Introducción
Apache Hive es una herramienta de almacenamiento de datos que se utiliza para realizar consultas y analizar datos estructurados en Apache Hadoop. Utiliza un lenguaje similar a SQL llamado HiveQL.
En este artículo, aprenda a crear una tabla en Hive y cargar datos. También le mostraremos comandos cruciales de HiveQL para mostrar datos.

Requisitos previos
- Un sistema que ejecuta Linux
- Una cuenta de usuario con sudo o raíz privilegios
- Acceso a una ventana de terminal/línea de comandos
- Trabajando Hadoop instalación
- Trabajando Hive instalación
Crear y cargar tabla en Hive
Una tabla en Hive es un conjunto de datos que usa un esquema para ordenar los datos por identificadores dados.
La sintaxis general para crear una tabla en Hive es:
CREATE [EXTERNAL] TABLE [IF NOT EXISTS] [db_name.]table_name
(col_name data_type [COMMENT 'col_comment'],, ...)
[COMMENT 'table_comment']
[ROW FORMAT row_format]
[FIELDS TERMINATED BY char]
[STORED AS file_format];
Siga los pasos a continuación para crear una tabla en Hive.
Paso 1:crear una base de datos
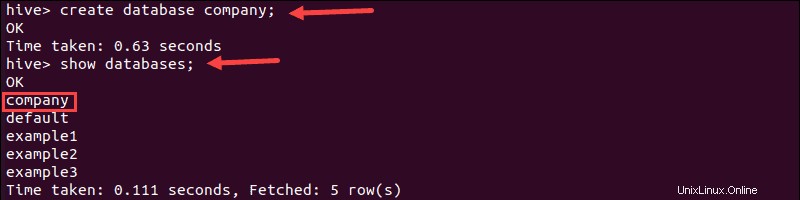
1. Cree una base de datos llamada "empresa" ejecutando create comando:
create database company;El terminal imprime un mensaje de confirmación y el tiempo necesario para realizar la acción.
2. A continuación, verifique que se haya creado la base de datos ejecutando show comando:
show databases;3. Busque la base de datos de la "empresa" en la lista:
4. Abra la base de datos de la "empresa" utilizando el siguiente comando:
use company;
Paso 2:Crear una tabla en Hive
La base de datos "empresa" no contiene ninguna tabla después de la creación inicial. Vamos a crear una tabla cuyos identificadores coincidan con el archivo .txt desde el que desea transferir datos.
1. Cree un archivo "employees.txt" en /hdoop directorio. El archivo contendrá datos sobre los empleados:

2. Organice los datos del archivo “employees.txt” en columnas. Los nombres de columna en nuestro ejemplo son:
- Identificación
- Nombre
- País
- Departamento
- Salario
3. Use nombres de columnas al crear una tabla. Cree la tabla ejecutando el siguiente comando:
create table employees (id int, name string, country string, department string, salary int)
4. Cree un esquema lógico que organice los datos del archivo .txt en las columnas correspondientes. En el archivo “employees.txt”, los datos están separados por un '-' . Para crear un tipo de esquema lógico:
row format delimited fields terminated by '-';El terminal imprime un mensaje de confirmación:

5. Verifique si la tabla se crea ejecutando show comando:
show tables;
Paso 3:cargar datos desde un archivo
Ha creado una tabla, pero está vacía porque los datos no se cargan desde el archivo "employees.txt" ubicado en /hdoop directorio.
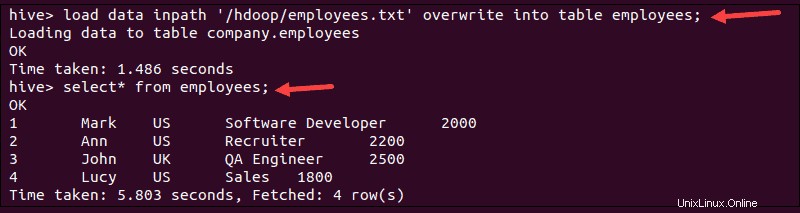
1. Cargue los datos ejecutando load comando:
load data inpath '/hdoop/employees.txt' overwrite into table employees;
2. Verifique si los datos están cargados ejecutando select comando:
select * from employees;El terminal imprime los datos importados del employees.txt archivo:
Mostrar datos de la colmena
Tiene varias opciones para mostrar los datos de la tabla. Al usar las siguientes opciones, puede manipular grandes cantidades de datos de manera más eficiente.
Columnas de visualización
Mostrar columnas de una tabla ejecutando desc comando:
desc employees;La salida muestra los nombres y propiedades de las columnas:

Mostrar datos seleccionados
Supongamos que desea mostrar los empleados y sus países de origen. Seleccione y muestre datos ejecutando select comando:
select name,country from employees;El resultado contiene la lista de empleados y sus países:
