Introducción
Apache Spark es un marco utilizado en entornos informáticos de clúster para analizar big data . Esta plataforma se hizo muy popular debido a su facilidad de uso y a las velocidades de procesamiento de datos mejoradas con respecto a Hadoop.
Apache Spark puede distribuir una carga de trabajo entre un grupo de computadoras en un clúster para procesar grandes conjuntos de datos de manera más efectiva. Este motor de código abierto admite una amplia gama de lenguajes de programación. Esto incluye Java, Scala, Python y R.
En este tutorial, aprenderá a cómo instalar Spark en una máquina con Ubuntu . La guía le mostrará cómo iniciar un servidor maestro y esclavo y cómo cargar shells de Scala y Python. También proporciona los comandos Spark más importantes.

Requisitos previos
- Un sistema Ubuntu.
- Acceso a una terminal o línea de comando.
- Un usuario con sudo o root permisos.
Paquetes de instalación necesarios para Spark
Antes de descargar y configurar Spark, debe instalar las dependencias necesarias. Este paso incluye la instalación de los siguientes paquetes:
- JDK
- Escala
- Git
Abra una ventana de terminal y ejecute el siguiente comando para instalar los tres paquetes a la vez:
sudo apt install default-jdk scala git -yVerá qué paquetes se instalarán.
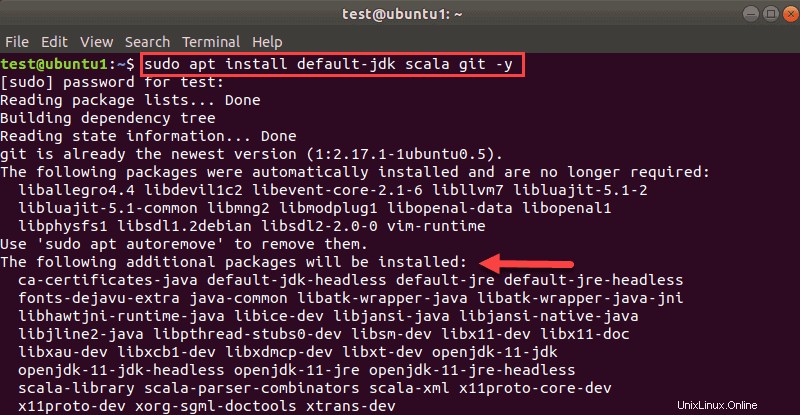
Una vez que se complete el proceso, verifique las dependencias instaladas ejecutando estos comandos:
java -version; javac -version; scala -version; git --version
La salida imprime las versiones si la instalación se completó correctamente para todos los paquetes.
Descargar y configurar Spark en Ubuntu
Ahora, debes descargar la versión de Spark que quieras formar su sitio web. Iremos por Spark 3.0.1 con Hadoop 2.7 ya que es la última versión al momento de escribir este artículo.
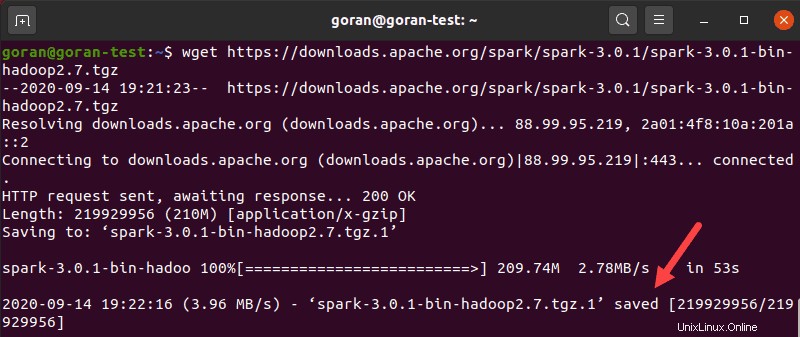
Usa el wget comando y el enlace directo para descargar el archivo Spark:
wget https://downloads.apache.org/spark/spark-3.0.1/spark-3.0.1-bin-hadoop2.7.tgzCuando se complete la descarga, verá el guardado mensaje.
Ahora, extraiga el archivo guardado usando tar:
tar xvf spark-*Deje que el proceso se complete. El resultado muestra los archivos que se están desempaquetando del archivo.
Finalmente, mueva el directorio desempaquetado spark-3.0.1-bin-hadoop2.7 al opt/spark directorio.
Usa el mv comando para hacerlo:
sudo mv spark-3.0.1-bin-hadoop2.7 /opt/sparkEl terminal no devuelve respuesta si mueve con éxito el directorio. Si escribe mal el nombre, recibirá un mensaje similar a:
mv: cannot stat 'spark-3.0.1-bin-hadoop2.7': No such file or directory.Configurar el entorno de Spark
Antes de iniciar un servidor maestro, debe configurar las variables de entorno. Hay algunas rutas de inicio de Spark que debe agregar al perfil de usuario.
Usa el echo comando para agregar estas tres líneas a .profile :
echo "export SPARK_HOME=/opt/spark" >> ~/.profile
echo "export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin" >> ~/.profile
echo "export PYSPARK_PYTHON=/usr/bin/python3" >> ~/.profileTambién puede agregar las rutas de exportación editando el .profile archivo en el editor de su elección, como nano o vim.
Por ejemplo, para usar nano, ingrese:
nano .profileCuando se cargue el perfil, desplácese hasta la parte inferior del archivo.
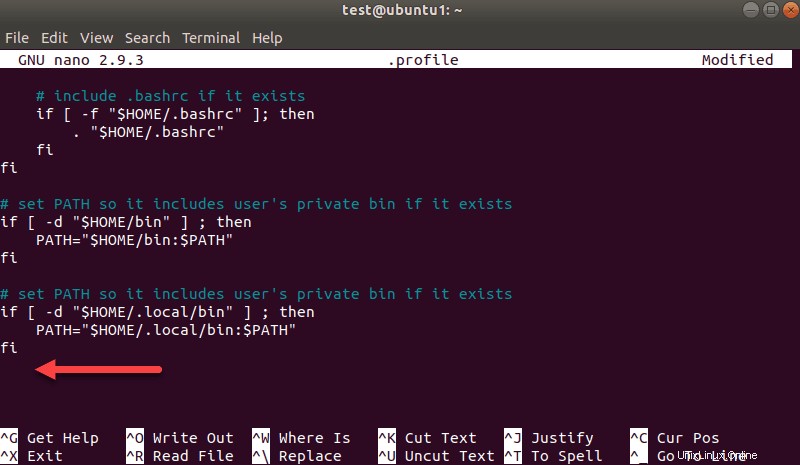
Luego, agrega estas tres líneas:
export SPARK_HOME=/opt/spark
export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin
export PYSPARK_PYTHON=/usr/bin/python3Salga y guarde los cambios cuando se le solicite.
Cuando termine de agregar las rutas, cargue el .profile archivo en la línea de comando escribiendo:
source ~/.profileIniciar servidor maestro Spark independiente
Ahora que ha completado la configuración de su entorno para Spark, puede iniciar un servidor maestro.
En la terminal, escribe:
start-master.shPara ver la interfaz de usuario de Spark Web, abra un navegador web e ingrese la dirección IP del host local en el puerto 8080.
http://127.0.0.1:8080/La página muestra su URL de Spark , información de estado para trabajadores, utilización de recursos de hardware, etc.
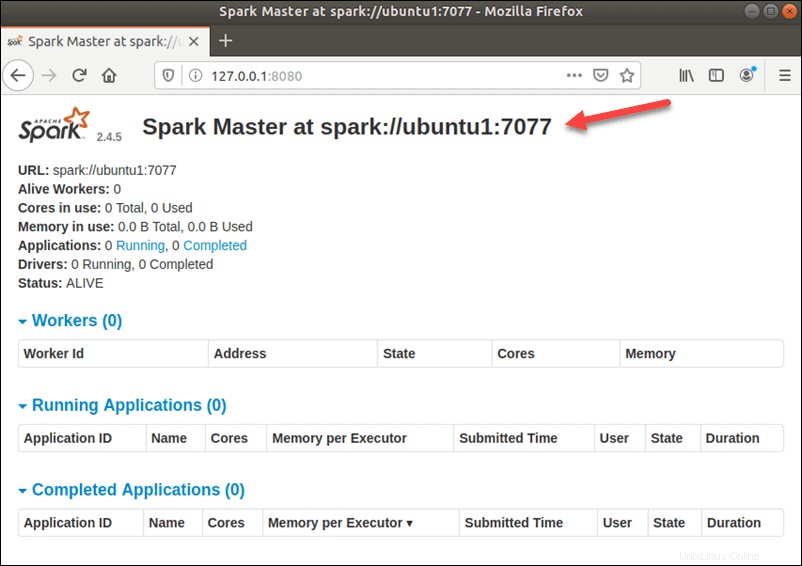
La URL de Spark Master es el nombre de su dispositivo en el puerto 8080. En nuestro caso, este es ubuntu1:8080 . Por lo tanto, hay tres formas posibles de cargar la interfaz de usuario web de Spark Master:
- 127.0.0.1:8080
- localhost:8080
- nombre del dispositivo :8080
Iniciar servidor Spark Slave (Iniciar un proceso de trabajo)
En esta configuración independiente de un solo servidor, iniciaremos un servidor esclavo junto con el servidor maestro.
Para hacerlo, ejecute el siguiente comando en este formato:
start-slave.sh spark://master:port
El master en el comando puede ser una IP o un nombre de host.
En nuestro caso es ubuntu1 :
start-slave.sh spark://ubuntu1:7077
Ahora que un trabajador está en funcionamiento, si vuelve a cargar la interfaz de usuario web de Spark Master, debería verlo en la lista:
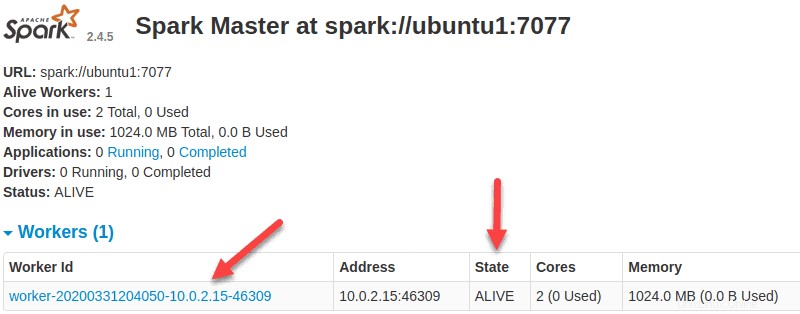
Especificar asignación de recursos para trabajadores
La configuración predeterminada al iniciar un trabajador en una máquina es usar todos los núcleos de CPU disponibles. Puede especificar el número de núcleos pasando -c marca al start-slave comando.
Por ejemplo, para iniciar un trabajador y asignar solo un núcleo de CPU a él, ingrese este comando:
start-slave.sh -c 1 spark://ubuntu1:7077Vuelva a cargar la interfaz de usuario web de Spark Master para confirmar la configuración del trabajador.

Del mismo modo, puede asignar una cantidad específica de memoria al iniciar un trabajador. La configuración predeterminada es usar cualquier cantidad de RAM que tenga su máquina, menos 1 GB.
Para iniciar un trabajador y asignarle una cantidad específica de memoria, agregue -m opción y un número. Para gigabytes, use G y para megabytes, use M .
Por ejemplo, para iniciar un trabajador con 512 MB de memoria, ingrese este comando:
start-slave.sh -m 512M spark://ubuntu1:7077Vuelva a cargar la interfaz de usuario web de Spark Master para ver el estado del trabajador y confirmar la configuración.

Carcasa de chispa de prueba
Después de terminar la configuración e iniciar el servidor maestro y esclavo, pruebe si Spark Shell funciona.
Cargue el shell ingresando:
spark-shellDebería obtener una pantalla con notificaciones e información de Spark. Scala es la interfaz predeterminada, por lo que el shell se carga cuando ejecuta spark-shell .
El final de la salida se ve así para la versión que estamos usando al momento de escribir esta guía:
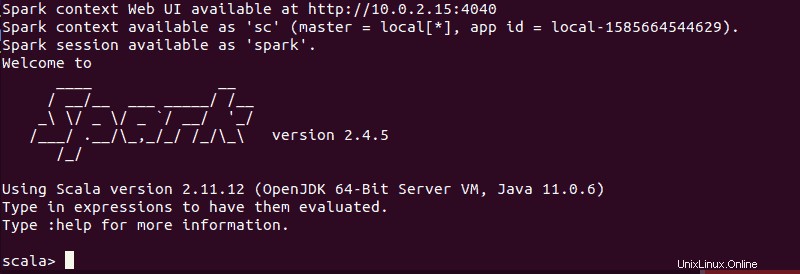
Escribe :q y presiona Entrar para salir de Scala.
Prueba Python en Spark
Si no desea utilizar la interfaz predeterminada de Scala, puede cambiar a Python.
Asegúrese de salir de Scala y luego ejecute este comando:
pysparkLa salida resultante es similar a la anterior. Hacia la parte inferior, verá la versión de Python.
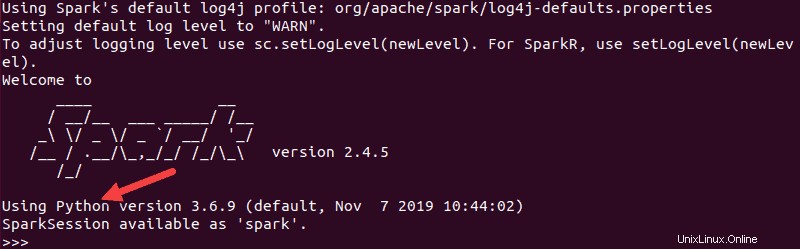
Para salir de este shell, escriba quit() y pulsa Intro .
Comandos básicos para iniciar y detener el servidor maestro y los trabajadores
A continuación, se encuentran los comandos básicos para iniciar y detener el servidor maestro y los trabajadores de Apache Spark. Dado que esta configuración es solo para una máquina, los scripts que ejecuta por defecto son el host local.
Para empezar un maestro servidor instancia en la máquina actual, ejecute el comando que usamos anteriormente en la guía:
start-master.shPara detener al maestro instancia iniciada al ejecutar el script anterior, ejecute:
stop-master.shPara detener a un trabajador en ejecución proceso, ingrese este comando:
stop-slave.shLa página Spark Master, en este caso, muestra el estado del trabajador como MUERTO.

Puede iniciar tanto el maestro como el servidor instancias usando el comando start-all:
start-all.shDel mismo modo, puede detener todas las instancias usando el siguiente comando:
stop-all.sh