Aquí veremos cómo instalar Apache Spark en Ubuntu 20.04 o 18.04, los comandos serán aplicables para Linux Mint, Debian y otros sistemas Linux similares.
Apache Spark es una herramienta de procesamiento de datos de propósito general llamada motor de procesamiento de datos. Utilizado por ingenieros de datos y científicos de datos para realizar consultas de datos extremadamente rápidas en grandes cantidades de datos en el rango de terabytes. Es un marco para cálculos basados en clúster que compite con el clásico Hadoop Map/Reduce al usar la RAM disponible en el clúster para una ejecución más rápida de los trabajos.
Además, Spark también ofrece la opción de controlar los datos a través de SQL, procesarlos mediante transmisión (casi) en tiempo real y proporciona su propia base de datos de gráficos y una biblioteca de aprendizaje automático. El marco ofrece tecnologías en memoria para este propósito, es decir, puede almacenar consultas y datos directamente en la memoria principal de los nodos del clúster.
Apache Spark es ideal para procesar grandes cantidades de datos rápidamente. El modelo de programación de Spark se basa en conjuntos de datos distribuidos resistentes (RDD), una clase de colección que opera distribuida en un clúster. Esta plataforma de código abierto admite una variedad de lenguajes de programación como Java, Scala, Python y R.
Pasos para la instalación de Apache Spark en Ubuntu 20.04
Los pasos que se dan aquí se pueden usar para otras versiones de Ubuntu como 21.04/18.04, incluso en Linux Mint, Debian y Linux similar.
1. Instalar Java con otras dependencias
Aquí estamos instalando la última versión disponible de Jave que es el requisito de Apache Spark junto con algunas otras cosas:Git y Scala para ampliar sus capacidades.
sudo apt install default-jdk scala git
2. Descarga Apache Spark en Ubuntu 20.04
Ahora, visite el sitio web oficial de Spark y descargue la última versión disponible. Sin embargo, mientras escribía este tutorial, la última versión era 3.1.2. Por lo tanto, aquí estamos descargando lo mismo, en caso de que sea diferente cuando esté realizando la instalación de Spark en su sistema Ubuntu, hágalo. Simplemente copie el enlace de descarga de esta herramienta y úsela con wget o descargar directamente en su sistema.
wget https://downloads.apache.org/spark/spark-3.1.2/spark-3.1.2-bin-hadoop3.2.tgz
3. Extrae Spark a /opt
Para asegurarnos de que no eliminemos la carpeta extraída accidentalmente, colóquela en un lugar seguro, es decir, /opt directorio.
sudo mkdir /opt/spark
sudo tar -xf spark*.tgz -C /opt/spark --strip-component 1
Además, cambia el permiso de la carpeta, para que Spark pueda escribir dentro de ella.
sudo chmod -R 777 /opt/spark
4. Agregue la carpeta Spark a la ruta del sistema
Ahora, como hemos movido el archivo a /opt directorio, para ejecutar el comando Spark en la terminal tenemos que mencionar su ruta completa cada vez que es molesto. Para solucionar esto, configuramos variables de entorno para Spark agregando sus rutas de inicio al archivo de perfil/bashrc del sistema. Esto nos permite ejecutar sus comandos desde cualquier lugar de la terminal sin importar en qué directorio nos encontremos.
echo "export SPARK_HOME=/opt/spark" >> ~/.bashrc echo "export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin" >> ~/.bashrc echo "export PYSPARK_PYTHON=/usr/bin/python3" >> ~/.bashrc
Recargar shell:
source ~/.bashrc
5. Inicie el servidor maestro Apache Spark en Ubuntu
Como ya hemos configurado el entorno variable para Spark, ahora iniciemos su servidor maestro independiente ejecutando su script:
start-master.sh
Cambiar la interfaz de usuario web de Spark Master y el puerto de escucha (opcional, usar solo si es necesario)
Si desea utilizar un puerto personalizado, es posible utilizar las opciones o los argumentos que se indican a continuación.
–puerto – Puerto para escuchar el servicio (predeterminado:7077 para maestro, aleatorio para trabajador)
–webui-port – Puerto para interfaz de usuario web (predeterminado:8080 para maestro, 8081 para trabajador)
Ejemplo – Quiero ejecutar Spark web UI en 8082 y hacer que escuche el puerto 7072, luego el comando para iniciarlo será así:
start-master.sh --port 7072 --webui-port 8082
6. Acceda a Spark Master (spark://Ubuntu:7077) – Interfaz web
Ahora, acceda a la interfaz web del servidor maestro de Spark que se ejecuta en el número de puerto 8080 . Entonces, en su navegador abra http://127.0.0.1:8080 .
Nuestro maestro se ejecuta en spark://Ubuntu :7077, donde Ubuntu es el nombre de host del sistema y podría ser diferente en su caso.
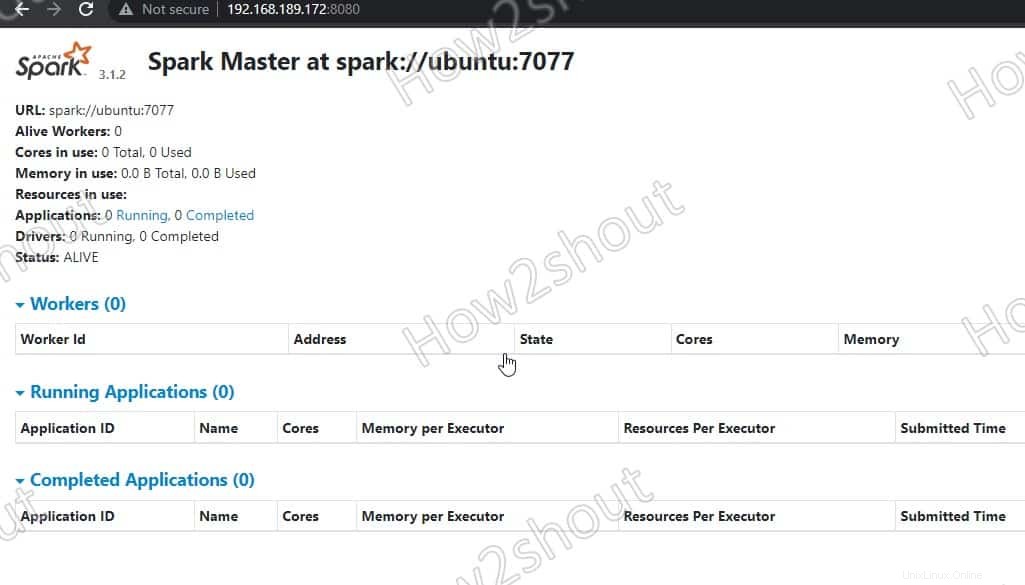
Si está utilizando un servidor CLI y desea utilizar el navegador del otro sistema que puede acceder a la dirección IP del servidor, primero abra 8080 en el cortafuegos. Esto le permitirá acceder a la interfaz web de Spark de forma remota en:http://your-server-ip-addres:8080
sudo ufw allow 8080
7. Ejecutar script de trabajador esclavo
Para ejecutar Spark slave worker, tenemos que iniciar su script disponible en el directorio que hemos copiado en /opt . La sintaxis del comando será:
Sintaxis del comando:
start-worker.sh spark://hostname:port
En el comando anterior, cambie el nombre de host y puerto . Si no conoce su nombre de host, simplemente escriba- hostname en terminales Donde el puerto predeterminado de maestro se está ejecutando en 7077, se puede ver en la captura de pantalla anterior .
Entonces, como nuestro nombre de host es ubuntu, el comando será así:
start-worker.sh spark://ubuntu:7077
Actualizar la interfaz web y verás el ID del trabajador y la cantidad de memoria asignado a él:
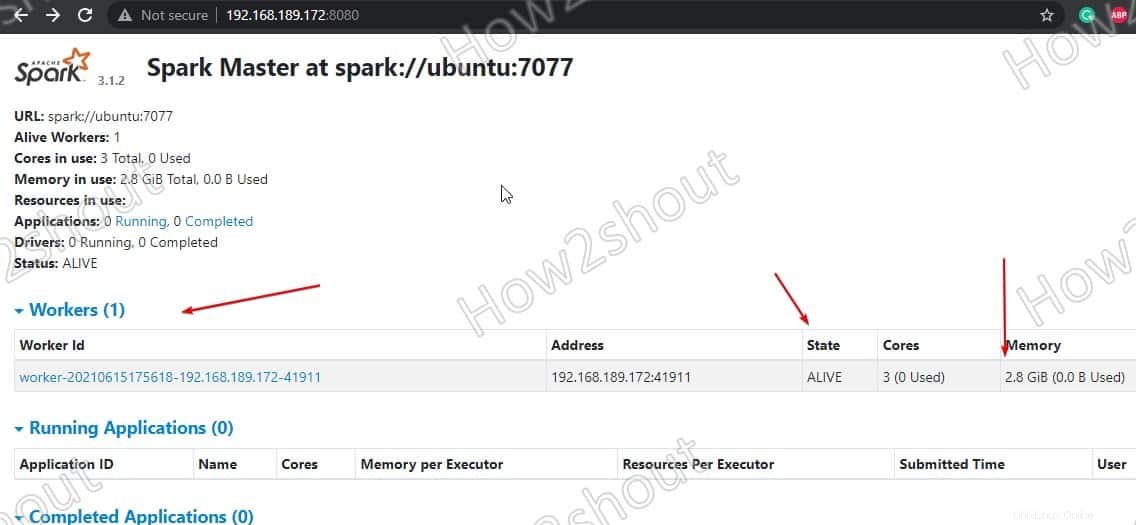
Si lo desea, puede cambiar la memoria/ram asignada al trabajador. Para eso, debe reiniciar el trabajador con la cantidad de RAM que desea proporcionarle.
stop-worker.sh start-worker.sh -m 212M spark://ubuntu:7077
Usar Spark Shell
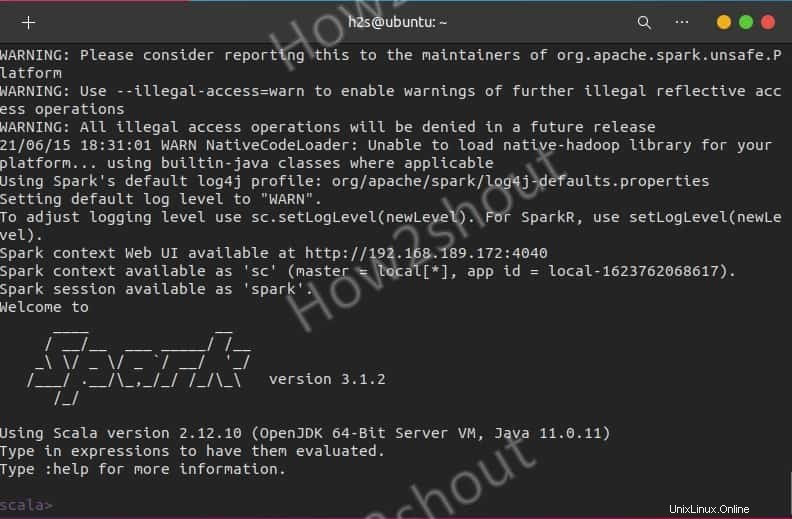
Aquellos que quieran usar Spark Shell para comenzar a programar pueden acceder escribiendo directamente:
spark-shell
Para ver las opciones admitidas, escriba- :help y para salir del uso de shell – :quite
Para comenzar con Python shell en lugar de Scala, use:
pyspark
Comandos de inicio y parada del servidor
Si desea iniciar o detener maestros/trabajadores instancias, luego use los scripts correspondientes:
stop-master.sh stop-worker.sh
Para detener todo a la vez
stop-all.sh
O empezar todos a la vez:
start-all.sh
Pensamientos finales:
De esta forma, podremos instalar y empezar a utilizar Apache Spark en Ubuntu Linux. Para saber más sobre ti puedes consultar la documentación oficial . Sin embargo, en comparación con Hadoop, Spark todavía es relativamente joven, por lo que debe contar con algunas asperezas. Sin embargo, ya se ha probado muchas veces en la práctica y permite nuevos casos de uso en el área de datos grandes o rápidos a través de la ejecución rápida de trabajos y el almacenamiento en caché de datos. Y, por último, ofrece una API uniforme para herramientas que, de lo contrario, tendrían que operarse y operarse por separado en el entorno de Hadoop.