Introducción
Cassandra es un software de base de datos distribuida de código abierto para manejar bases de datos NoSQL. Este software utiliza CQL (Lenguaje de consulta de Cassandra) como base para la comunicación. CQL mantiene los datos en tablas organizadas en un conjunto de filas con columnas que contienen pares clave-valor.
Las tablas CQL se agrupan en contenedores de datos llamados espacios de claves en Cassandra. Los datos almacenados en un espacio de claves no están relacionados con otros datos del clúster. Por lo tanto, puede tener tablas para múltiples propósitos diferentes en espacios de claves separados en un clúster y los datos no coincidirán.
En esta guía, aprenderá cómo crear una tabla de Cassandra para diferentes propósitos y cómo modificar, eliminar o truncar tablas usando el shell de Cassandra.

Requisitos previos
- Software de base de datos Cassandra instalado en su sistema
- Acceso a una terminal o herramienta de línea de comandos para cargar cqlsh
- Un usuario con los permisos necesarios para ejecutar los comandos
Selección del espacio de claves para la tabla Cassandra
Antes de comenzar a agregar una tabla, debe determinar el espacio de teclas donde desea crear su tabla . Hay dos opciones para hacer esto.
Opción 1:El comando USE
Ejecute USE comando para seleccionar un espacio de teclas al que se aplicarán todos sus comandos. Para hacer eso, en el tipo de shell cqlsh:
USE keyspace_name;Luego, puede comenzar a agregar tablas.
Opción 2:especificar el nombre del espacio de claves en la consulta
La segunda opción es especificar el nombre del espacio de claves en la consulta para la creación de la tabla. La primera parte del comando, antes de los nombres de las columnas y las opciones, se ve así:
CREATE TABLE keyspace_name.table_nameDe esta manera, crea inmediatamente una tabla en el espacio de claves que definió.
Sintaxis básica para crear tablas Cassandra
La creación de tablas con CQL se parece a las consultas SQL. En esta sección, le mostraremos la sintaxis básica para crear tablas en Cassandra.
La sintaxis básica para crear una tabla se ve así:
CREATE TABLE tableName (
columnName1 dataType,
columnName2 dataType,
columnName2 datatype
PRIMARY KEY (columnName)
);
Opcionalmente, puede definir valores y propiedades de tabla adicionales usando WITH :
WITH propertyName=propertyValue;Por ejemplo, úselo para definir cómo almacenar los datos en el disco o si usar compresión.
Tipos de clave principal de Cassandra
Cada tabla en Cassandra necesita tener una clave principal, lo que hace que una fila sea única. Con claves primarias, usted determina qué nodo almacena los datos y cómo los divide.
Hay dos tipos de claves primarias:
- Clave primaria simple . Contiene solo un nombre de columna como clave de partición para determinar qué nodos almacenarán los datos.
- Clave primaria compuesta. Utiliza una clave de partición y múltiples columnas de agrupación para definir dónde almacenar los datos y cómo ordenarlos en una partición.
- Clave de partición compuesta. En este caso, hay varias columnas que determinan dónde almacenar los datos. De esta manera, puede dividir los datos en partes más pequeñas para distribuirlos en varias particiones y evitar puntos de acceso.
Cómo crear una tabla Cassandra
Las siguientes secciones explican cómo crear tablas con diferentes tipos de claves primarias. Primero, seleccione un espacio de claves en el que desee crear una tabla. En nuestro caso:
USE businesinfo;Cada tabla contiene columnas y un tipo de datos Cassandra para cada entrada.
Crear tabla con clave primaria simple
El primer ejemplo es una tabla básica con proveedores. El ID es único para cada proveedor y servirá como clave principal.
La consulta CQL se ve así:
CREATE TABLE suppliers (
supp_id int PRIMARY KEY,
supp_city text,
supp_email text,
supp_fee int,
supp_name text,
supp_phone int
);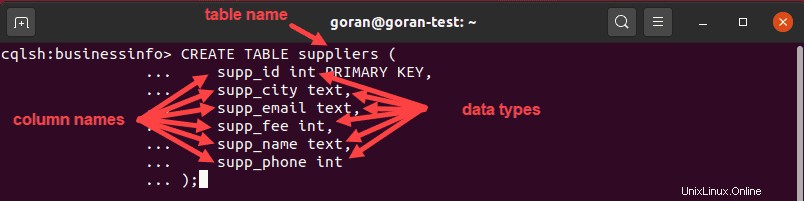
Esta consulta creó una tabla llamada proveedor con supp_id como clave principal de la tabla. Cuando usa una clave principal simple con el nombre de la columna como clave de partición, puede colocarla al principio de la consulta (junto a la columna que servirá como clave principal) o al final y luego especificar el nombre de la columna :
CREATE TABLE suppliers (
supp_id int,
supp_city text,
supp_email text,
supp_fee int,
supp_name text,
supp_phone int
PRIMARY KEY(supp_id)
);Para ver si la tabla está en el espacio de claves, escriba:
DESCRIBE TABLES;El resultado enumera todas las tablas en ese espacio de claves junto con la que creó.

Para mostrar el contenido de las tablas, ingrese:
SELECT * FROM suppliers;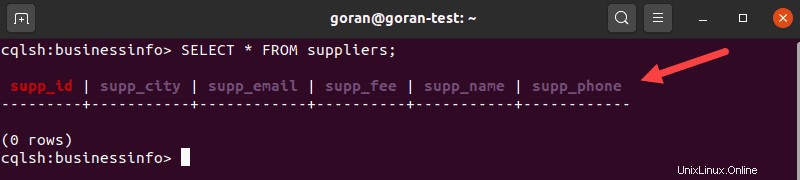
El resultado muestra todas las columnas definidas al crear una tabla.
Otra forma de ver los detalles de una tabla es usar DESCRIBE y especifique un nombre de tabla:
DESCRIBE suppliers;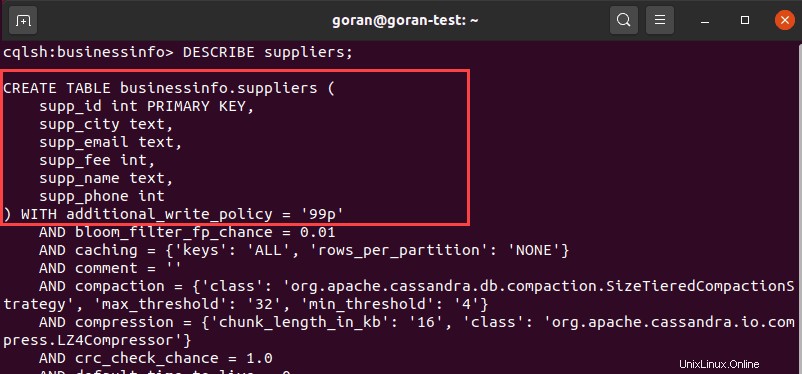
La salida muestra las columnas y la configuración predeterminada de la tabla.
Crear tabla con clave principal compuesta
Para consultar y ordenar los resultados en un orden específico, cree una tabla con una clave principal compuesta.
Por ejemplo, crea una tabla para los proveedores y todos los productos que ofrecen. Dado que los productos pueden no ser únicos para cada proveedor, debe agregar una o más columnas de agrupación en la clave principal para que sea único.
El esquema de la tabla se ve así:
CREATE TABLE suppliers_by_product (
supp_product text,
supp_id int,
supp_product_quantity text,
PRIMARY KEY(supp_product, supp_id)
);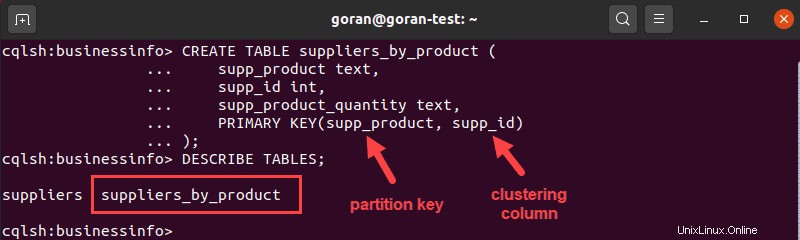
En este caso, usamos supp_product y supp_id para crear una clave compuesta única. Aquí, la primera entrada en brackets supp_product es la clave de partición. Determina dónde almacenar los datos, es decir, cómo el sistema divide los datos.
La siguiente entrada es la columna de agrupación que determina cómo Cassandra ordena los datos, en nuestro caso es por supp_id .
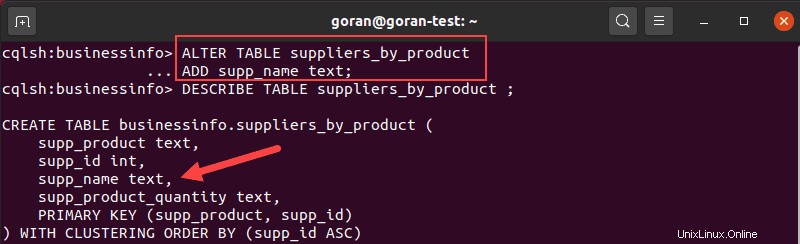
La imagen de arriba muestra que la tabla se creó con éxito. Para verificar los detalles de la tabla, ejecute DESCRIBE TABLE consulta para la nueva tabla:
DESCRIBE TABLE suppliers_by_product;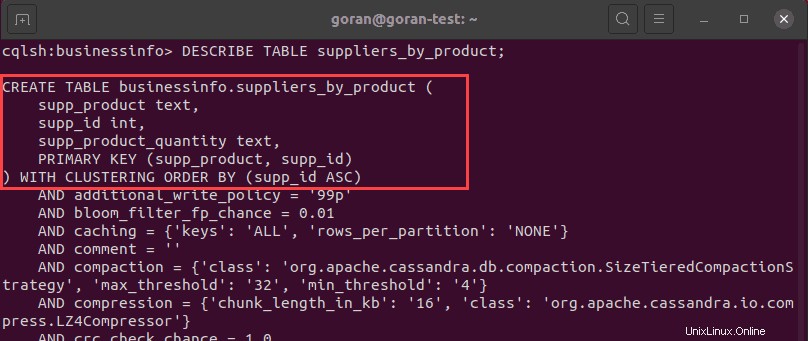
La configuración predeterminada para el orden de agrupación es ascendente (ASC). Puede cambiar a descendente (DESC) agregando la siguiente declaración después de la clave principal:
WITH CLUSTERING ORDER BY (supp_id DESC);Especificamos una columna de agrupación después de la clave de partición. En caso de que necesite ordenar los datos usando dos columnas, agregue otra columna dentro de los corchetes de clave principal.
Crear tablas usando una clave de partición compuesta
La creación de una tabla con una clave de partición compuesta es útil cuando un nodo almacena un gran volumen de datos y desea dividir la carga en varios nodos.
En este caso, defina una clave principal con una clave de partición que consta de varias columnas. Necesitas usar corchetes dobles. Luego, agregue columnas de agrupamiento como lo hicimos anteriormente para crear una clave principal única.
Por ejemplo:
CREATE TABLE suppliers_by_product_type (
supp_product_consume text,
supp_product_stock text,
supp_id int,
supp_name text,
PRIMARY KEY((supp_product_consume, supp_product_stock), supp_id)
);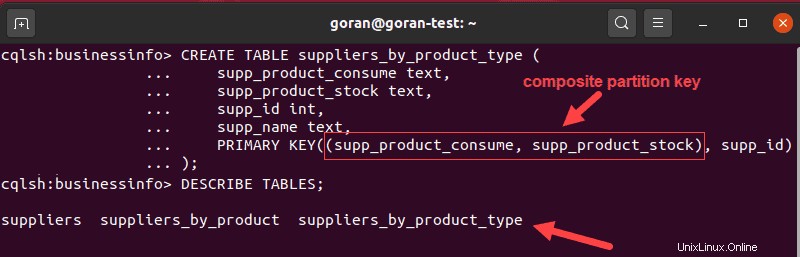
En el ejemplo anterior, separamos los datos en dos categorías, productos consumibles del proveedor y productos almacenables, y distribuimos los datos mediante una clave de partición compuesta.
Si utiliza una clave principal compuesta con una clave de partición simple y varias columnas de agrupación en clústeres, entonces un nodo manejaría todos los datos ordenados por varias columnas.
Mesa desplegable Cassandra
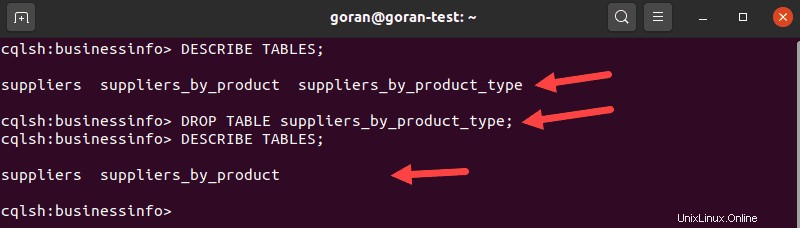
Para eliminar una tabla en Cassandra, use el DROP TABLE declaración. Para elegir una tabla que desea eliminar, ingrese:
DESCRIBE TABLES;Encuentra la mesa que deseas eliminar. Usa el nombre de la tabla para eliminarla:
DROP TABLE suppliers_by_product_type;
Ejecute DESCRIBE TABLES consulta nuevamente para verificar que eliminaste la tabla con éxito.
Alter Mesa Cassandra
Cassandra CQL le permite agregar o eliminar columnas de una tabla. Usa la ALTER TABLE comando para realizar cambios en una tabla.
Agregar una columna a una tabla
Antes de agregar una columna a una tabla, le sugerimos que vea el contenido de la tabla para verificar que el nombre de la columna aún no existe.
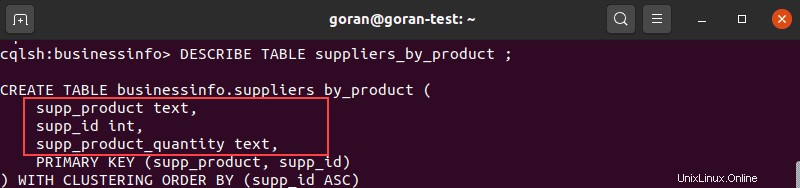
Una vez que verifique, use la ALTER TABLE consulta en este formato para agregar una columna:
ALTER TABLE suppliers_by_product
ADD supp_name text;Describa la tabla para confirmar que la columna aparece en la lista.
Eliminar una columna de una tabla
Similar a agregar una columna, puede quitar una columna de una tabla. Ubique la columna que desea eliminar usando DESCRIBE TABLES consulta.
Luego ingrese:
ALTER TABLE suppliers_by_product
DROP supp_product_quantity;Tabla truncada de Cassandra
Si no desea eliminar una tabla completa, pero necesita eliminar todas las filas, use el TRUNCATE comando.
Por ejemplo, para eliminar todas las filas de la tabla proveedores , introduce:
TRUNCATE suppliers;
Para verificar que ya no haya filas en su tabla, use SELECT declaración.
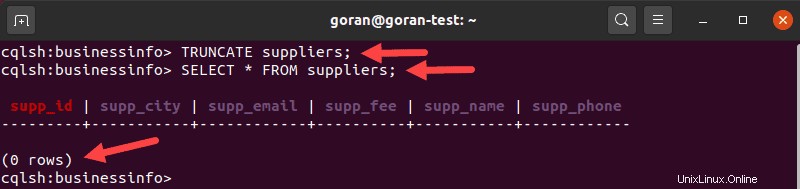
Una vez que trunca una tabla, los cambios son permanentes, así que tenga cuidado al usar esta consulta.