Algunas empresas no pueden permitir que sus servicios no funcionen. En caso de una interrupción del servidor, un operador celular podría experimentar un tiempo de inactividad del sistema de facturación que provocaría la pérdida de conexión para todos sus clientes. Admitir el impacto potencial de tales situaciones lleva a la idea de tener siempre un plan B.
En este artículo, arrojamos luz sobre diferentes formas de protección contra fallas del servidor, así como arquitecturas utilizadas para la implementación de VMmanager Cloud, un panel de control para construir un clúster de alta disponibilidad.

Prefacio
La terminología en el área de la tolerancia de agrupamiento difiere de un sitio web a otro. Para evitar mezclar diferentes términos y definiciones, describamos los que se utilizarán en el artículo dado:
- Fault Tolerance (FT) es la capacidad de un sistema para continuar su funcionamiento después de la falla de uno de sus componentes.
- Cluster es un grupo de servidores (nodos de clúster) conectados a través de canales de comunicación.
- El clúster tolerante a fallas (FTC) es un clúster en el que la falla de un servidor no provoca la indisponibilidad total de todo el clúster. Las funciones del nodo fallido se reasignan automáticamente entre los nodos restantes.
- Disponibilidad continua (CA) significa que un usuario puede utilizar el servicio sin experimentar tiempos de espera. No importa cuánto tiempo haya pasado desde que falló el nodo.
- Alta disponibilidad (HA) significa que un usuario puede experimentar tiempos de espera de servicio en caso de que uno de los nodos se caiga; sin embargo, el sistema se recuperará automáticamente con un tiempo de inactividad mínimo.
- El clúster de CA es un clúster de disponibilidad continua.
- El clúster HA es un clúster de alta disponibilidad.
Que sea necesario implementar un clúster que consta de 10 nodos con máquinas virtuales ejecutándose en cada nodo. El objetivo es proteger las máquinas virtuales después de la falla del servidor. Los servidores de doble CPU se utilizan para maximizar la densidad de cálculo de los bastidores.
A primera vista, la opción más atractiva para una empresa es implementar un clúster de disponibilidad continua cuando un servicio todavía se aprovisiona después de que el equipo haya fallado. De hecho, la disponibilidad continua es imprescindible si necesita mantener el funcionamiento de un sistema de facturación o automatizar un proceso de producción continuo. Sin embargo, este enfoque también tiene sus trampas y escollos que se tratan a continuación.
Disponibilidad continua
La continuidad de un servicio solo es factible si se construye una copia exacta de una máquina física o virtual con este servicio, que esté disponible en cada momento. Tal modelo de redundancia se llama 2N. La creación de una copia del servidor después de que el equipo fallara llevaría tiempo, lo que provocaría un tiempo de espera del servicio. Además, en este caso, no sería posible recuperar el volcado de RAM del servidor fallido, lo que significa que toda la información contenida allí desaparecería.
Se utilizan dos métodos para proporcionar CA:en una capa de hardware y otra de software. Centrémonos en cada uno de ellos con mayor detalle.
El método del hardware representa un servidor doble donde todos los componentes se duplican y los cálculos se ejecutan de forma simultánea e independiente. La sincronización se logra mediante el uso de un nodo dedicado que verifica los resultados provenientes de ambas partes. Si el nodo detecta alguna discrepancia, intenta definir el problema y corregir los errores. Si el error no se puede solucionar, el sistema apaga el módulo defectuoso.
Stratus, un fabricante de servidores CA, garantiza que el tiempo de inactividad general del sistema no supera los 32 segundos por año. Estos resultados se pueden lograr mediante el uso de equipos especiales. Según los representantes de Stratus, el costo de un servidor CA con CPU dual para cada módulo sincronizado es de alrededor de $160 000, según las especificaciones. El precio extendido para todo el clúster de CA en este caso sería de $1 600 000.
El método del software
La herramienta de software más popular para la implementación de un clúster de disponibilidad continua en el momento de este artículo es VMware vSphere. La tecnología de disponibilidad continua de este producto se denomina Fault Tolerance.
A diferencia del método de hardware, esta tecnología tiene ciertos requisitos, como los siguientes:
- CPU en el host físico:
- Intel con arquitectura Sandy Bridge (o más reciente). Avoton no es compatible.
- Excavadora AMD (o más reciente).
- Las máquinas con Fault Tolerance deben conectarse a una red de 10 Gb con baja latencia. VMware recomienda enfáticamente usar una red dedicada.
- No más de 4 CPU virtuales por VM.
- No más de 8 CPU virtuales por host físico.
- No más de 4 máquinas virtuales por host físico.
- Las instantáneas de máquinas virtuales no están disponibles.
- El almacenamiento vMotion no está disponible.
La lista completa de limitaciones e incompatibilidades se puede encontrar en la documentación oficial.
Las licencias de vSphere se basan en CPU físicas. El precio comienza en $1750 por licencia + $550 por suscripción anual y soporte. La automatización de la administración de clústeres también requiere VMware vCenter Server, que cuesta más de $8000. El modelo 2N se utiliza para proporcionar Disponibilidad Continua, por lo que se requiere comprar 10 servidores replicados con licencias para cada uno de ellos para construir un clúster de 10 nodos con máquinas virtuales.
El costo total del software sería 2[Número de CPU por servidor]*(10[Número de nodos con máquinas virtuales]+10[Número de nodos replicados])*(1750+550)[Costo de licencia por cada CPU]+8000 [Coste de VMware vCenter Server]=$100 000. Todos los precios están redondeados.
Las configuraciones de nodos específicos no se describen en este artículo, ya que los componentes del servidor siempre difieren según el propósito del clúster. Tampoco se describe el equipo de red, ya que debería ser idéntico en todos los casos. Este artículo se centra en aquellos componentes que definitivamente variarían, que es el costo de la licencia.
También es importante mencionar los productos que ya no se desarrollan ni reciben soporte.
El producto llamado Remus se basa en la virtualización Xen. Es una solución gratuita de código abierto que utiliza la tecnología de microinstantáneas. Desafortunadamente, su documentación no se ha actualizado durante mucho tiempo:la guía de instalación proporciona instrucciones para Ubuntu 12.10 cuyo fin de vida se anunció en 2014. Incluso la búsqueda de Google no encontró ninguna empresa que estuviera usando Remus para sus operaciones.
Se hicieron intentos de modificar QEMU para crear clústeres de disponibilidad continua en esta tecnología. Hay dos proyectos que anunciaron su trabajo en esta dirección.
El primero es Kemari, un producto de código abierto liderado por Yoshiaki Tamura. Este proyecto pretendía utilizar la migración QEMU en vivo. La última confirmación se realizó en febrero de 2011, lo que sugiere que el desarrollo llegó a un punto muerto y no continuará.
El segundo producto es Micro Checkpointing, un proyecto de código abierto fundado por Michael Hines. No se ha encontrado actividad en su registro de cambios durante el último año, lo que se parece al proyecto Kemari.
Estos hechos nos permiten llegar a la conclusión de que, hasta la fecha, simplemente no existe la posibilidad de disponibilidad continua en la virtualización KVM.
A pesar de todas las ventajas de los sistemas de disponibilidad continua, existen muchos impedimentos en la forma de implementar y operar tales soluciones. Sin embargo, en algunos casos se puede requerir Fault Tolerance pero sin necesidad de estar disponible continuamente. Dichos escenarios permiten el uso de clústeres con alta disponibilidad.
Alta disponibilidad
Un clúster de alta disponibilidad proporciona tolerancia a fallas al detectar automáticamente si el hardware está inactivo y, posteriormente, iniciar el servicio en el nodo disponible.
La alta disponibilidad no admite la sincronización de las CPU iniciadas en los nodos y no siempre permite sincronizar discos locales. Con esto en mente, se recomienda ubicar las unidades utilizadas por los nodos en un almacenamiento independiente separado, como el almacenamiento en red.
El motivo es claro:no se puede acceder al nodo después de su falla y no se puede recuperar la información de su dispositivo de almacenamiento. El sistema de almacenamiento de datos también debe ser tolerante a fallas; de lo contrario, no hay posibilidad de alta disponibilidad. Como resultado, el clúster de alta disponibilidad consta de dos subclústeres:
- Clúster de computación que consta de nodos con máquinas virtuales
- Clúster de almacenamiento con discos que utilizan los nodos informáticos.
Actualmente existen las siguientes soluciones utilizadas para implementar clústeres de alta disponibilidad con máquinas virtuales en los nodos del clúster:
- Heartbeat, versión 1.? con DRBD;
- Marcapasos;
- VMware vSphere;
- Proxmox VE;
- XenServer;
- OpenStack;
- oVirt;
- Red Hat Enterprise Virtualización;
- Clústeres de conmutación por error de Windows Server con función de servidor Hyper-V;
- Nube de VMmanager.
Echemos un vistazo más de cerca a VMmanager Cloud.
VMmanager en la nube
VMmanager Cloud es un producto que permite implementar clústeres de alta disponibilidad y utiliza la virtualización QEMU-KVM. Se seleccionó esta tecnología porque está activamente desarrollada y soportada y permite instalar cualquier sistema operativo en una máquina virtual. El producto utiliza Corosync para detectar la disponibilidad del clúster. Si uno de los servidores está inactivo, VMmanager distribuye sus máquinas virtuales entre los nodos restantes uno por uno.
En la forma simplificada este mecanismo funciona de la siguiente manera:
- El sistema identifica el nodo del clúster con la menor cantidad de máquinas virtuales.
- Comprueba si hay suficiente RAM para ubicar la máquina.
- Si hay suficiente memoria en un nodo para la máquina pertinente, VMmanager crea una nueva máquina virtual en este nodo.
- Si no hay suficiente memoria, el sistema verifica los otros nodos con más máquinas virtuales.
La prueba de algunas configuraciones de hardware y la consulta de muchos usuarios actuales de VMmanager Cloud identificaron que normalmente se tarda entre 45 y 90 segundos en distribuir y restaurar el funcionamiento de todas las máquinas virtuales desde el nodo fallido, según el rendimiento del equipo.
Se recomienda dedicar uno o varios nodos como protección contra situaciones de emergencia y no implementar máquinas virtuales en estos nodos durante la operación de rutina. Minimiza las posibilidades de falta de recursos en los nodos de clúster en vivo para agregar máquinas virtuales desde el nodo fallido. En caso de que solo se utilice un nodo de respaldo, dicho modelo de seguridad se denomina N+1.
VMmanager Cloud admite los siguientes tipos de almacenamiento:sistema de archivos, LVM, Network LVM, iSCSI y Ceph [en particular, RBD (RADOS Block Device), una de las implementaciones de Ceph]. Los tres últimos se utilizan para alta disponibilidad.
Una licencia de por vida para diez nodos operativos y un nodo de copia de seguridad cuesta 3520 €, o 3865 $ hasta la fecha (una licencia cuesta 320 € por nodo, independientemente del número de CPU). La licencia incluye un año de actualizaciones gratuitas; a partir del segundo año se proporcionan actualizaciones por modelo de suscripción al precio de 880 € al año para todo el clúster.
Veamos cómo se ha utilizado VMmanager Cloud para la implementación de clústeres de alta disponibilidad.
PrimerByte
FirstByte comenzó a proporcionar alojamiento en la nube en febrero de 2016. Inicialmente, su clúster se creó en OpenStack; sin embargo, la falta de especialistas para este sistema, tanto en su disponibilidad como en su costo, los impulsó a buscar una solución alternativa. El nuevo sistema para crear un clúster de alta disponibilidad debía cumplir los siguientes requisitos:
- Capacidad para implementar máquinas virtuales KVM.
- Integración con Ceph.
- Integración con un sistema de facturación para ofrecer los servicios existentes.
- Costo de licencia asequible.
- Apoyo del desarrollador de software.
VMmanager Cloud cumple con todos los requisitos.
Características distintivas del clúster FirstByte:
- La transferencia de datos se basa en tecnología Ethernet y equipos de Cisco.
- El enrutamiento se realiza mediante Cisco ASR9001. El clúster utiliza alrededor de 50 000 direcciones IPv6.
- La velocidad de enlace entre los nodos informáticos y los conmutadores es de 10 Gbps.
- La velocidad de transferencia de datos entre conmutadores y nodos de almacenamiento es de 20 Gbps, con dos canales combinados de 10 Gbps cada uno.
- Se utiliza un enlace independiente de 20 Gbps entre bastidores con nodos de almacenamiento para la replicación.
- Los discos SAS en combinación con SSD están instalados en todos los nodos de almacenamiento.
- El tipo de almacenamiento es RBD.
El diseño del sistema se presenta a continuación:
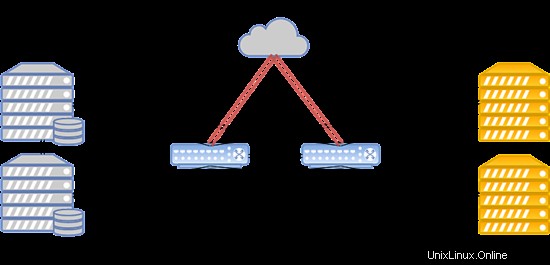
Esta configuración funciona para alojar sitios web populares, servidores de juegos y bases de datos con una carga superior a la media.
PrimerVDS
FirstVDS proporciona los servicios del clúster tolerante a fallas que se inició en septiembre de 2015.
Se eligió VMmanager Cloud para este clúster debido a los siguientes factores:
- Experiencia sólida en el uso de paneles de control del sistema ISP.
- Integración con BILLmanager por defecto.
- Soporte técnico de alta calidad.
- Integración con Ceph.
Su grupo tiene las siguientes características:
- La transferencia de datos se basa en la red Infiniband con una velocidad de conexión de 56 Gbps;
- La red Infiniband se basa en equipos Mellanox;
- Los nodos de almacenamiento tienen unidades SSD;
- El tipo de almacenamiento es RBD.
El sistema se puede diseñar de la siguiente manera:
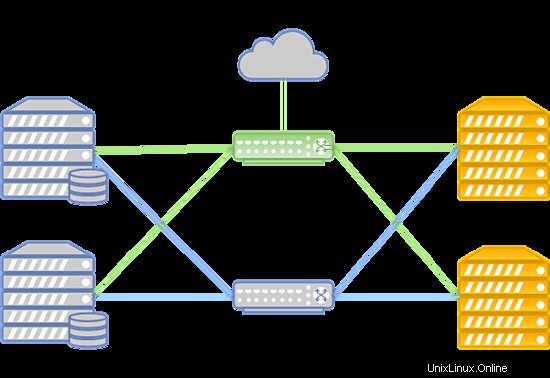
En caso de falla de la red Infiniband, la conexión entre el almacenamiento en disco de la VM y los servidores informáticos se establece a través de la red Ethernet implementada en el equipo Juniper. La nueva conexión se configura automáticamente.
Debido a la alta velocidad de comunicación con el almacenamiento, este clúster funciona a la perfección para alojar sitios web con tráfico muy alto, transmisión de video y contenido, así como big data.
Conclusión
Resumamos los hallazgos clave del artículo.
El clúster de disponibilidad continua es imprescindible cuando cada segundo de tiempo de inactividad genera pérdidas sustanciales. Si se permite una interrupción de 5 minutos mientras se implementan las máquinas virtuales en un nodo de respaldo, el clúster de alta disponibilidad puede ser una buena opción para reducir los costos de hardware y software.
También es importante recordar que la única forma de lograr Fault Tolerance es el exceso. Asegúrese de replicar sus servidores, equipos y enlaces de comunicación de datos, canales de acceso a Internet y alimentación. Replica todo lo que puedas. Estas medidas permiten eliminar los cuellos de botella y los posibles puntos de falla que pueden causar tiempos de inactividad de todo el sistema. Al tomar las medidas anteriores, puede estar seguro de que tiene un clúster tolerante a fallas resistente a fallas.
Si cree que el modelo de alta disponibilidad se ajusta a sus requisitos y VMmanager Cloud es una buena herramienta para realizarlo, consulte el manual de instalación y la documentación para obtener más información sobre el sistema. yo ¡Le deseamos operaciones continuas y sin fallas!