En esta guía, describiremos qué codificación de caracteres y cubriremos algunos ejemplos de cómo convertir archivos de una codificación de caracteres a otra utilizando una herramienta de línea de comandos. Finalmente, veremos cómo convertir varios archivos de cualquier conjunto de caracteres (charset ) a UTF-8 codificación en Linux.
Como probablemente ya tenga en mente, una computadora no entiende ni almacena letras, números o cualquier otra cosa que nosotros, como humanos, podamos percibir, excepto bits. Un bit tiene solo dos valores posibles, es decir, un 0 o 1 , true o false , yes o no . Todo lo demás, como letras, números e imágenes, debe representarse en bits para que una computadora lo procese.
En términos simples, codificación de caracteres es una forma de informar a una computadora cómo interpretar ceros y unos sin procesar en caracteres reales, donde un carácter está representado por un conjunto de números. Cuando escribimos texto en un archivo, las palabras y oraciones que formamos se elaboran a partir de diferentes caracteres, y los caracteres se organizan en un juego de caracteres .
Existen varios esquemas de codificación, como ASCII , ANSI , Unicode entre otros. A continuación se muestra un ejemplo de ASCII codificación.
Character bits A 01000001 B 01000010
En Linux, el iconv La herramienta de línea de comandos se utiliza para convertir texto de una forma de codificación a otra.
Puede verificar la codificación de un archivo usando el archivo comando, usando el -i o --mime indicador que permite la impresión de cadenas de tipo mime como en los ejemplos a continuación:
$ file -i Car.java $ file -i CarDriver.java


La sintaxis para usar iconv es el siguiente:
$ iconv option $ iconv options -f from-encoding -t to-encoding inputfile(s) -o outputfile
Donde -f o --from-code significa codificación de entrada y -t o --to-encoding especifica la codificación de salida.
Para enumerar todos los conjuntos de caracteres codificados conocidos, ejecute el siguiente comando:
$ iconv -l
Convertir archivos de codificación UTF-8 a ASCII
A continuación, aprenderemos cómo convertir de un esquema de codificación a otro. El siguiente comando convierte de ISO-8859-1 a UTF-8 codificación
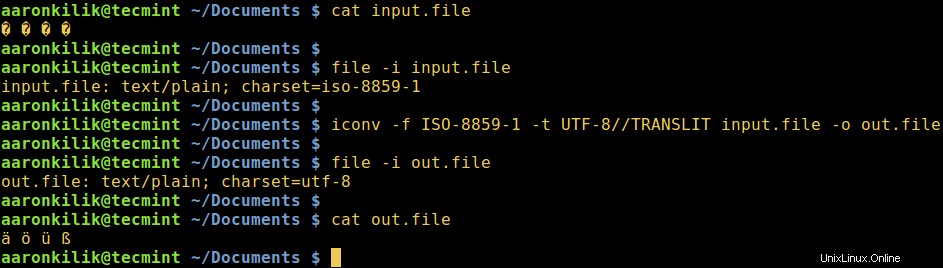
Considere un archivo llamado input.file que contiene los caracteres:
� � � �
Comencemos comprobando la codificación de los caracteres en el archivo y luego veamos el contenido del archivo. De cerca, podemos convertir todos los caracteres a ASCII codificación.
Después de ejecutar iconv comando, luego verificamos el contenido del archivo de salida y la nueva codificación de los caracteres como se muestra a continuación.
$ file -i input.file $ cat input.file $ iconv -f ISO-8859-1 -t UTF-8//TRANSLIT input.file -o out.file $ cat out.file $ file -i out.file
Nota :En caso de que la cadena //IGNORE se agrega a la codificación, caracteres que no se pueden convertir y se muestra un error después de la conversión.
De nuevo, suponiendo que la cadena //TRANSLIT se agrega a la codificación como en el ejemplo anterior (ASCII//TRANSLIT ), los caracteres que se convierten se transliteran según sea necesario y si es posible. Lo que implica que, en el caso de que un personaje no se pueda representar en el conjunto de caracteres de destino, se puede aproximar a través de uno o más caracteres de aspecto similar.
En consecuencia, cualquier carácter que no se pueda transliterar y no esté en el conjunto de caracteres de destino se reemplaza con un signo de interrogación (?) en la salida.
Convertir múltiples archivos a codificación UTF-8
Volviendo a nuestro tema principal, para convertir múltiples o todos los archivos en un directorio a la codificación UTF-8, puede escribir un pequeño script de shell llamado encoding.sh de la siguiente manera:
#!/bin/bash
#enter input encoding here
FROM_ENCODING="value_here"
#output encoding(UTF-8)
TO_ENCODING="UTF-8"
#convert
CONVERT=" iconv -f $FROM_ENCODING -t $TO_ENCODING"
#loop to convert multiple files
for file in *.txt; do
$CONVERT "$file" -o "${file%.txt}.utf8.converted"
done
exit 0
Guarde el archivo, luego haga que el script sea ejecutable. Ejecútelo desde el directorio donde se encuentran sus archivos (*.txt ) se encuentran.
$ chmod +x encoding.sh $ ./encoding.sh
Importante :También puede usar este script para la conversión general de múltiples archivos de una codificación dada a otra, simplemente juegue con los valores de FROM_ENCODING y TO_ENCODING variable, sin olvidar el nombre del archivo de salida "${file%.txt}.utf8.converted" .
Para obtener más información, consulta el iconv página man.
$ man iconv
Para resumir esta guía, comprender la codificación y cómo convertir de un esquema de codificación de caracteres a otro es un conocimiento necesario para todos los usuarios de computadoras, más aún para los programadores cuando se trata de manejar texto.
Por último, puede ponerse en contacto con nosotros utilizando la sección de comentarios a continuación para cualquier pregunta o comentario.