Introducción
La normalización de bases de datos es un método en el diseño de bases de datos relacionales que ayuda a organizar correctamente las tablas de datos. El proceso tiene como objetivo crear un sistema que represente fielmente la información y las relaciones sin pérdida de datos ni redundancia.
Este artículo explica la normalización de bases de datos y cómo normalizar una base de datos a través de un ejemplo práctico.

¿Qué es la normalización de bases de datos?
Normalización de bases de datos es una técnica para crear tablas de bases de datos con columnas y claves adecuadas al descomponer una tabla grande en unidades lógicas más pequeñas. El proceso también considera las demandas del entorno en el que reside la base de datos.
La normalización es un proceso iterativo. Comúnmente, la normalización de una base de datos ocurre a través de una serie de pruebas. Cada paso subsiguiente descompone las tablas en información más manejable, lo que hace que la base de datos general sea lógica y más fácil de trabajar.
¿Por qué es importante la normalización de la base de datos?
La normalización ayuda a un diseñador de bases de datos a distribuir de manera óptima los atributos en las tablas. La técnica elimina lo siguiente:
- Atributos con múltiples valores.
- Duplicado o repetido atributos.
- No descriptivo atributos.
- Atributos con redundancia información.
- Atributos creados a partir de otras características .
Aunque la normalización total de la base de datos no es necesaria, proporciona un entorno de información que funciona bien. El método asegura sistemáticamente:
- Una estructura de base de datos adecuado para consultas generalizadas.
- Redundancia de datos minimizada , aumentando la eficiencia de la memoria en un servidor de base de datos.
- Integridad de datos maximizada a través de las anomalías reducidas de inserción, actualización y eliminación.
La normalización de la base de datos transforma la coherencia general de la base de datos y proporciona un entorno eficiente.
Redundancias y anomalías de la base de datos
Al alterar una entidad en una tabla con redundancias , debe modificar todas las instancias repetidas de información y cualquier otra información relacionada con los datos modificados. De lo contrario, la base de datos se vuelve inconsistente y anomalías. ocurrir al hacer cambios.
Por ejemplo, en la siguiente tabla no normalizada:

La tabla contiene datos redundancia , que a su vez provoca tres anomalías al realizar cambios de datos:
1. Insertar anomalía . Al intentar insertar un nuevo empleado en el sector financiero, también debe saber el nombre del gerente. De lo contrario, no puede insertar datos en la tabla.
2. Anomalía de actualización. Si un empleado cambia de sector, el nombre del gerente termina siendo incorrecto. Por ejemplo, si Jacob cambia a finanzas, Adam permanece como su gerente.
3. Eliminar anomalía . Si Joshua decide dejar la empresa, al eliminar la fila también se elimina la información de que existe un sector financiero.
La solución a estas anomalías está en la normalización de bases de datos conceptos y pasos.
Conceptos de normalización de bases de datos
Los conceptos elementales utilizados en la normalización de bases de datos son:
- Teclas . Atributos de columna que identifican un registro de base de datos de forma única.
- Dependencias funcionales . Restricciones entre dos atributos en una relación.
- Formas normales . Pasos para lograr una cierta calidad de una base de datos.
Formas normales de base de datos
La normalización de una base de datos se logra a través de un conjunto de reglas conocidas como formas normales . El concepto central es ayudar a un diseñador de base de datos a lograr la calidad deseada de una base de datos relacional.
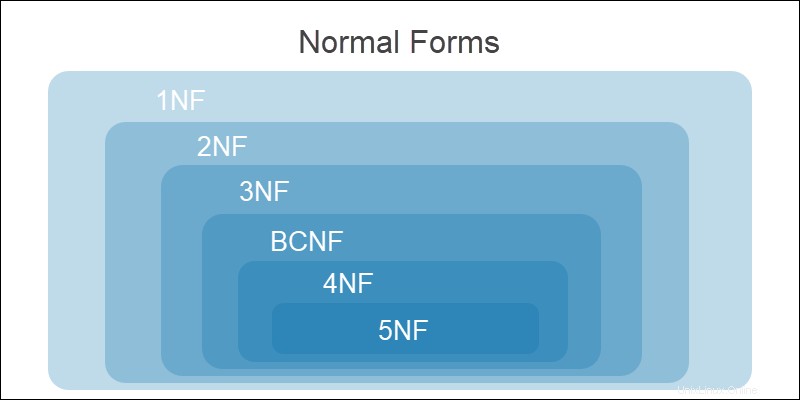
Todos los niveles de normalización son acumulativos. Se deben cumplir los requisitos de la forma normal anterior antes de pasar al siguiente formulario.
Las etapas de la normalización son:
| Escenario | Anomalías de redundancia solucionadas | |||||
|---|---|---|---|---|---|---|
| Forma no normalizada (UNF) | El estado antes de cualquier normalización. Los valores redundantes y complejos están presentes. | |||||
| Primera Forma Normal (1NF) | Los valores repetidos y complejos se dividen, haciendo que todas las instancias sean atómicas. | |||||
| Segunda Forma Normal (2FN) | Las dependencias parciales se descomponen en tablas nuevas. Todas las filas dependen funcionalmente de la clave principal. | |||||
| Tercera Forma Normal (3NF) | Las dependencias transitivas se descomponen en tablas nuevas. Los atributos no clave dependen de la clave principal. | |||||
| Forma normal de Boyce-Codd (BCNF) | Las dependencias funcionales parciales y transitivas para todas las claves candidatas se descomponen en nuevas tablas. | |||||
| Cuarta Forma Normal (4FN) | Eliminación de dependencias multivaluadas. | |||||
| Quinta Forma Normal (5NF) | Eliminación de dependencias JOIN. |

| ID de administrador | nombre del administrador | área | Id. de empleado | nombre del empleado | ID del sector | sectorName |
|---|---|---|---|---|---|---|
| 1 | Adam A. | Este | 1 2 | David D. Eugenio E. | 4 3 | Finanzas TI |
| 2 | Betty B. | Oeste | 3 4 5 | George G. henry h Ingrid I. | 2 1 4 | Seguridad Administración Finanzas |
| 3 | Carl C. | Norte | 6 7 | James J. Katy K. | 1 4 | Administración Finanzas |
| ID de administrador | nombre del administrador | área | Id. de empleado | nombre del empleado | ID del sector | sectorName |
|---|---|---|---|---|---|---|
| 1 | Adam A. | Este | 1 | David D. | 4 | Finanzas |
| 1 | Adam A. | Este | 2 | Eugene E. | 3 | TI |
| 2 | Betty B. | Oeste | 3 | George G. | 2 | Seguridad |
| 2 | Betty B. | Oeste | 4 | Henry H. | 1 | Administración |
| 2 | Betty B. | Oeste | 5 | Ingrid I. | 4 | Finanzas |
| 3 | Carl C. | Norte | 6 | James J. | 1 | Administración |
| 3 | Carl C. | Norte | 7 | Katy K. | 4 | Finanzas |
| ID de administrador | nombre del administrador | área | ||
|---|---|---|---|---|
| 1 | Adam A. | Este | ||
| 2 | Betty B. | Oeste | ||
| 3 | Carl C. | Norte |
| ID de empleado | nombre del empleado | ID de administrador | ID del sector | sectorName |
|---|---|---|---|---|
| 1 | David D. | 1 | 4 | Finanzas |
| 2 | Eugene E. | 1 | 3 | TI |
| 3 | George G. | 2 | 2 | Seguridad |
| 4 | Henry H. | 2 | 1 | Administración |
| 5 | Ingrid I. | 2 | 4 | Finanzas |
| 6 | James J. | 3 | 1 | Administración |
| 7 | Katy K. | 3 | 4 | Finanzas |
| ID de empleado | nombre del empleado | ID de administrador | ID del sector |
|---|---|---|---|
| 1 | David D. | 1 | 4 |
| 2 | Eugene E. | 1 | 3 |
| 3 | George G. | 2 | 2 |
| 4 | Henry H. | 2 | 1 |
| 5 | Ingrid I. | 2 | 4 |
| 6 | James J. | 3 | 1 |
| 7 | Katy K. | 3 | 4 |
| sectorID | sectorName |
|---|---|
| 1 | Administración |
| 2 | Seguridad |
| 3 | TI |
| 4 | Finanzas |
