En nuestro uso diario de los sistemas Linux/Unix, utilizamos muchas herramientas de línea de comandos para completar nuestro trabajo y comprender y administrar nuestros sistemas, herramientas como du para monitorear la utilización del disco y top para mostrar los recursos del sistema. Algunas de estas herramientas existen desde hace mucho tiempo. Por ejemplo, top fue lanzado por primera vez en 1984, mientras que du El primer lanzamiento de data de 1971.
A lo largo de los años, estas herramientas se han modernizado y adaptado a diferentes sistemas, pero, en general, siguen manteniendo su idea, apariencia y funcionamiento originales.
Estas son excelentes herramientas y esenciales para los flujos de trabajo de muchos administradores de sistemas. Sin embargo, en los últimos años, la comunidad de código abierto ha desarrollado herramientas alternativas que ofrecen beneficios adicionales. Algunos son solo atractivos para la vista, pero otros mejoran enormemente la usabilidad, lo que los convierte en una excelente opción para usar en sistemas modernos. Estos incluyen las siguientes cinco alternativas a las herramientas de línea de comandos estándar de Linux.
1. ncdu como reemplazo de du
El uso del disco de NCurses (ncdu ) proporciona resultados similares a du pero en una interfaz interactiva basada en curses que se enfoca en los directorios que consumen la mayor parte de su espacio en disco.
ncdu pasa algún tiempo analizando el disco, luego muestra los resultados ordenados por los directorios o archivos más usados, así:
ncdu 1.14.2 ~ Use the arrow keys to navigate, press ? for help
--- /home/rgerardi ------------------------------------------------------------
96.7 GiB [##########] /libvirt
33.9 GiB [### ] /.crc
7.0 GiB [ ] /Projects
. 4.7 GiB [ ] /Downloads
. 3.9 GiB [ ] /.local
2.5 GiB [ ] /.minishift
2.4 GiB [ ] /.vagrant.d
. 1.9 GiB [ ] /.config
. 1.8 GiB [ ] /.cache
1.7 GiB [ ] /Videos
1.1 GiB [ ] /go
692.6 MiB [ ] /Documents
. 591.5 MiB [ ] /tmp
139.2 MiB [ ] /.var
104.4 MiB [ ] /.oh-my-zsh
82.0 MiB [ ] /scripts
55.8 MiB [ ] /.mozilla
54.6 MiB [ ] /.kube
41.8 MiB [ ] /.vim
31.5 MiB [ ] /.ansible
31.3 MiB [ ] /.gem
26.5 MiB [ ] /.VIM_UNDO_FILES
15.3 MiB [ ] /Personal
2.6 MiB [ ] .ansible_module_generated
1.4 MiB [ ] /backgrounds
944.0 KiB [ ] /Pictures
644.0 KiB [ ] .zsh_history
536.0 KiB [ ] /.ansible_async
Total disk usage: 159.4 GiB Apparent size: 280.8 GiB Items: 561540
Navegue a cada entrada utilizando las teclas de flecha. Si presionas Entrar en una entrada de directorio, ncdu muestra el contenido de ese directorio:
--- /home/rgerardi/libvirt ----------------------------------------------------
/..
91.3 GiB [##########] /images
5.3 GiB [ ] /media
Puede usar eso para profundizar en los directorios y encontrar qué archivos consumen la mayor cantidad de espacio en disco. Regrese al directorio anterior usando el botón Izquierda Tecla de flecha. De forma predeterminada, puede eliminar archivos con ncdu presionando la d clave, y pide confirmación antes de eliminar un archivo. Si desea deshabilitar este comportamiento para evitar accidentes, use -r opción para acceso de solo lectura:ncdu -r .
ncdu está disponible para muchas plataformas y distribuciones de Linux. Por ejemplo, puede usar dnf para instalarlo en Fedora directamente desde los repositorios oficiales:
$ sudo dnf install ncdu
Puede encontrar más información sobre esta herramienta en ncdu página web.
2. htop como reemplazo de top
htop es un visor de procesos interactivo similar a top pero eso proporciona una mejor experiencia de usuario lista para usar. Por defecto, htop muestra las mismas métricas que top en una exhibición agradable y colorida.
Por defecto, htop se parece a esto:
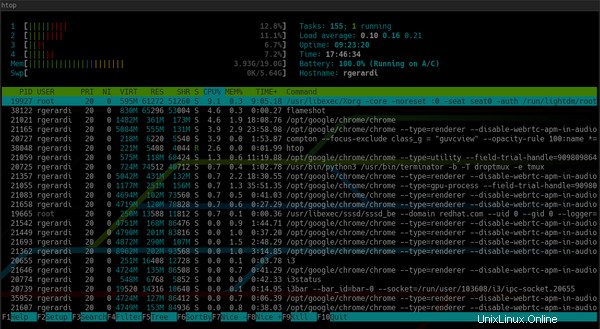
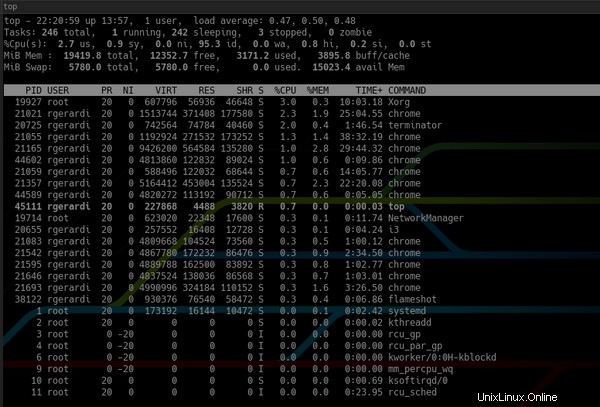
A diferencia del top predeterminado :
Además, htop proporciona información general del sistema en la parte superior y una barra de comandos en la parte inferior para activar comandos con las teclas de función, y puede personalizarla presionando F2 para entrar en la pantalla de configuración. En la configuración, puede cambiar sus colores, agregar o eliminar métricas o cambiar las opciones de visualización de la barra de información general.
Más recursos de Linux
- Hoja de trucos de los comandos de Linux
- Hoja de trucos de comandos avanzados de Linux
- Curso en línea gratuito:Descripción general técnica de RHEL
- Hoja de trucos de red de Linux
- Hoja de trucos de SELinux
- Hoja de trucos de los comandos comunes de Linux
- ¿Qué son los contenedores de Linux?
- Nuestros últimos artículos sobre Linux
Si bien puede configurar versiones recientes de top para lograr resultados similares, htop proporciona configuraciones predeterminadas más sensatas, lo que lo convierte en un visor de procesos agradable y fácil de usar.
Para obtener más información sobre este proyecto, consulte el htop página de inicio.
3. tldr como reemplazo de man
El tldr La herramienta de línea de comandos muestra información simplificada sobre la utilización de los comandos, que en su mayoría incluye ejemplos. Funciona como un cliente para el proyecto de páginas comunitarias tldr.
Esta herramienta no reemplaza a man . Las páginas del manual siguen siendo la fuente de información canónica y completa para muchas herramientas. Sin embargo, en algunos casos, man es demasiado. A veces no necesitas toda esa información sobre un comando; solo estás tratando de recordar las opciones básicas. Por ejemplo, la página del manual para curl El comando tiene casi 3.000 líneas. Por el contrario, el tldr para curl tiene 40 líneas y se ve así:
$ tldr curl
# curl
Transfers data from or to a server.
Supports most protocols, including HTTP, FTP, and POP3.
More information: <https://curl.haxx.se>.
- Download the contents of an URL to a file:
curl http://example.com -o filename
- Download a file, saving the output under the filename indicated by the URL:
curl -O http://example.com/filename
- Download a file, following [L]ocation redirects, and automatically [C]ontinuing (resuming) a previous file transfer:
curl -O -L -C - http://example.com/filename
- Send form-encoded data (POST request of type `application/x-www-form-urlencoded`):
curl -d 'name=bob' http://example.com/form
- Send a request with an extra header, using a custom HTTP method:
curl -H 'X-My-Header: 123' -X PUT http://example.com
- Send data in JSON format, specifying the appropriate content-type header:
curl -d '{"name":"bob"}' -H 'Content-Type: application/json' http://example.com/users/1234
... TRUNCATED OUTPUT
TLDR significa "demasiado largo; no leído", que es la jerga de Internet para un resumen de texto largo. El nombre es apropiado para esta herramienta porque las páginas man, aunque útiles, a veces son demasiado largas.
En Fedora, el tldr El cliente fue escrito en Python. Puedes instalarlo usando dnf . Para otras opciones de clientes consultar el proyecto de páginas tldr.
En general, el tldr La herramienta requiere acceso a Internet para consultar las páginas de tldr. El cliente de Python en Fedora le permite descargar y almacenar en caché estas páginas para acceder sin conexión.
Para obtener más información sobre tldr , puede usar tldr tldr .
4. jq como reemplazo de sed/grep para JSON
jq es un procesador JSON de línea de comandos. Es como sed o grep pero diseñado específicamente para tratar con datos JSON. Si es un desarrollador o administrador de sistemas que usa JSON en sus tareas diarias, esta es una herramienta esencial en su caja de herramientas.
El principal beneficio de jq sobre herramientas genéricas de procesamiento de texto como grep y sed es que comprende la estructura de datos JSON, lo que le permite crear consultas complejas con una sola expresión.
Para ilustrar, imagine que está tratando de encontrar el nombre de los contenedores en este archivo JSON:
{
"apiVersion": "v1",
"kind": "Pod",
"metadata": {
"labels": {
"app": "myapp"
},
"name": "myapp",
"namespace": "project1"
},
"spec": {
"containers": [
{
"command": [
"sleep",
"3000"
],
"image": "busybox",
"imagePullPolicy": "IfNotPresent",
"name": "busybox"
},
{
"name": "nginx",
"image": "nginx",
"resources": {},
"imagePullPolicy": "IfNotPresent"
}
],
"restartPolicy": "Never"
}
}
Si intenta grep directamente para name , este es el resultado:
$ grep name k8s-pod.json
"name": "myapp",
"namespace": "project1"
"name": "busybox"
"name": "nginx",
grep devolvió todas las líneas que contienen la palabra name . Puede agregar algunas opciones más a grep para restringirlo y, con alguna manipulación de expresiones regulares, puede encontrar los nombres de los contenedores. Para obtener el resultado que desea con jq , use una expresión que simule navegar por la estructura de datos, como esta:
$ jq '.spec.containers[].name' k8s-pod.json
"busybox"
"nginx"
Este comando le da el nombre de ambos contenedores. Si está buscando solo el nombre del segundo contenedor, agregue el índice del elemento de matriz a la expresión:
$ jq '.spec.containers[1].name' k8s-pod.json
"nginx"
Porque jq es consciente de la estructura de datos, proporciona los mismos resultados incluso si el formato del archivo cambia ligeramente. grep y sed puede proporcionar resultados diferentes con pequeños cambios en el formato.
jq tiene muchas características, y cubrirlas todas requeriría otro artículo. Para obtener más información, consulte el jq página del proyecto, las páginas del manual o tldr jq .
5. fd como reemplazo de find
fd es una alternativa simple y rápida al find dominio. No pretende reemplazar la funcionalidad completa find proporciona; en cambio, proporciona algunos valores predeterminados sensatos que ayudan mucho en ciertos escenarios.
Por ejemplo, al buscar archivos de código fuente en un directorio que contiene un repositorio de Git, fd excluye automáticamente los archivos y directorios ocultos, incluido el .git directorio, así como ignorar patrones del .gitignore expediente. En general, proporciona búsquedas más rápidas con resultados más relevantes en el primer intento.
Por defecto, fd ejecuta una búsqueda de patrón que no distingue entre mayúsculas y minúsculas en el directorio actual con salida en color. La misma búsqueda usando find requiere que proporcione parámetros de línea de comandos adicionales. Por ejemplo, para buscar todos los archivos de rebajas (.md o .MD ) en el directorio actual, el find el comando es este:
$ find . -iname "*.md"
Aquí está la misma búsqueda con fd :
$ fd .md
En algunos casos, fd requiere opciones adicionales; por ejemplo, si desea incluir archivos y directorios ocultos, debe usar la opción -H , mientras que esto no es necesario en find .
fd está disponible para muchas distribuciones de Linux. Instálelo en Fedora usando los repositorios estándar:
$ sudo dnf install fd-find
Para más información, consulte el fd repositorio de GitHub.
Excelentes alternativas junto con utilidades probadas
Si bien todavía uso todas las herramientas esenciales antiguas con regularidad, especialmente cuando me conecto de forma remota a los servidores, las herramientas alternativas brindan algunos beneficios adicionales que son valiosos en muchos escenarios. En particular, me ayudan a administrar y trabajar en mis equipos portátiles y de escritorio con Linux.
¿Utiliza alguna otra herramienta que ayude a su flujo de trabajo? Agrégalos en la sección de comentarios a continuación.