Interfaz gráfica de usuario Los procesadores de texto y las aplicaciones para tomar notas tienen información o indicadores detallados para los detalles del documento, como el recuento de páginas. , palabras y caracteres , una lista de encabezados en procesadores de texto, una tabla de contenido en algunos editores de rebajas, etc. y encontrar la ocurrencia de palabras o frases es tan fácil como presionar Ctrl + F y escribiendo los caracteres que desea buscar.
Una GUI hace que todo sea fácil, pero ¿qué sucede cuando solo puede trabajar desde la línea de comando y desea verificar la cantidad de veces que aparece una palabra, frase o carácter en un archivo de texto? Es casi tan fácil como cuando se usa una GUI, siempre y cuando tengas el comando correcto y estoy a punto de contarte cómo se hace.
Suponga que tiene un example.txt archivo que contiene las oraciones:
Praesent in mauris eu tortor porttitor accumsan. Mauris suscipit, ligula sit amet pharetra semper, nibh ante cursus purus, vel sagittis velit mauris vel metus enean fermentum risus.
Puede usar el comando grep para contar la cantidad de veces "mauris" aparece en el archivo como se muestra.
$ grep -o -i mauris example.txt | wc -l
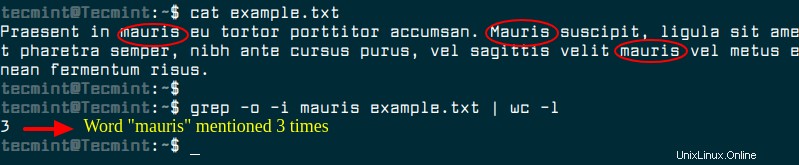
Usando grep -c solo contará el número de líneas que contienen la palabra coincidente en lugar del número total de coincidencias. El -o La opción es lo que le dice a grep que genere cada coincidencia en una línea única y luego wc -l le dice a wc que cuente el número de líneas. Así es como se deduce el número total de palabras coincidentes.
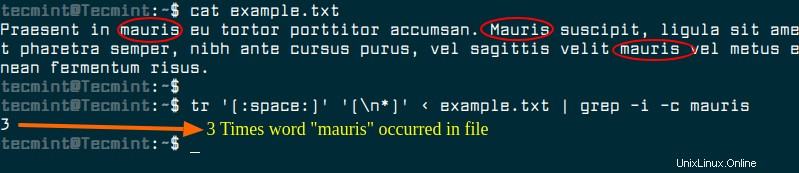
Un enfoque diferente es transformar el contenido del archivo de entrada con el comando tr para que todas las palabras estén en una sola línea y luego usar grep -c para contar ese recuento de coincidencias.
$ tr '[:space:]' '[\n*]' < example.txt | grep -i -c mauris
¿Es así como verificaría la ocurrencia de palabras desde su terminal? Comparta su experiencia con nosotros y háganos saber si tiene otra forma de realizar la tarea.