Al descargar archivos, no es raro ver el .tar , .zip o .gz extensiones Pero, ¿conoces la diferencia entre Tar, Zip y Gz? ¿Por qué los usamos y cuál es más eficiente, tar o zip o gz?
Diferencia entre tar, zip y gz
Si tiene prisa o simplemente quiere obtener algo fácil de recordar, esta es la diferencia entre zip, tar y gz:
.tar ==archivo de almacenamiento sin comprimir
.zip ==(generalmente) archivo de almacenamiento comprimido
.gz ==archivo (archivo o no) comprimido con gzip

Un poco de historia de los archivos comprimidos
Como muchas cosas sobre Unix y los sistemas similares a Unix, la historia comienza hace mucho, mucho tiempo, en una galaxia no muy lejana llamada los años setenta. En una fría mañana de enero de 1979, el tar La utilidad hizo su aparición como parte del nuevo Unix V7.
El tar La utilidad fue diseñada como una forma de escribir eficientemente muchos archivos en cintas. Incluso si hoy en día las unidades de cinta son desconocidas para la gran mayoría de los usuarios individuales de Linux, tarballs — el apodo de tar archivos:todavía se usan comúnmente para empaquetar varios archivos o incluso un árbol de directorios completo (o incluso bosques) en un solo archivo.
Una cosa clave para recordar es un alquitrán simple el archivo es solo un archivo cuyos datos no están comprimidos. En otras palabras, si tar 100 archivos de 50kB, terminará con un archivo cuyo tamaño rondará los 5000kB. La única ganancia que puede esperar usando tar solo sería evitar el espacio desperdiciado por el sistema de archivos, ya que la mayoría de ellos asignan espacio con cierta granularidad (por ejemplo, en mi sistema, un archivo de un byte de longitud usa 4kB de espacio en disco, 1000 de ellos usarán 4 MB pero el archivo tar correspondiente "solo" 1 MB).
| Vale la pena mencionar aquí tar Ciertamente no es la única herramienta estándar de Unix para crear archivos. Los programadores probablemente saben ar ya que se usa principalmente hoy en día para crear bibliotecas estáticas, que no son más que archivos de compilados archivos Pero ar se puede utilizar para crear archivos de cualquier tipo. De hecho, .deb los archivos de paquete utilizados en los sistemas Debian son ar ¡archivo! Y en Mac OS X, mpkg los paquetes están (¿eran?) comprimidos con gzip cpio archivo. Dicho esto, ni ar ni cpio ganó tanta popularidad como tar entre los usuarios. Tal vez porque el comando tar era lo suficientemente bueno y más simple de usar. |

Crear archivos es bueno. Pero con el paso del tiempo, y con el advenimiento de la era de las computadoras personales, las personas se dieron cuenta de que podían ahorrar mucho en almacenamiento al comprimir datos. Entonces, una década después de la introducción o tar , código postal apareció en el mundo de MS-DOS como un formato de archivo compatible con la compresión . El esquema de compresión más común para zip es desinflar que en sí mismo es una implementación del algoritmo LZ77. Pero siendo desarrollado comercialmente por PKWARE, el zipp El formato ha sufrido el gravamen de patentes durante años.
Entonces, en paralelo, gzip fue creado para implementar el algoritmo LZ77 en un software libre sin violar ninguna patente de PKWARE.
Un elemento clave de la filosofía de Unix es "Haz una cosa y hazla bien" , gzip fue diseñado para solo comprimir archivos. Entonces, para crear un archivo comprimido , primero debe crear un archivo usando el tar utilidad por ejemplo. Y después de eso, comprimirás ese archivo. Este es un .tar.gz archivo (a veces abreviado como .tgz para agregar nuevamente a esa confusión, y para cumplir con las limitaciones de nombre de archivo 8.3 MS-DOS olvidadas hace mucho tiempo).
A medida que la informática evolucionó, se diseñaron otros algoritmos de compresión para una relación de compresión más alta. Por ejemplo, el algoritmo Burrows–Wheeler implementado en bzip2 (que lleva a .tar.bz2 archivo). O más recientemente xz que es un LZMA implementación de algoritmo similar a la utilizada en el 7zip utilidad.
Disponibilidad y limitaciones
Hoy puedes usar libremente cualquier formato de archivo tanto en Linux como en Windows.
Pero como el zip El formato es compatible de forma nativa en Windows, este está especialmente presente en entornos multiplataforma. Incluso puedes encontrar el zip formato de archivo en lugares inesperados. Por ejemplo, Sun conservó ese formato de archivo para JAR archivos utilizados para distribuir aplicaciones Java compiladas. O para archivos OpenDocument (.odf , .odp …) utilizado por LibreOffice u otras suites ofimáticas. Todos esos formatos de archivos son archivos zip disfrazados. Si tienes curiosidad, no dudes en descomprimir uno de ellos para ver lo que hay dentro:
sh$ unzip some-file.odt
Archive:some-file.odt
extracting: mimetype
inflating: meta.xml
inflating: settings.xml
inflating: content.xm
[...]
inflating: styles.xml
inflating: META-INF/manifest.xml
Dicho todo esto, en el mundo similar a Unix, yo seguiría favoreciendo tar tipo de archivo porque el zip El formato de archivo no es compatible con todos los metadatos del sistema de archivos Unix de manera confiable. Para obtener algunas explicaciones concretas de esa última declaración, debe saber que el formato de archivo ZIP solo define un pequeño conjunto de atributos de archivo obligatorios para almacenar para cada entrada:nombre de archivo, fecha de modificación, permisos. Más allá de esos atributos básicos, un archivador puede almacenar metadatos adicionales en el llamado campo adicional del encabezado ZIP. Pero, dado que los campos adicionales están definidos por la implementación, no hay garantías, ni siquiera para los archivadores compatibles, de almacenar o recuperar el mismo conjunto de metadatos. Comprobemos eso en un archivo de muestra:
sh$ ls -lsn data/team
total 0
0 -rw-r--r-- 1 1000 2000 0 Jan 30 12:29 team
sh$ zip -0r archive.zip data/
sh$ zipinfo -v archive.zip data/team
Central directory entry #5:
---------------------------
data/team
[...]
apparent file type: binary
Unix file attributes (100644 octal): -rw-r--r--
MS-DOS file attributes (00 hex): none
The central-directory extra field contains:
- A subfield with ID 0x5455 (universal time) and 5 data bytes.
The local extra field has UTC/GMT modification/access times.
- A subfield with ID 0x7875 (Unix UID/GID (any size)) and 11 data bytes:
01 04 e8 03 00 00 04 d0 07 00 00.
Como puede ver, la información de propiedad (UID/GID) es parte del campo adicional; puede que no sea obvio si no conoce el hexadecimal, ni los metadatos ZIP. se almacenan en little-endian, pero para abreviar "e803" es "03e8" con "1000", el UID del archivo. Y “07d0” es “d007” que es 2000, el archivo GID.
En ese caso particular, el Info-ZIP zip La herramienta disponible en mi sistema Debian almacenó algunos metadatos útiles en el campo adicional. Pero no hay garantía de que cada archivador escriba este campo adicional. E incluso si está presente, no hay garantía de que esto sea entendido por la herramienta utilizada para extraer el archivo.
Mientras que no podemos rechazar la tradición como una motivación para seguir usando tarballs , con este pequeño ejemplo, entiendes por qué todavía hay algunos (¿esquinas?) Casos donde tar no puede ser reemplazado por zip . Esto es especialmente cierto cuando desea conservar todas metadatos de archivo estándar.
Prueba de eficiencia Tar vs Zip vs Gz
Hablaré aquí sobre la eficiencia del espacio, no de la eficiencia del tiempo, pero como regla general, más potencialmente eficiente es un algoritmo de compresión, requiere más CPU.
Y para darle una idea de la relación de compresión obtenida usando diferentes algoritmos, he reunido en mi disco duro alrededor de 100 MB de archivos de formatos de archivo populares. Estos son los resultados obtenidos en mi sistema Debian Stretch (todos los tamaños según lo informado por du -sh ):
| tipo de archivo | .jpg | .mp3 | .mp4 | .odt | .png | .txt |
| número de archivos | 2163 | 45 | 279 | 2990 | 2072 | 4397 |
| espacio en disco | 98M | 99M | 99M | 98M | 98M | 98M |
| tar | 94M | 99M | 98M | 93M | 92M | 89M |
| zip (sin compresión) | 92M | 99M | 98M | 91M | 91M | 86M |
| zip (desinflar) | 87M | 98M | 93M | 85M | 77M | 28M |
| tar + gzip | 86M | 98M | 93M | 82M | 77M | 27M |
| tar + bz2 | 87M | 98M | 93M | 42M | 71M | 22M |
| tar + xz | 70M | 98M | 22M | 348K | 51M | 19M |
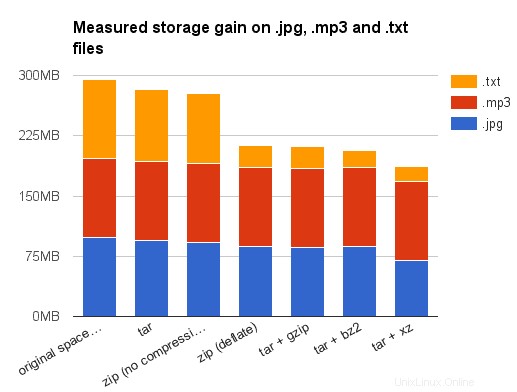 Primero, lo animo a tomar esos resultados con cautela:los archivos de datos eran en realidad archivos colgados en mi disco duro, y no los reclamaría como representativos de ninguna manera. Entonces, debo confesar que no elegí esos tipos de archivos al azar. Ya lo he dicho, .odt los archivos ya son archivos zip. Por lo tanto, la modesta ganancia obtenida al comprimirlos por segunda vez no es sorprendente (excepto bzip2 o xy, pero yo lo haría considere eso como una anomalía estadística causada por la baja heterogeneidad de mis archivos de datos, que contienen varias copias de seguridad o versiones de trabajo de los mismos documentos).
Primero, lo animo a tomar esos resultados con cautela:los archivos de datos eran en realidad archivos colgados en mi disco duro, y no los reclamaría como representativos de ninguna manera. Entonces, debo confesar que no elegí esos tipos de archivos al azar. Ya lo he dicho, .odt los archivos ya son archivos zip. Por lo tanto, la modesta ganancia obtenida al comprimirlos por segunda vez no es sorprendente (excepto bzip2 o xy, pero yo lo haría considere eso como una anomalía estadística causada por la baja heterogeneidad de mis archivos de datos, que contienen varias copias de seguridad o versiones de trabajo de los mismos documentos).
Sobre .jpg , .mp3 y .mp4 ahora:tal vez sepas que esos ya archivo de datos comprimido. Aún mejor, es posible que haya escuchado que usan compresión destructiva . Eso significa que no puede reconstruir exactamente la imagen original después de una compresión JPEG. Y eso es cierto. Pero lo que se sabe poco es después de la fase de compresión destructiva per se , los datos se comprimen por segunda vez mediante el algoritmo no destructivo de longitud de palabra variable de Huffman para eliminar la redundancia de datos.
Por todas esas razones, se esperaba que la compresión de imágenes JPEG o archivos MP3/MP4 no dejara grandes ganancias. Tenga en cuenta que, dado que un archivo típico contiene datos altamente comprimidos y algunos metadatos sin comprimir, aún podemos obtener algo allí. Esto explica por qué todavía tengo una ganancia notable para las imágenes JPEG, ya que tenía muchas de ellas, por lo que el tamaño general de los metadatos no fue tan insignificante en comparación con el tamaño total del archivo. Una vez más, los sorprendentes resultados al comprimir archivos MP4 usando xz probablemente estén relacionados con las altas similitudes entre los diversos archivos MP4 utilizados durante mis pruebas. ¿O no lo son?
Para disipar esas dudas con el tiempo, le recomiendo enfáticamente que haga sus propias comparaciones. ¡Y no dude en compartir sus observaciones con nosotros usando la sección de comentarios a continuación!