Introducción
Los marcos de procesamiento de datos, como Apache Hadoop y Spark, han estado impulsando el desarrollo de Big Data. Su capacidad para recopilar grandes cantidades de datos de diferentes flujos de datos es increíble; sin embargo, necesitan un almacén de datos para analizar, administrar y consultar todos los datos.
¿Está interesado en aprender más sobre qué son los almacenes de datos y en qué consisten?
Este artículo explica la arquitectura del almacén de datos y la función de cada componente en el sistema.
¿Qué es un almacén de datos?
Un almacén de datos (DW o DWH) es un sistema complejo que almacena datos históricos y acumulativos utilizados para pronósticos, informes y análisis de datos. Implica recopilar, limpiar y transformar datos de diferentes flujos de datos y cargarlos en tablas de hechos/dimensionales.
Un almacén de datos representa una estructura de datos orientada a temas, integrada, variable en el tiempo y no volátil.
Centrándose en el tema en lugar de en las operaciones, el DWH integra datos de múltiples fuentes, brindando al usuario una única fuente de información en un formato consistente. Dado que no es volátil, registra todos los cambios de datos como nuevas entradas sin borrar su estado anterior. Esta función está estrechamente relacionada con la variación temporal, ya que mantiene un registro de datos históricos, lo que le permite examinar los cambios a lo largo del tiempo.
Todas estas propiedades ayudan a las empresas a crear informes analíticos necesarios para estudiar cambios y tendencias.
Arquitectura de almacén de datos
Hay tres formas de construir un sistema de almacenamiento de datos. Estos enfoques se clasifican por el número de niveles en la arquitectura. Por lo tanto, puede tener un:
- Arquitectura de un solo nivel
- Arquitectura de dos niveles
- Arquitectura de tres niveles
Arquitectura de almacén de datos de un solo nivel
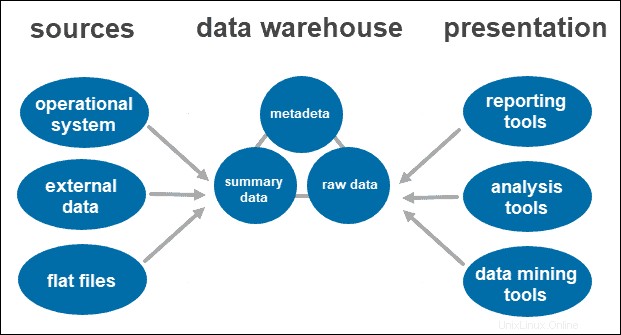
La arquitectura de un solo nivel no es un enfoque practicado con frecuencia. El objetivo principal de tener una arquitectura de este tipo es eliminar la redundancia al minimizar la cantidad de datos almacenados.
Su principal desventaja es que no tiene un componente que separe el procesamiento analítico del transaccional.
Arquitectura de almacén de datos de dos niveles
Una arquitectura de dos niveles incluye un área de preparación para todas las fuentes de datos, antes de la capa de almacenamiento de datos. Al agregar un área de preparación entre las fuentes y el repositorio de almacenamiento, se asegura de que todos los datos cargados en el almacén estén limpios y en el formato adecuado.
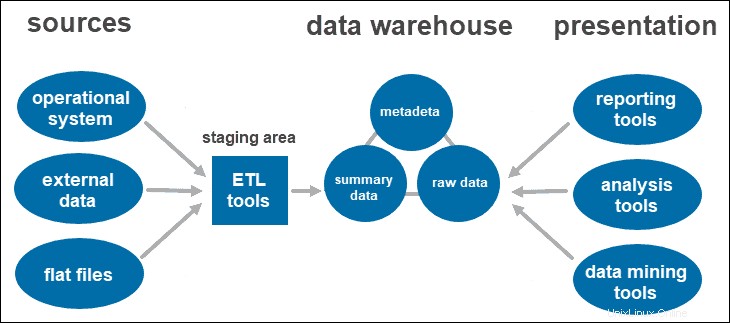
Este enfoque tiene ciertas limitaciones de red. Además, no puede expandirlo para admitir una mayor cantidad de usuarios.
Arquitectura de almacén de datos de tres niveles
El enfoque de tres niveles es la arquitectura más utilizada para los sistemas de almacenamiento de datos.
Esencialmente, consta de tres niveles:
- El nivel inferior es la base de datos del almacén, donde se cargan los datos limpios y transformados.
- El nivel medio es la capa de aplicación que proporciona una vista abstracta de la base de datos. Organiza los datos para que sean más adecuados para el análisis. Esto se hace con un servidor OLAP, implementado usando el modelo ROLAP o MOLAP.
- El nivel superior es donde el usuario accede e interactúa con los datos. Representa la capa de cliente front-end. Puede utilizar herramientas de informes, consultas, análisis o minería de datos.
Componentes del almacén de datos
De las arquitecturas descritas anteriormente, observa que algunos componentes se superponen, mientras que otros son exclusivos de la cantidad de niveles.
A continuación, encontrará algunos de los componentes más importantes del almacén de datos y sus funciones en el sistema.
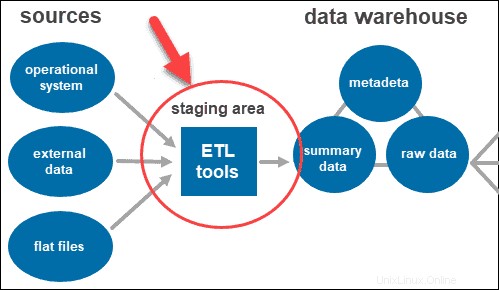
Herramientas ETL
ETL significa Extraer , Transformar y Cargar . La capa de ensayo utiliza herramientas ETL para extraer los datos necesarios de varios formatos y comprueba la calidad antes de cargarlos en el almacén de datos.
Los datos provenientes de la capa de fuente de datos pueden venir en una variedad de formatos. Antes de fusionar todos los datos recopilados de múltiples fuentes en una sola base de datos, el sistema debe limpiar y organizar la información.
La base de datos
El componente más crucial y el corazón de cada arquitectura es la base de datos. El almacén es donde se almacenan y se accede a los datos.
Al crear el sistema de almacenamiento de datos, primero debe decidir qué tipo de base de datos desea utilizar.
Hay cuatro tipos de bases de datos entre las que puede elegir:
- Bases de datos relacionales (bases de datos centradas en filas).
- Bases de datos de análisis (desarrollado para mantener y administrar análisis).
- Aplicaciones de almacenamiento de datos (software para la gestión de datos y hardware para el almacenamiento de datos ofrecidos por distribuidores externos).
- Bases de datos basadas en la nube (alojadas en la nube).
Datos
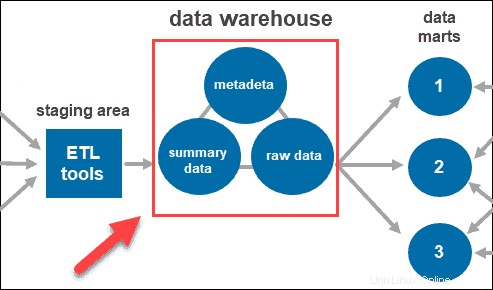
Una vez que el sistema limpia y organiza los datos, los almacena en el almacén de datos. El almacén de datos representa el repositorio central que almacena metadatos, datos resumidos y datos sin procesar provenientes de cada fuente.
- Metadatos es la información que define los datos. Su función principal es simplificar el trabajo con instancias de datos. Permite a los analistas de datos clasificar, ubicar y dirigir consultas a los datos requeridos.
- Datos resumidos es generado por el jefe de almacén. Se actualiza a medida que se cargan nuevos datos en el almacén. Este componente puede incluir datos poco o muy resumidos. Su función principal es acelerar el rendimiento de las consultas.
- Datos sin procesar es la carga de datos real en el repositorio, que no ha sido procesada. Tener los datos en su forma sin procesar los hace accesibles para su posterior procesamiento y análisis.
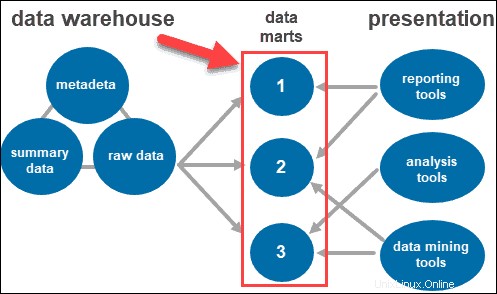
Herramientas de acceso
Los usuarios interactúan con la información recopilada a través de diferentes herramientas y tecnologías. Pueden analizar los datos, recopilar información y crear informes.
Algunas de las herramientas utilizadas incluyen:
- Herramientas de informes. Desempeñan un papel crucial en la comprensión de cómo le está yendo a su negocio y qué se debe hacer a continuación. Las herramientas de generación de informes incluyen visualizaciones como gráficos y cuadros que muestran cómo cambian los datos a lo largo del tiempo.
- Herramientas OLAP. Herramientas de procesamiento analítico en línea que permiten a los usuarios analizar datos multidimensionales desde múltiples perspectivas. Estas herramientas proporcionan un procesamiento rápido y un análisis valioso. Extraen datos de numerosos conjuntos de datos relacionales y los reorganizan en un formato multidimensional.
- Herramientas de minería de datos. Examine conjuntos de datos para encontrar patrones dentro del almacén y la correlación entre ellos. La minería de datos también ayuda a establecer relaciones cuando se analizan datos multidimensionales.
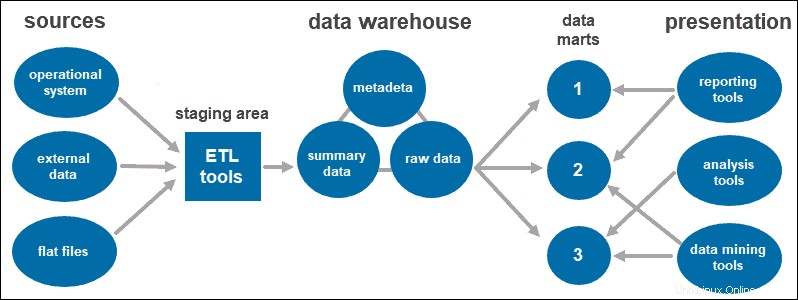
Martes de datos
Los data marts le permiten tener múltiples grupos dentro del sistema al segmentar los datos en el almacén en categorías. Divide los datos y los produce para un grupo de usuarios en particular.
Por ejemplo, puede utilizar data marts para clasificar la información por departamentos dentro de la empresa.
Mejores prácticas de almacenamiento de datos
El diseño de un almacén de datos depende de la comprensión de la lógica comercial de su caso de uso individual.
Los requisitos varían, pero hay mejores prácticas de almacenamiento de datos que debe seguir:
- Cree un modelo de datos. Empiece por identificar la lógica empresarial de la organización. Comprenda qué datos son vitales para la organización y cómo fluirán a través del almacén de datos.
- Opte por un estándar de arquitectura de almacenamiento de datos bien conocido. Un modelo de datos proporciona un marco y un conjunto de mejores prácticas a seguir al diseñar la arquitectura o solucionar problemas. Los estándares de arquitectura populares incluyen 3NF, modelado de Data Vault y esquema en estrella.
- Cree un diagrama de flujo de datos. Documente cómo fluyen los datos a través del sistema. Sepa cómo se relaciona eso con sus requisitos y lógica comercial.
- Tener una única fuente de verdad. Cuando se trata de tantos datos, una organización debe tener una única fuente de verdad. Consolide los datos en un solo repositorio.
- Usar la automatización. Las herramientas de automatización ayudan cuando se trata de grandes cantidades de datos.
- Permitir compartir metadatos. Diseñe una arquitectura que facilite el intercambio de metadatos entre los componentes del almacén de datos.
- Haga cumplir los estándares de codificación. Los estándares de codificación aseguran la eficiencia del sistema.