bytes:
openbsd-6.3$ locale | grep LC_CTYPE
LC_CTYPE=en_US.UTF-8
openbsd-6.3$ echo élève | fold -w 2 C
él
èv
e
openbsd-6.3$ echo élève | fold -w 2 | hexdump -C
00000000 c3 a9 6c 0a c3 a8 76 0a 65 0a |..l...v.e.|
0000000aComo puede ver, la implementación de OpenBSD cortó correctamente las líneas en carácter posiciones, independientemente del número de bytes necesarios para codificarlas. En la gran mayoría de los casos de uso, esto es lo que desea. Sin embargo, si necesita el comportamiento heredado (es decir, estilo GNU) considerando un byte como un carácter, puede cambiar temporalmente la configuración regional actual a la llamada configuración regional POSIX (identificada por la constante "POSIX" o, por razones históricas, "C ”):
openbsd-6.3$ echo élève | LC_ALL=C fold -w 2
é
l�
�v
e
openbsd-6.3$ echo élève | LC_ALL=C fold -w 2 | hexdump -C
00000000 c3 a9 0a 6c c3 0a a8 76 0a 65 0a |...l...v.e.|
0000000b
Finalmente, POSIX especifica el -b flag, que instruye al fold utilidad para medir la longitud de línea en bytes , pero eso, sin embargo, garantiza caracteres de varios bytes (de acuerdo con el actual LC_CTYPE configuración regional) no ser roto.
Como ejercicio, le recomiendo encarecidamente que se tome el tiempo necesario para encontrar las diferencias a nivel de byte entre el resultado obtenido al cambiar la configuración regional actual a "C" (arriba) y el resultado obtenido al usar -b bandera en su lugar (abajo). Puede ser sutil. Pero hay es una diferencia:
openbsd-6.3$ echo élève | fold -b -w 2 | hexdump -C
00000000 c3 a9 0a 6c 0a c3 a8 0a 76 65 0a |...l....ve.|
0000000bEntonces, ¿encontraste la diferencia?
Bueno, al cambiar la configuración regional a "C", el fold La utilidad no se ocupó de las secuencias de varios bytes, ya que, por definición, cuando la configuración regional es "C", las herramientas deben asumir que un carácter es un byte . Por lo tanto, se puede agregar una nueva línea en cualquier lugar, incluso en medio de una secuencia de bytes que sería han sido considerados como un carácter de varios bytes en otra codificación de caracteres. Esto es exactamente lo que sucedió cuando la herramienta produjo el c3 0a a8 secuencia de bytes:Los dos bytes c3 a8 se entienden como un carácter cuando LC_CTYPE define la codificación de caracteres como UTF-8. Pero la misma secuencia de bytes se ve como dos caracteres en la configuración regional "C":
# Bytes are bytes. They don't change so
# the byte count is the same whatever is the locale
openbsd-6.3$ printf "%d bytes\n" $(echo -n é | LC_ALL=en_US.UTF-8 wc -c)
2 bytes
openbsd-6.3$ printf "%d bytes\n" $(echo -n é | LC_ALL=C wc -c)
2 bytes
# The interpretation of the bytes may change depending on the encoding
# so the corresponding character count will change
openbsd-6.3$ printf "%d chars\n" $(echo -n é | LC_ALL=en_US.UTF-8 wc -m)
1 chars
openbsd-6.3$ printf "%d chars\n" $(echo -n é | LC_ALL=C wc -m)
2 chars
Por otro lado, con -b opción, la herramienta aún debe tener en cuenta varios bytes. Esa opción solo cambia en la forma en que cuenta las posiciones , en bytes esta vez, en lugar de en caracteres como es por defecto. En ese caso, dado que las secuencias de varios bytes no se dividen, la salida resultante sigue siendo un flujo de caracteres válido (de acuerdo con el LC_CTYPE actual configuración regional):
openbsd-6.3$ echo élève | fold -b -w 2
é
l
è
ve
Lo ha visto, no más ocurrencias ahora del carácter de reemplazo Unicode (� ), y no perdimos ningún carácter significativo en el proceso, a expensas de terminar esta vez con líneas que contienen una cantidad variable de caracteres y un número variable de bytes. Finalmente, todo lo que la herramienta asegura es que no hay más bytes por línea que los solicitados con -w opción. Algo que podemos verificar usando el wc herramienta:
openbsd-6.3$ echo élève | fold -b -w 2 | while read line; do
> printf "%3d bytes %3d chars %s\n" \
> $(echo -n $line | wc -c) \
> $(echo -n $line | wc -m) \
> $line
> done
2 bytes 1 chars é
1 bytes 1 chars l
2 bytes 1 chars è
2 bytes 2 chars ve
Una vez más, tómese el tiempo necesario para estudiar el ejemplo anterior. Hace uso del printf y wc comandos que no expliqué en detalle anteriormente. Entonces, si las cosas no están lo suficientemente claras, ¡no dudes en usar la sección de comentarios para pedir algunas explicaciones!
Por curiosidad, revisé el -b bandera en mi caja de Debian usando GNU fold implementación:
debian-9.4$ echo élève | fold -w 2 | hexdump -C
00000000 c3 a9 0a 6c c3 0a a8 76 0a 65 0a |...l...v.e.|
0000000b
debian-9.4$ echo élève | fold -b -w 2 | hexdump -C
00000000 c3 a9 0a 6c c3 0a a8 76 0a 65 0a |...l...v.e.|
0000000b
No pierda su tiempo tratando de encontrar una diferencia entre -b y no -b versiones de ese ejemplo:hemos visto que la implementación de GNU fold no es compatible con varios bytes, por lo que ambos resultados son idénticos. Si no está convencido de eso, tal vez podría usar diff -s comando para permitir que su computadora lo confirme. Si lo hace, utilice la sección de comentarios para compartir el comando que utilizó con los demás lectores.
De todos modos, ¿eso significa que -b opción inútil en la implementación GNU del fold ¿utilidad? Bueno, leyendo más detenidamente la documentación de GNU Coreutils para el fold comando, encontré el -b la opción solo trata con caracteres especiales como el tabulador o el retroceso que cuentan respectivamente para 1~8 (uno a ocho) o -1 (menos uno) posición en modo normal, pero siempre cuentan para 1 posición en el modo byte. ¿Confuso? Entonces, tal vez podríamos tomarnos un tiempo para explicar eso con más detalles.
Gestión de tabuladores y retrocesos
La mayoría de los archivos de texto con los que trabajará solo contienen caracteres imprimibles y secuencias de final de línea. Sin embargo, ocasionalmente, puede suceder que algunos caracteres de control se introduzcan en sus datos. El carácter de tabulación (\t ) es uno de ellos. Mucho más raramente, el retroceso (\b ) también se pueden encontrar. Todavía lo menciono aquí porque, como su nombre lo indica, es un carácter de control que hace que el cursor se mueva una posición hacia atrás (hacia la izquierda), mientras que la mayoría de los otros personajes lo hacen yendo hacia adelante (hacia la derecha).
sh$ echo -e 'tab:[\t] backspace:[\b]'
tab:[ ] backspace:]
Es posible que esto no sea visible en su navegador, por lo que le recomiendo encarecidamente que lo pruebe en su terminal. Pero los caracteres de tabulación (\t ) ocupa varias posiciones en la salida. ¿Y el retroceso? Parece haber algo extraño en la salida, ¿no es así? Así que ralenticemos un poco las cosas, dividiendo la cadena de texto en varias partes e insertando algo de sleep entre ellos:
# For that to work, type all the commands on the same line
# or using backslashes like here if you split them into
# several (physical) lines:
sh$ echo -ne 'tab:[\t] backspace:['; \
sleep 1; echo -ne '\b'; \
sleep 1; echo -n ']'; \
sleep 1; echo ''¿DE ACUERDO? ¿Lo viste esta vez? Descompongamos la secuencia de los eventos:
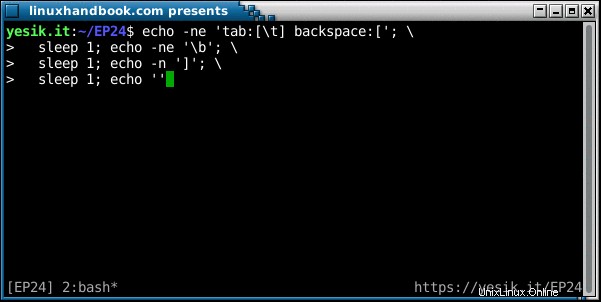
- La primera cadena de caracteres se muestra "normalmente" hasta el segundo corchete de apertura. Por el
-nbandera, elechoel comando no envía un carácter de nueva línea, para que el cursor permanezca en la misma línea. - Primer sueño.
- Se emite un retroceso, lo que hace que el cursor retroceda una posición. Todavía no hay nueva línea, por lo que el cursor permanece en la misma línea.
- Segundo sueño.
- Se muestra el corchete de cierre, sobrescribiendo el de apertura.
- Tercer sueño.
- En ausencia de
-nopción, el últimoechoEl comando finalmente envía el carácter de nueva línea y el cursor se mueve a la siguiente línea, donde se mostrará el indicador de shell.
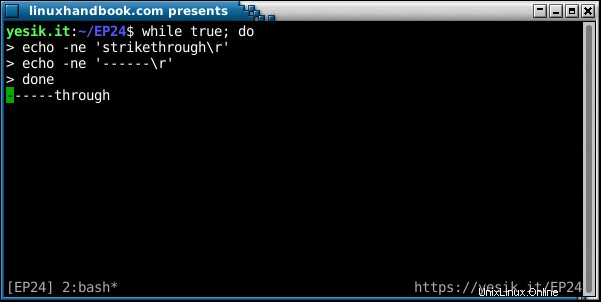
Por supuesto, se puede obtener un efecto genial similar usando un retorno de carro, si lo recuerdas:
sh$ echo -n 'hello'; sleep 1; echo -e '\rgood bye'
good bye
Estoy bastante seguro de que ya has visto alguna utilidad de línea de comandos como curl , wget o ffmpeg mostrando una barra de progreso. Hacen su magia usando una combinación de \b y/o \r .
Por interesante que la discusión pueda ser en sí misma, el punto aquí era entender que manejar esos caracteres puede ser un desafío para el fold utilidad. Con suerte, el estándar POSIX define las reglas:
Todos esos tratamientos especiales están deshabilitados cuando se usa -b opción. En ese caso, los caracteres de control sobre todo cuentan (correctamente) por un byte y así aumentar el contador de posición en uno y solo uno, como cualquier otro personaje.
Para una mejor comprensión, te dejo investigar por ti mismo los siguientes dos ejemplos (tal vez usando el hexdump utilidad). Ahora debería poder encontrar por qué "hola" se ha convertido en "infierno" y dónde está exactamente la "i" en la salida (como está allí, ¡incluso si no puede verla!) Como siempre, si necesita ayuda , o simplemente si desea compartir sus hallazgos, la sección de comentarios es suya.
# Why "hello" has become "hell"? where is the "i"?
sh$ echo -e 'hello\rgood bi\bye' | fold -w4
hell
good
bye
# Why "hello" has become "hell"? where is the "i"?
# Why the second line seems to be made of only two chars instead of 4?
sh$ echo -e 'hello\rgood bi\bye' | fold -bw4
hell
go
od b
yeOtras limitaciones
El fold El comando que hemos estudiado hasta ahora fue diseñado para dividir líneas lógicas largas en líneas físicas más pequeñas, en particular con fines de formato.
Eso significa que asume que cada línea de entrada es independiente y se puede dividir independientemente de las otras líneas. Esto no es siempre el caso, sin embargo. Por ejemplo, consideremos ese correo muy importante que recibí:
sh$ cat MAIL.txt
Dear friends,
Have a nice day!
We are manufactuer for event chairs and tables, more than 10 years experience.
We supply all kinds of wooden, resin and metal event chairs, include chiavari
chairs, cross back chairs, folding chairs, napoleon chairs, phoenix chairs, etc.
Our chairs and tables are of high quality and competitively priced.
If you need our products, welcome to contact me;we are happy to make you special
offer.
Best Regards
Doris
sh$ awk '{ length>maxlen && (maxlen=length) } END { print maxlen }' MAIL.txt
81
Obviamente, las líneas ya estaban divididas en un ancho fijo. El awk El comando me dijo que el ancho de línea máximo aquí era... 81 caracteres, excluyendo la nueva secuencia de línea. Sí, eso fue lo suficientemente extraño como para verificarlo dos veces:de hecho, la línea más larga tiene 80 caracteres imprimibles más un espacio adicional en la posición 81 y solo después de eso está el carácter de salto de línea. ¡Probablemente la gente de TI que trabaja en nombre de este "fabricante" de sillas podría beneficiarse de leer este artículo!
De todos modos, suponiendo que me gustaría cambiar el formato de ese correo electrónico, tendré problemas con el fold comando debido a los saltos de línea existentes. Te dejo comprobar los dos comandos siguientes por ti mismo si quieres, pero ninguno de ellos funcionará como se esperaba:
sh$ fold -sw 100 MAIL.txt
sh$ fold -sw 60 MAIL.txtEl primero simplemente no hará nada ya que todas las líneas ya tienen menos de 100 caracteres. Con respecto al segundo comando, romperá líneas en la posición 60 pero mantendrá los caracteres de nueva línea ya existentes para que el resultado sea irregular. Será particularmente visible en el tercer párrafo:
sh$ awk -v RS='' 'NR==3' MAIL.txt |
fold -sw 60 |
awk '{ length>maxlen && (maxlen=length); print length, $0 }'
53 We supply all kinds of wooden, resin and metal event
25 chairs, include chiavari
60 chairs, cross back chairs, folding chairs, napoleon chairs,
20 phoenix chairs, etc.La primera línea del tercer párrafo se partió en la posición 53, lo que es consistente con nuestro ancho máximo de 60 caracteres por línea. Sin embargo, la segunda línea se rompió en la posición 25 porque ese carácter de nueva línea ya presentes en el archivo de entrada. En otras palabras, para cambiar correctamente el tamaño de los párrafos, primero debemos volver a unir las líneas antes de dividirlas en la nueva posición de destino.
Puedes usar sed o awk para volver a unir las líneas. Y, de hecho, como lo mencioné en el video introductorio, sería un buen desafío para ti. Así que no dudes en publicar tu solución en la sección de comentarios.
En cuanto a mí, seguiré un camino más fácil mirando el fmt dominio. Si bien no es un comando estándar POSIX, está disponible tanto en el mundo GNU como en BSD. Por lo tanto, hay buenas posibilidades de que se pueda utilizar en su sistema. Desafortunadamente, la falta de estandarización tendrá algunas implicaciones negativas, como veremos más adelante. Pero por ahora, concentrémonos en las partes buenas.
El comando fmt
El fmt el comando está más evolucionado que el fold comando y tiene más opciones de formato. La parte más interesante es que puede identificar párrafos en el archivo de entrada en función de las líneas vacías. Eso significa que todas las líneas hasta la siguiente línea vacía (o el final del archivo) se unirán primero para formar lo que antes llamé una "línea lógica" del texto. Solo después de eso, el fmt el comando dividirá el texto en la posición solicitada.
Veamos ahora qué cambiará cuando se aplique al segundo párrafo de mi correo de ejemplo:
sh$ awk -v RS='' 'NR==3' MAIL.txt |
fmt -w 60 |
awk '{ length>maxlen && (maxlen=length); print length, $0 }'
60 We supply all kinds of wooden, resin and metal event chairs,
59 include chiavari chairs, cross back chairs, folding chairs,
37 napoleon chairs, phoenix chairs, etc.
Como anécdota, el fmt comando aceptado para empaquetar una palabra más en la primera línea. Pero lo que es más interesante, la segunda línea ahora está llena, lo que significa que el carácter de nueva línea ya presente en el archivo de entrada después de que se haya descartado la palabra "chiavari" (¿qué es esto?). Por supuesto, las cosas no son perfectas y el fmt El algoritmo de detección de párrafos a veces genera falsos positivos, como en los saludos al final del correo (línea 14 de la salida):
sh$ fmt -w 60 MAIL.txt | cat -n
1 Dear friends,
2
3 Have a nice day! We are manufactuer for event chairs and
4 tables, more than 10 years experience.
5
6 We supply all kinds of wooden, resin and metal event chairs,
7 include chiavari chairs, cross back chairs, folding chairs,
8 napoleon chairs, phoenix chairs, etc.
9
10 Our chairs and tables are of high quality and competitively
11 priced. If you need our products, welcome to contact me;we
12 are happy to make you special offer.
13
14 Best Regards Doris
Dije antes el fmt El comando era una herramienta de formato de texto más evolucionada que fold utilidad. De hecho, es. Puede que no sea obvio a primera vista, pero si observa detenidamente las líneas 10-11, puede notar que usó dos espacios después del punto, haciendo cumplir una convención muy discutida de usar dos espacios al final de una oración. No entraré en ese debate para saber si debe o no usar dos espacios entre oraciones, pero no tiene otra opción real aquí:que yo sepa, ninguna de las implementaciones comunes de fmt El comando ofrece una bandera para deshabilitar el doble espacio después de una oración. A menos que tal opción exista en alguna parte y me la perdí. Si este es el caso, estaré feliz de que me lo hagas saber usando la sección de comentarios:como escritor francés, nunca usé el "doble espacio" después de una oración...
Más opciones de fmt
El fmt La utilidad está diseñada con algunas capacidades de formateo más que el comando fold. Sin embargo, al no estar definido POSIX, existen importantes incompatibilidades entre las opciones GNU y BSD.
Por ejemplo, el -c La opción se usa en el mundo BSD para centrar el texto mientras que en GNU Coreutils fmt habilita el modo de margen de corona, “preservando la sangría de las dos primeras líneas dentro de un párrafo, y alinea el margen izquierdo de cada línea subsiguiente con el de la segunda línea. “
Te dejo experimentar por ti mismo con GNU fmt -c si tu quieres. Personalmente, encuentro que la función de centrado de texto BSD es más interesante de estudiar debido a alguna rareza:de hecho, en OpenBSD, fmt -c centrará el texto de acuerdo con el ancho objetivo, ¡pero sin redistribuirlo! So the following command will not work as you might have expected:
openbsd-6.3$ fmt -c -w 60 MAIL.txt
Dear friends,
Have a nice day!
We are manufactuer for event chairs and tables, more than 10 years experience.
We supply all kinds of wooden, resin and metal event chairs, include chiavari
chairs, cross back chairs, folding chairs, napoleon chairs, phoenix chairs, etc.
Our chairs and tables are of high quality and competitively priced.
If you need our products, welcome to contact me;we are happy to make you special
offer.
Best Regards
Doris
If you really want to reflow the text for a maximum width of 60 characters and center the result, you will have to use two instances of the fmt command:
openbsd-6.3$ fmt -w 60 MAIL.txt | fmt -c -w60
Dear friends,
Have a nice day! We are manufactuer for event chairs and
tables, more than 10 years experience.
We supply all kinds of wooden, resin and metal event chairs,
include chiavari chairs, cross back chairs, folding chairs,
napoleon chairs, phoenix chairs, etc.
Our chairs and tables are of high quality and competitively
priced. If you need our products, welcome to contact me;we
are happy to make you special offer.
Best Regards Doris
I will not make here an exhaustive list of the differences between the GNU and BSD fmt implementations … essentially because all the options are different! Except of course the -w opción. Speaking of that, I forgot to mention -N where N is an integer is a shortcut for -wN . Moreover you can use that shortcut both with the fold and fmt commands:so, if you were perseverent enough to read his article until this point, as a reward you may now amaze your friends by saving one (!) entire keystroke the next time you will use one of those utilities:
debian-9.4$ fmt -50 POSIX.txt | head -5
The Portable Operating System Interface
(POSIX)[1] is a family of standards specified
by the IEEE Computer Society for maintaining
compatibility between operating systems. POSIX
defines the application programming interface
openbsd-6.3$ fmt -50 POSIX.txt | head -5
The Portable Operating System Interface (POSIX)[1]
is a family of standards specified by the IEEE
Computer Society for maintaining compatibility
between operating systems. POSIX defines the
application programming interface (API), along
debian-9.4$ fold -sw50 POSIX.txt | head -5
The Portable Operating System Interface
(POSIX)[1] is a family of standards specified by
the IEEE Computer Society for maintaining
compatibility between operating systems. POSIX
defines the application programming interface
openbsd-6.3$ fold -sw50 POSIX.txt | head -5
The Portable Operating System Interface
(POSIX)[1] is a family of standards specified by
the IEEE Computer Society for maintaining
compatibility between operating systems. POSIX
defines the application programming interface
As the final word, you may also notice in that last example the GNU and BSD versions of the fmt utility are using a different formatting algorithm, producing a different result. On the other hand, the simpler fold algorithm produces consistent results between the implementations. All that to say if portability is a premium, you need to stick with the fold command, eventually completed by some other POSIX utilities. But if you need more fancy features and can afford to break compatibility, take a look at the manual for the fmt command specific to your own system. And let us know if you discovered some fun or creative usage for those vendor-specific options!