Introducción
Apache Spark es un marco de código abierto que procesa grandes volúmenes de flujo de datos de múltiples fuentes. Spark se utiliza en computación distribuida con aplicaciones de aprendizaje automático, análisis de datos y procesamiento paralelo de gráficos.
Esta guía le mostrará cómo instalar Apache Spark en Windows 10 y probar la instalación.

Requisitos previos
- Un sistema que ejecuta Windows 10
- Una cuenta de usuario con privilegios de administrador (necesaria para instalar software, modificar permisos de archivos y modificar la RUTA del sistema)
- Símbolo del sistema o Powershell
- Una herramienta para extraer archivos .tar, como 7-Zip
Instalar Apache Spark en Windows
La instalación de Apache Spark en Windows 10 puede parecer complicada para los usuarios novatos, pero este sencillo tutorial lo pondrá en marcha. Si ya tiene instalado Java 8 y Python 3, puede omitir los dos primeros pasos.
Paso 1:Instalar Java 8
Apache Spark requiere Java 8. Puede verificar si Java está instalado usando el símbolo del sistema.
Abra la línea de comando haciendo clic en Inicio> escribe cmd> haga clic en Símbolo del sistema .
Escriba el siguiente comando en el símbolo del sistema:
java -versionSi Java está instalado, responderá con el siguiente resultado:
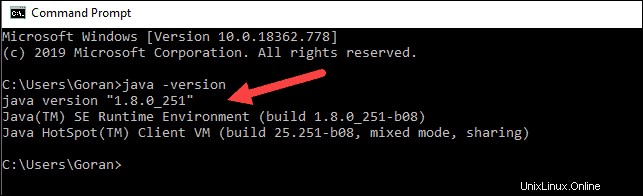
Su versión puede ser diferente. El segundo dígito es la versión de Java, en este caso, Java 8.
Si no tiene Java instalado:
1. Abra una ventana del navegador y vaya a https://java.com/en/download/.
2. Haga clic en Descargar Java y guarde el archivo en la ubicación que elija.
3. Una vez que finalice la descarga, haga doble clic en el archivo para instalar Java.
Paso 2:Instalar Python
1. Para instalar el administrador de paquetes de Python, vaya a https://www.python.org/ en su navegador web.
2. Mueva el mouse sobre Descargar opción de menú y haga clic en Python 3.8.3 . 3.8.3 es la última versión en el momento de escribir el artículo.
3. Una vez que finalice la descarga, ejecute el archivo.
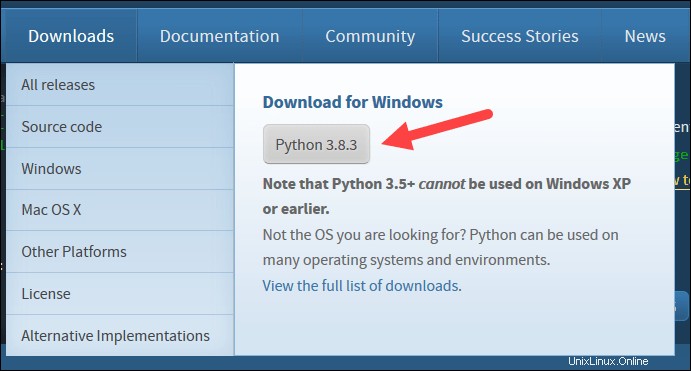
4. Cerca de la parte inferior del primer cuadro de diálogo de configuración, marque Agregar Python 3.8 a PATH . Deje la otra casilla marcada.
5. A continuación, haga clic en Personalizar instalación .
6. Puede dejar todas las casillas marcadas en este paso o puede desmarcar las opciones que no desea.
7. Haga clic en Siguiente .
8. Seleccione la casilla Instalar para todos los usuarios y deja las otras casillas como están.
9. En Personalizar ubicación de instalación, haga clic en Examinar y navegue a la unidad C. Agregue una nueva carpeta y asígnele el nombre Python .
10. Seleccione esa carpeta y haga clic en Aceptar .
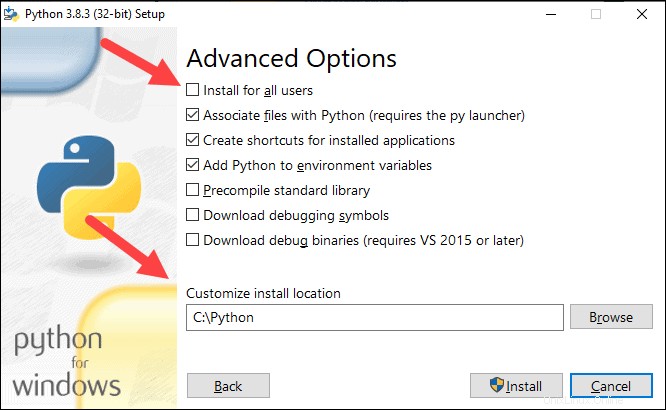
11. Haga clic en Instalar y deja que se complete la instalación.
12. Cuando finalice la instalación, haga clic en Desactivar límite de longitud de ruta en la parte inferior y luego haga clic en Cerrar .
13. Si tiene un símbolo del sistema abierto, reinícielo. Verifique la instalación comprobando la versión de Python:
python --version
La salida debe imprimir Python 3.8.3 .
Paso 3:Descarga Apache Spark
1. Abra un navegador y vaya a https://spark.apache.org/downloads.html.
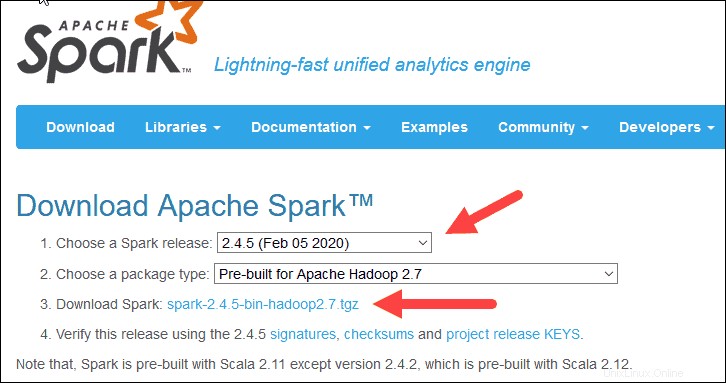
2. En Descargar Apache Spark título, hay dos menús desplegables. Use la versión actual que no es de vista previa.
- En nuestro caso, en Elija una versión de Spark seleccione en el menú desplegable 2.4.5 (5 de febrero de 2020) .
- En el segundo menú desplegable Elija un tipo de paquete , deje la selección Prediseñado para Apache Hadoop 2.7 .
3. Haga clic en spark-2.4.5-bin-hadoop2.7.tgz enlace.
4. Se carga una página con una lista de espejos donde puede ver diferentes servidores desde los que descargar. Elija cualquiera de la lista y guarde el archivo en su carpeta de Descargas.
Paso 4:Verificar el archivo del software Spark
1. Verifique la integridad de su descarga comprobando la suma de comprobación del archivo Esto garantiza que esté trabajando con software inalterado y sin corromper.
2. Vuelve a Descarga de Spark página y abra el Checksum enlace, preferiblemente en una nueva pestaña.
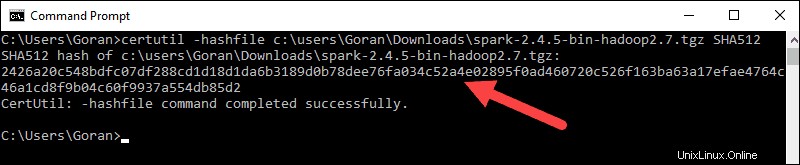
3. A continuación, abra una línea de comando e ingrese el siguiente comando:
certutil -hashfile c:\users\username\Downloads\spark-2.4.5-bin-hadoop2.7.tgz SHA512
4. Cambie el nombre de usuario a su nombre de usuario. El sistema muestra un código alfanumérico largo, junto con el mensaje Certutil: -hashfile completed successfully .
5. Compare el código con el que abrió en una nueva pestaña del navegador. Si coinciden, su archivo de descarga no está dañado.
Paso 5:Instale Apache Spark
La instalación de Apache Spark implica extraer el archivo descargado a la ubicación deseada.
1. Cree una nueva carpeta llamada Spark en la raíz de su unidad C:. Desde una línea de comando, ingrese lo siguiente:
cd \
mkdir Spark2. En Explorer, busque el archivo Spark que descargó.
3. Haga clic derecho en el archivo y extráigalo a C:\Spark usando la herramienta que tiene en su sistema (por ejemplo, 7-Zip).
4. Ahora, su C:\Spark la carpeta tiene una nueva carpeta spark-2.4.5-bin-hadoop2.7 con los archivos necesarios dentro.
Paso 6:Agregue el archivo winutils.exe
Descarga el winutils.exe archivo para la versión subyacente de Hadoop para la instalación de Spark que descargó.
1. Navegue a esta URL https://github.com/cdarlint/winutils y dentro del bin carpeta, busque winutils.exe y haga clic en él.
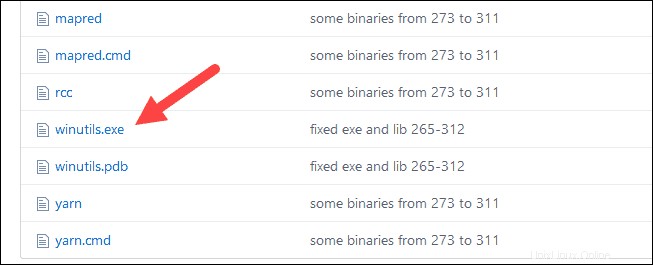
2. Encuentra la Descargar botón en el lado derecho para descargar el archivo.
3. Ahora, crea nuevas carpetas Hadoop y papelera en C:utilizando el Explorador de Windows o el símbolo del sistema.
4. Copie el archivo winutils.exe de la carpeta Descargas a C:\hadoop\bin .
Paso 7:Configure las variables de entorno
La configuración de variables de entorno en Windows agrega las ubicaciones de Spark y Hadoop a la RUTA de su sistema. Le permite ejecutar Spark shell directamente desde una ventana del símbolo del sistema.
1. Haga clic en Inicio y escriba entorno .
2. Seleccione el resultado etiquetado como Editar las variables de entorno del sistema .
3. Aparece un cuadro de diálogo Propiedades del sistema. En la esquina inferior derecha, haga clic en Variables de entorno y luego haga clic en Nuevo en la siguiente ventana.
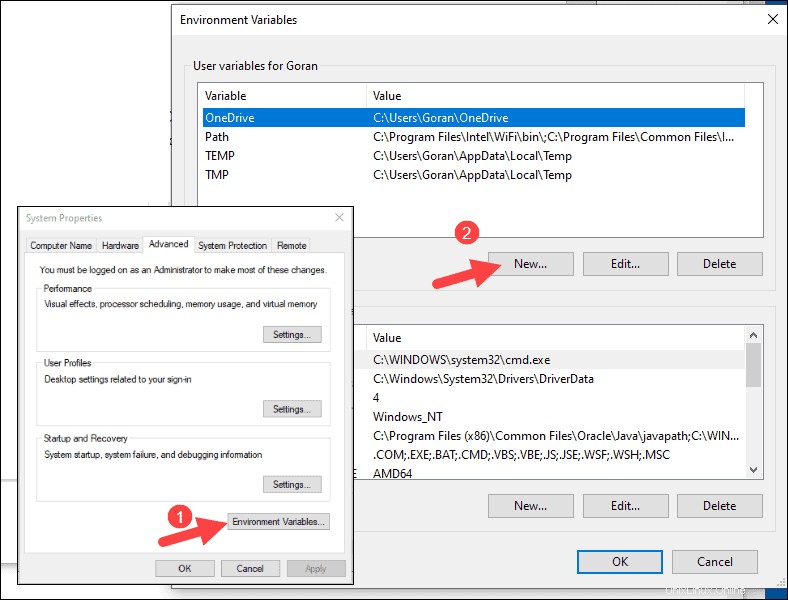
4. Para Nombre de variable escribe SPARK_HOME .
5. Para Valor de variable escribe C:\Spark\spark-2.4.5-bin-hadoop2.7 y haga clic en Aceptar. Si cambió la ruta de la carpeta, use esa en su lugar.
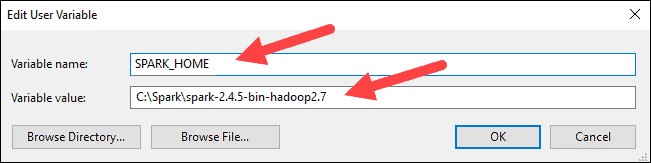
6. En el cuadro superior, haga clic en Ruta entrada, luego haga clic en Editar . Tenga cuidado al editar la ruta del sistema. Evite eliminar cualquier entrada que ya esté en la lista.
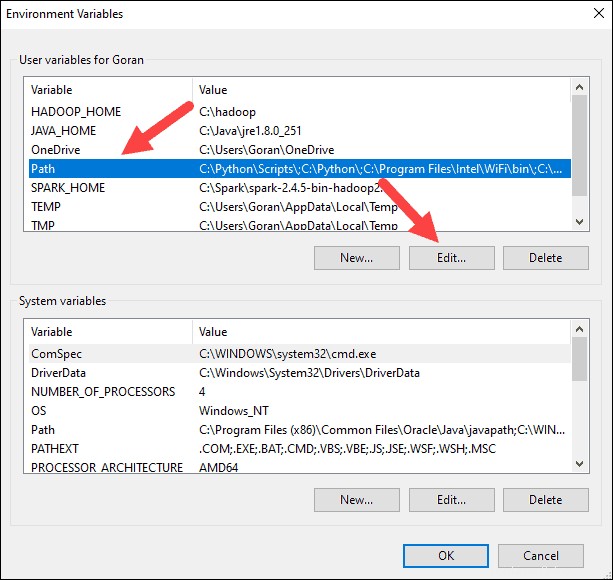
7. Debería ver un cuadro con entradas a la izquierda. A la derecha, haz clic en Nuevo .
8. El sistema resalta una nueva línea. Ingrese la ruta a la carpeta Spark C:\Spark\spark-2.4.5-bin-hadoop2.7\bin . Recomendamos usar %SPARK_HOME%\bin para evitar posibles problemas con la ruta.
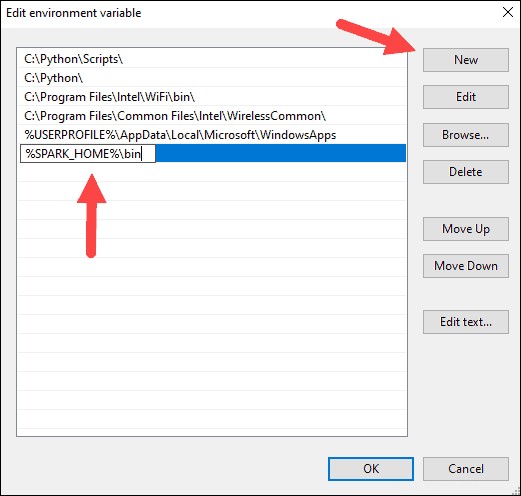
9. Repita este proceso para Hadoop y Java.
- Para Hadoop, el nombre de la variable es HADOOP_HOME y para el valor use la ruta de la carpeta que creó anteriormente:C:\hadoop. Agregar C:\hadoop\bin a la variable de ruta campo, pero recomendamos usar %HADOOP_HOME%\bin .
- Para Java, el nombre de la variable es JAVA_HOME y para el valor use la ruta a su directorio Java JDK (en nuestro caso es C:\Program Files\Java\jdk1.8.0_251 ).
10. Haga clic en Aceptar para cerrar todas las ventanas abiertas.
Paso 8:Inicie Spark
1. Abra una nueva ventana del símbolo del sistema haciendo clic con el botón derecho y Ejecutar como administrador. :
2. Para iniciar Spark, ingrese:
C:\Spark\spark-2.4.5-bin-hadoop2.7\bin\spark-shell
Si configura la ruta del entorno correctamente, puede escribir spark-shell para iniciar Spark.
3. El sistema deberá mostrar varias líneas indicando el estado de la solicitud. Es posible que obtenga una ventana emergente de Java. Selecciona Permitir acceso. para continuar.
Finalmente, aparece el logotipo de Spark y el aviso muestra el shell de Scala. .
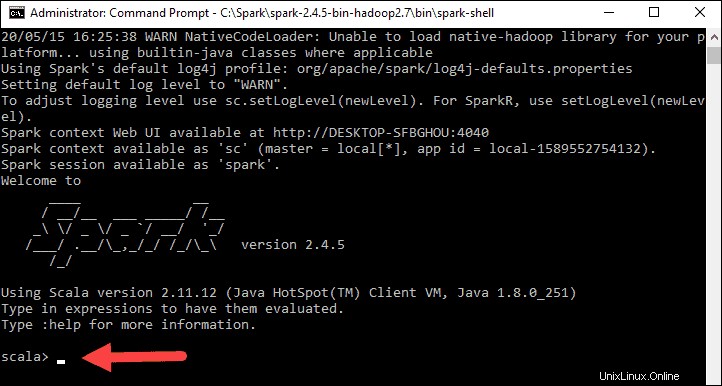
4. Abra un navegador web y vaya a http://localhost:4040/ .
5. Puede reemplazar localhost con el nombre de su sistema.
6. Debería ver una interfaz de usuario web de shell de Apache Spark. El siguiente ejemplo muestra los Ejecutores página.
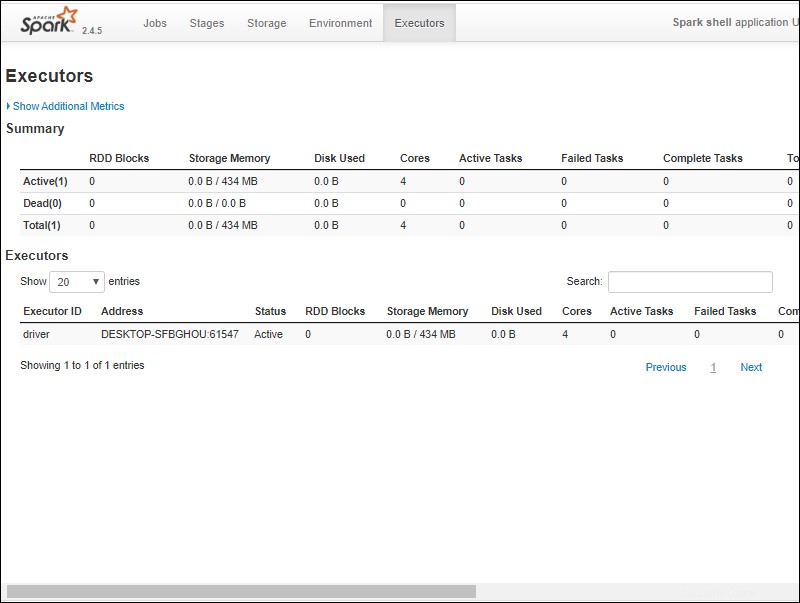
7. Para salir de Spark y cerrar el shell de Scala, presione ctrl-d en la ventana del símbolo del sistema.
Chispa de prueba
En este ejemplo, iniciaremos Spark Shell y usaremos Scala para leer el contenido de un archivo. Puede utilizar un archivo existente, como README archivo en el directorio de Spark, o puede crear uno propio. Creamos pnaptest con algo de texto.
1. Abra una ventana del símbolo del sistema y navegue hasta la carpeta con el archivo que desea usar e inicie Spark shell.
2. Primero, indique una variable para usar en el contexto de Spark con el nombre del archivo. Recuerde agregar la extensión del archivo si hay alguna.
val x =sc.textFile("pnaptest")3. El resultado muestra que se crea un RDD. Luego, podemos ver el contenido del archivo usando este comando para llamar a una acción:
x.take(11).foreach(println)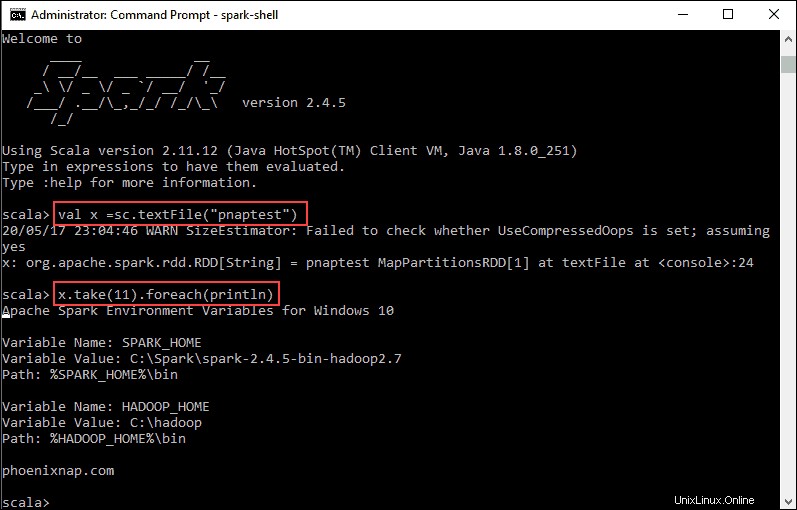
Este comando le indica a Spark que imprima 11 líneas del archivo que especificó. Para realizar una acción en este archivo (valor x ), agregue otro valor y y haz una transformación de mapa.
4. Por ejemplo, puede imprimir los caracteres al revés con este comando:
val y = x.map(_.reverse)5. El sistema crea un RDD hijo en relación con el primero. Luego, especifique cuántas líneas desea imprimir desde el valor y :
y.take(11).foreach(println)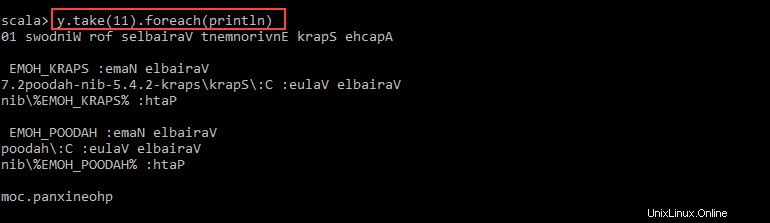
La salida imprime 11 líneas del pnaptest archivo en el orden inverso.
Cuando termine, salga del shell usando ctrl-d .