Introducción
Elasticsearch es un motor de búsqueda escalable en tiempo real implementado en clústeres. Cuando se combina con la orquestación de Kubernetes, Elasticsearch es fácil de configurar, administrar y escalar.
La implementación de un clúster de Elasticsearch de forma predeterminada crea tres pods. Cada pod cumple las tres funciones:maestro, datos y cliente. Sin embargo, la mejor práctica sería implementar manualmente múltiples pods de Elasticsearch dedicados para cada rol.
Este artículo explica cómo implementar Elasticsearch en Kubernetes en siete pods de forma manual y mediante un gráfico de Helm preconstruido.

Requisitos previos
- Un clúster de Kubernetes (usamos Minikube).
- El administrador de paquetes de Helm.
- La herramienta de línea de comandos de kubectl.
- Acceso a la línea de comando o terminal.
Cómo implementar Elasticsearch en Kubernetes manualmente
La mejor práctica es usar siete pods en el clúster de Elasticsearch:
- Tres módulos principales para administrar el clúster.
- Dos módulos de datos para almacenar datos y procesar consultas.
- Dos módulos de cliente (o de coordinación) para dirigir el tráfico.
La implementación manual de Elasticsearch en Kubernetes con siete pods dedicados es un proceso simple que requiere configurar los valores de Helm por función.
Paso 1:Configurar Kubernetes
1. El clúster requiere recursos significativos. Configure las CPU de Minikube en un mínimo de 4 y la memoria en 8192 MB:
minikube config set cpus 4
minikube config set memory 8192
2. Abra la terminal e inicie minikube con los siguientes parámetros:
minikube start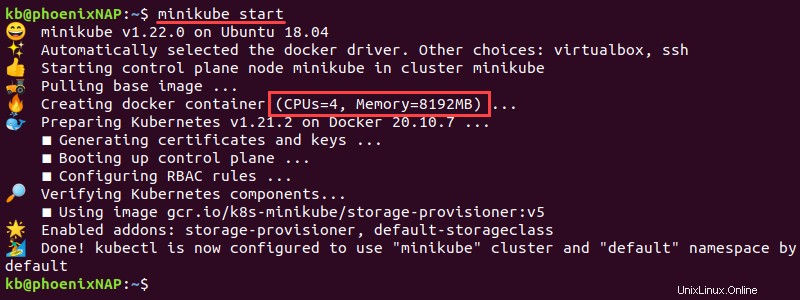
La instancia comienza con la memoria y las CPU configuradas.
3. Minikube requiere un values.yaml archivo para ejecutar Elasticsearch. Descarga el archivo con:
curl -O https://raw.githubusercontent.com/elastic/helm-charts/master/elasticsearch/examples/minikube/values.yaml
El archivo contiene información utilizada en el siguiente paso para las tres configuraciones de pod.
Paso 2:configurar los valores por función de pod
1. Copia el contenido de values.yaml archivo usando el cp comando en tres archivos de configuración de pod diferentes:
cp values.yaml master.yaml
cp values.yaml data.yaml
cp values.yaml client.yaml
2. Verifique los cuatro archivos YAML usando ls comando:
ls -l *.yaml3. Abra el master.yaml archivo con un editor de texto y agregue la siguiente configuración al principio:
# master.yaml
---
clusterName: "elasticsearch"
nodeGroup: "master"
roles:
master: "true"
ingest: "false"
data: "false"
replicas: 3
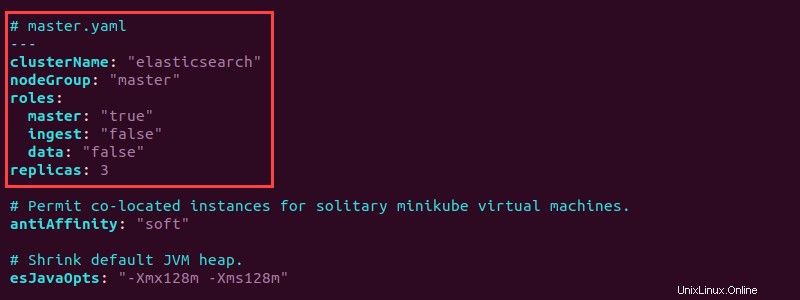
La configuración establece el grupo de nodos como maestro en la búsqueda elástica clúster y establece el rol maestro en "true" . Además, el master.yaml crea tres réplicas de nodos maestros.
El master.yaml completo se parece a lo siguiente:
# master.yaml
---
clusterName: "elasticsearch"
nodeGroup: "master"
roles:
master: "true"
ingest: "false"
data: "false"
replicas: 3
# Permit co-located instances for solitary minikube virtual machines.
antiAffinity: "soft
# Shrink default JVM heap.
esJavaOpts: "-Xmx128m -Xms128m"
# Allocate smaller chunks of memory per pod.
resources:
requests:
cpu: "100m"
memory: "512M"
limits:
cpu: "1000m"
memory: "512M"
# Request smaller persistent volumes.
volumeClaimTemplate:
accessModes: [ "ReadWriteOnce" ]
storageClassName: "standard"
resources:
requests:
storage: 100M
4. Guarde el archivo y cierre.
5. Abra data.yaml y agregue la siguiente información en la parte superior para configurar los pods de datos:
# data.yaml
---
clusterName: "elasticsearch"
nodeGroup: "data"
roles:
master: "false"
ingest: "true"
data: "true"
replicas: 2
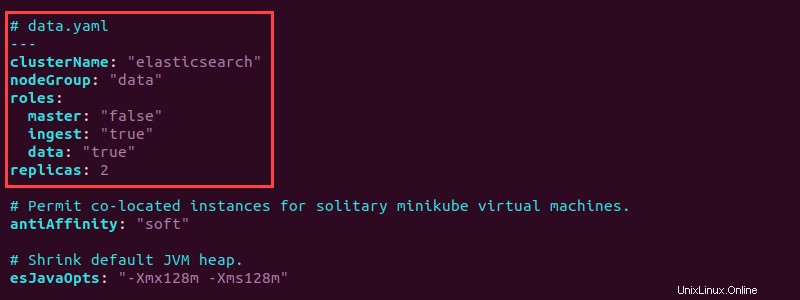
La configuración crea dos réplicas de pods de datos. Establezca los roles de datos e ingesta en "true" . Guarde el archivo y cierre.
6. Abra el client.yaml archivo y agregue la siguiente información de configuración en la parte superior:
# client.yaml
---
clusterName: "elasticsearch"
nodeGroup: "client"
roles:
master: "false"
ingest: "false"
data: "false"
replicas: 2
service:
type: "LoadBalancer"
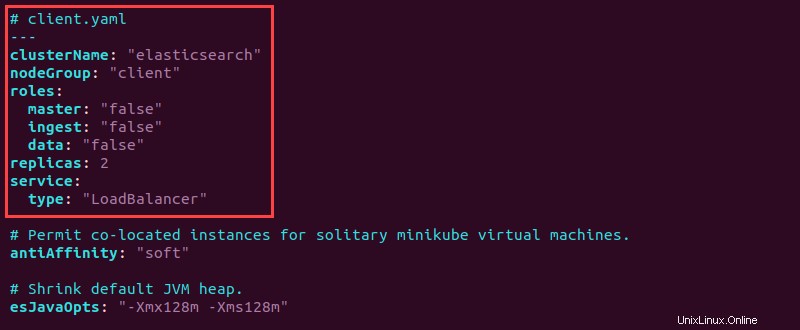
7. Guarde el archivo y cierre.
El cliente tiene todos los roles establecidos en "falso" ya que el cliente maneja las solicitudes de servicio. El tipo de servicio se designa como "LoadBalancer" para equilibrar las solicitudes de servicio de manera uniforme en todos los nodos.
Paso 3:implementar los pods de Elasticsearch por rol
1. Agregue el repositorio de Helm:
helm repo add elastic https://helm.elastic.co
2. Usa la helm install comando tres veces, una vez por cada archivo YAML personalizado creado en el paso anterior:
helm install elasticsearch-multi-master elastic/elasticsearch -f ./master.yaml
helm install elasticsearch-multi-data elastic/elasticsearch -f ./data.yaml
helm install elasticsearch-multi-client elastic/elasticsearch -f ./client.yaml
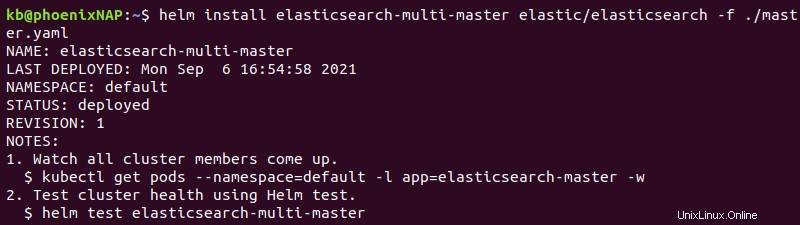
La salida imprime los detalles de implementación.
3. Espere a que se implementen los miembros del clúster. Utilice el siguiente comando para inspeccionar el progreso y confirmar la finalización:
kubectl get pods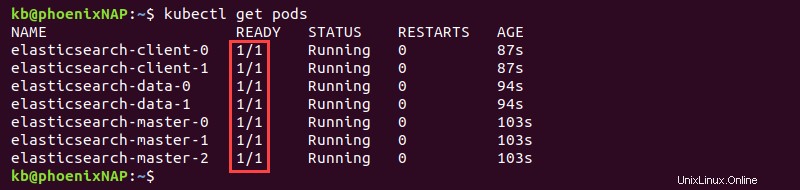
La salida muestra el LISTO columna con valores 1/1 una vez que se complete la implementación para los siete pods.
Paso 4:prueba de conexión
1. Para acceder a Elasticsearch localmente, reenvía el puerto 9200 usando kubectl comando:
kubectl port-forward service/elasticsearch-master
El comando reenvía la conexión y la mantiene abierta. Deje la ventana de la terminal abierta y continúe con el siguiente paso.
2. En otra pestaña de terminal, prueba la conexión con:
curl localhost:9200La salida imprime la información de implementación.
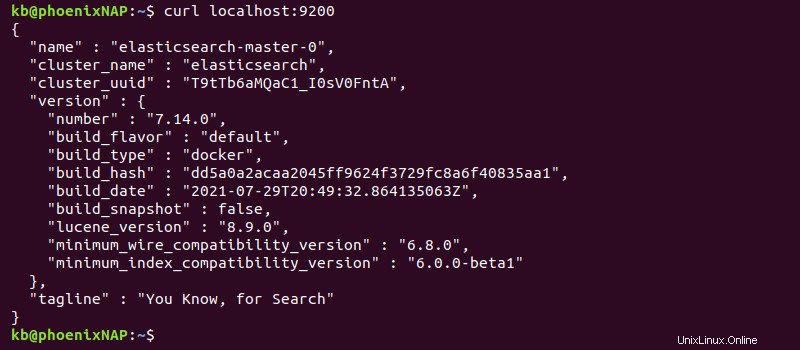
Alternativamente, acceda a localhost:9200 desde el navegador.
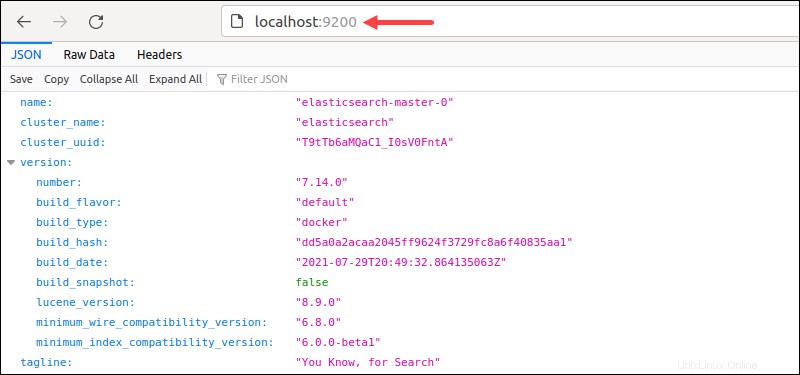
El resultado muestra los detalles del clúster en formato JSON, lo que indica que la implementación se realizó correctamente.
Cómo implementar Elasticsearch con Seven Pods mediante un gráfico de Helm prediseñado
En el repositorio de Bitnami está disponible un gráfico de Helm preconstruido para implementar Elasticsearch en siete pods dedicados. Instalar el gráfico de esta manera evita crear archivos de configuración manualmente.
Paso 1:Configurar Kubernetes
1. Asigne al menos 4 CPU y 8192 MB de memoria:
minikube config set cpus 4
minikube config set memory 8192
2. Inicie Minikube:
minikube startLa instancia de Minikube comienza con la configuración especificada.
Paso 2:agregue el repositorio de Bitnami e implemente el gráfico de Elasticsearch
1. Agregue el repositorio de Bitnami Helm con:
helm repo add bitnami https://charts.bitnami.com/bitnami
2. Instale el gráfico ejecutando:
helm install elasticsearch --set master.replicas=3,coordinating.service.type=LoadBalancer bitnami/elasticsearch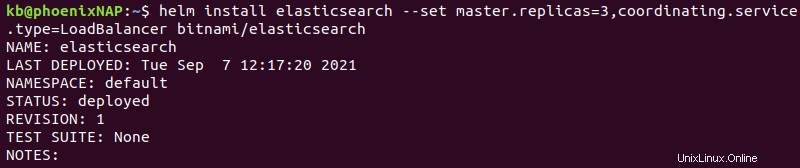
El comando tiene las siguientes opciones:
- Elasticsearch se instala con el nombre de versión
elasticsearch. master.replicas=3agrega tres réplicas maestras al clúster. Recomendamos ceñirse a tres nodos principales.coordinating.service.type=LoadBalancerestablece los nodos de cliente para equilibrar las solicitudes de servicio de manera uniforme en todos los nodos.
3. Supervise la implementación con:
kubectl get pods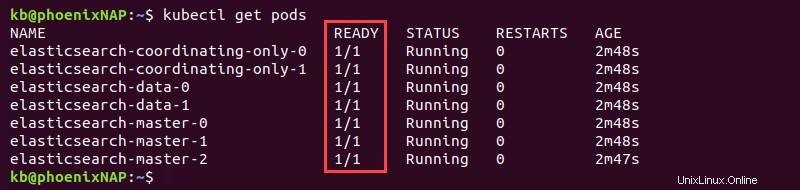
Los siete pods muestran 1/1 en el LISTO columna cuando Elasticsearch se implementa por completo.
Paso 3:prueba la conexión
1. Reenviar la conexión al puerto 9200 :
kubectl port-forward svc/elasticsearch-master 9200Deje la conexión abierta y continúe con el siguiente paso.
2. En otra pestaña de terminal, verifique la conexión con:
curl localhost:9200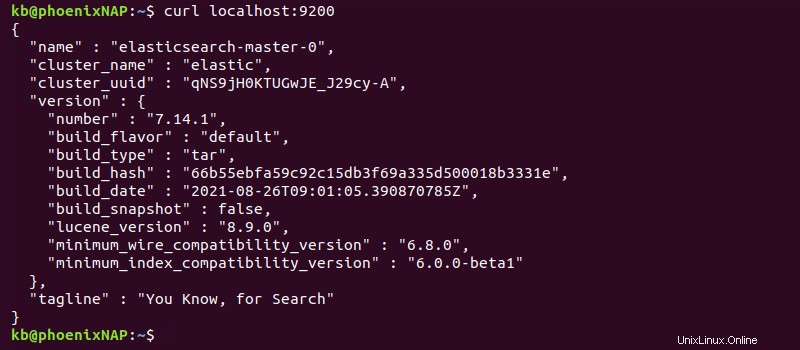
Alternativamente, acceda a la misma dirección desde el navegador para ver la información de implementación en formato JSON.