Si leyó mi primer artículo sobre el uso de Keepalived para administrar la conmutación por error simple en clústeres, entonces recordará que VRRP utiliza el concepto de prioridad al determinar qué servidor será el maestro activo. El servidor con la prioridad más alta "gana" y actuará como maestro, conservando las solicitudes VIP y de servicio. Keepalived proporciona varios métodos útiles para ajustar la prioridad según el estado de su sistema. En este artículo, explorará varios de estos mecanismos, junto con Keepalived la capacidad de ejecutar scripts cuando cambia el estado de un servidor.
Solo mostraré la configuración en el servidor 1 para estos ejemplos. En este punto, probablemente se sienta cómodo con la configuración necesaria en el servidor 2 si ha estado leyendo toda la serie. Si no, tómese un momento para revisar el primer y segundo artículo de esta serie antes de continuar.
- Uso de Keepalived para administrar la conmutación por error simple en clústeres
- Configuración de un clúster de Linux con Keepalived:configuración básica
Símbolos de red en los diagramas disponibles a través de VRT Network Equipment Extension, CC BY-SA 3.0.
Keepalived hace un gran trabajo al activar una conmutación por error cuando no se reciben anuncios, como cuando el maestro activo muere por completo o no se puede acceder por alguna otra razón. Sin embargo, a menudo encontrará que se necesitan mecanismos de activación más detallados. Por ejemplo, su aplicación puede ejecutar sus propias comprobaciones de estado para determinar la capacidad de la aplicación para atender las solicitudes de los clientes. No querrías que un servidor de aplicaciones en mal estado siguiera siendo el maestro activo solo porque estaba vivo y enviando VRRP anuncios.
Nota:encontré que la versión de Keepalived disponible a través de los repositorios de paquetes estándar contenía errores que impedían que algunos de los siguientes ejemplos funcionaran correctamente. Si tiene problemas, es posible que desee instalar Keepalived de la fuente, como se describe en el artículo anterior.
Procesos de seguimiento
Uno de los Keepalived más comunes Las configuraciones implican el seguimiento de un proceso en el servidor para determinar el estado del host. Por ejemplo, puede configurar un par de servidores web de alta disponibilidad y activar una conmutación por error si Apache deja de ejecutarse en uno de ellos.
Keepalived lo hace fácil a través de su track_process directivas de configuración. En el siguiente ejemplo, configuré Keepalived para ver el httpd proceso con un peso de 10. Siempre que httpd se está ejecutando, la prioridad anunciada será 254 (244 + 10 =254). Si httpd deja de ejecutarse, la prioridad bajará a 244 y activará una conmutación por error (suponiendo que exista una configuración similar en el servidor 2).
server1# cat keepalived.conf
vrrp_track_process track_apache {
process httpd
weight 10
}
vrrp_instance VI_1 {
state MASTER
interface eth0
virtual_router_id 51
priority 244
advert_int 1
authentication {
auth_type PASS
auth_pass 12345
}
virtual_ipaddress {
192.168.122.200/24
}
track_process {
track_apache
}
} Con esta configuración en su lugar (y Apache instalado y ejecutándose en ambos servidores), puede probar un escenario de conmutación por error deteniendo Apache y observando cómo el VIP se mueve del servidor 1 al servidor 2:
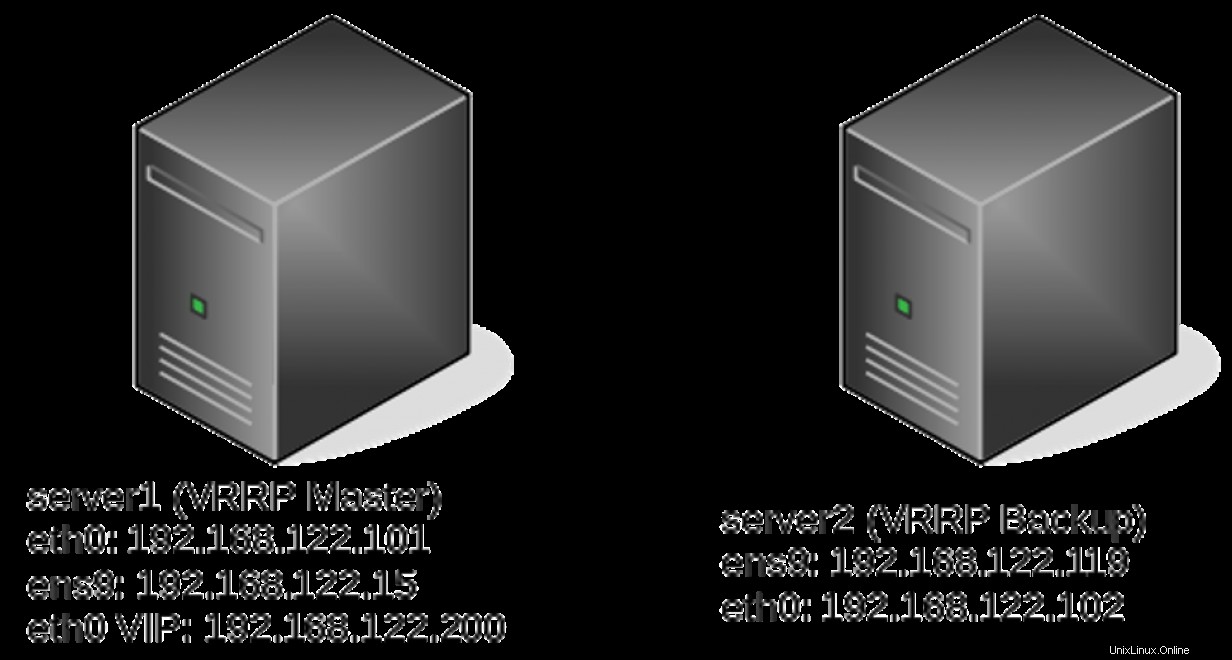
server1# ip -br a
lo UNKNOWN 127.0.0.1/8 ::1/128
eth0 UP 192.168.122.101/24 192.168.122.200/24 fe80::5054:ff:fe82:d66e/64
server1# systemctl stop httpd
server1# ip -br a
lo UNKNOWN 127.0.0.1/8 ::1/128
eth0 UP 192.168.122.101/24 fe80::5054:ff:fe82:d66e/64
server2# ip -br a
lo UNKNOWN 127.0.0.1/8 ::1/128
eth0 UP 192.168.122.102/24 192.168.122.200/24 fe80::5054:ff:fe04:2c5d/64 Archivos de seguimiento
Keepalived también tiene la capacidad de tomar decisiones de prioridad basadas en el contenido de un archivo, lo que puede ser útil si está ejecutando una aplicación que puede escribir valores en este archivo. Por ejemplo, es posible que tenga un proceso en segundo plano en su aplicación que periódicamente realiza una verificación de estado y escribe un valor en un archivo en función del estado general de la aplicación.
El Keepalived La página de manual explica que el seguimiento de archivos se basa en el peso configurado para el archivo:
“el valor se leerá como un número en el texto del archivo. Si el peso configurado en el archivo de seguimiento es 0, un valor distinto de cero en el archivo se tratará como un estado de error y un valor cero se tratará como un estado correcto; de lo contrario, el valor se multiplicará por el peso configurado en el instrucción track_file. Si el resultado es inferior a -253, cualquier instancia de VRRP o grupo de sincronización que supervise la secuencia de comandos pasará al estado de error (el peso puede ser 254 para permitir que se lea un valor negativo del archivo)".
Mantendré las cosas simples y usaré un peso de 1 para el archivo de seguimiento en este ejemplo. Esta configuración tomará el valor numérico en el archivo en /var/run/my_app/vrrp_track_file y multiplícalo por 1.
server1# cat keepalived.conf
vrrp_track_file track_app_file {
file /var/run/my_app/vrrp_track_file
}
vrrp_instance VI_1 {
state MASTER
interface eth0
virtual_router_id 51
priority 244
advert_int 1
authentication {
auth_type PASS
auth_pass 12345
}
virtual_ipaddress {
192.168.122.200/24
}
track_file {
track_app_file weight 1
}
}
Ahora puede crear el archivo con un valor inicial y reiniciar Keepalived . La prioridad se puede ver en tcpdump salida, como se analiza en el segundo artículo de esta serie.
server1# mkdir /var/run/my_app
server1# echo 5 > /var/run/my_app/vrrp_track_file
server1# systemctl restart keepalived
server1# tcpdump proto 112
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on eth0, link-type EN10MB (Ethernet), capture size 262144 bytes
16:19:32.191562 IP server1 > vrrp.mcast.net: VRRPv2, Advertisement, vrid 51, prio 249, authtype simple, intvl 1s, length 20 Puede ver que la prioridad anunciada es 249, que es el valor en el archivo (5) multiplicado por el peso (1) y sumado a la prioridad base (244). Del mismo modo, ajustar la prioridad a 6 aumentará la prioridad:
server1# echo 6 > /var/run/my_app/vrrp_track_file
server1# tcpdump proto 112
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on eth0, link-type EN10MB (Ethernet), capture size 262144 bytes
16:20:43.214940 IP server1 > vrrp.mcast.net: VRRPv2, Advertisement, vrid 51, prio 250, authtype simple, intvl 1s, length 20 Interfaz de pista
Para servidores con múltiples interfaces, puede ser útil ajustar la prioridad de Keepalived instancia basada en el estado de una interfaz. Por ejemplo, un equilibrador de carga con una interfaz VIP y una conexión de backend a una red interna podría querer activar un Keepalived conmutación por error si la conexión a la red back-end se cae. Esto se puede lograr con la configuración track_interface:
server1# cat keepalived.conf
vrrp_instance VI_1 {
state MASTER
interface eth0
virtual_router_id 51
priority 244
advert_int 1
authentication {
auth_type PASS
auth_pass 12345
}
virtual_ipaddress {
192.168.122.200/24
}
track_interface {
ens9 weight 5
}
} La configuración anterior asigna un peso de 5 al estado de la interfaz ens9. Esto hará que server1 asuma una prioridad de 249 (244 + 5 =249) siempre que ens9 esté activo. Si ens9 falla, la prioridad bajará a 244 (y activará una conmutación por error, suponiendo que server2 esté configurado de la misma manera). Puede probar esto en un servidor multi-interfaz apagando una interfaz y observando el movimiento VIP entre hosts:
server1# ip -br a
lo UNKNOWN 127.0.0.1/8 ::1/128
eth0 UP 192.168.122.101/24 192.168.122.200/24 fe80::5054:ff:fe82:d66e/64
ens9 UP 192.168.122.15/24 fe80::7444:5ec4:8015:722f/64
server1# ip link set ens9 down
server1# ip -br a
lo UNKNOWN 127.0.0.1/8 ::1/128
eth0 UP 192.168.122.101/24 fe80::5054:ff:fe82:d66e/64
ens9 DOWN
server2# ip -br a
lo UNKNOWN 127.0.0.1/8 ::1/128
ens9 UP 192.168.122.119/24 fe80::fc9f:8999:b93e:d491/64
eth0 UP 192.168.122.102/24 192.168.122.200/24 fe80::5054:ff:fe04:2c5d/64 Guión de pista
Has visto que Keepalived ofrece una gran cantidad de útiles métodos de verificación integrados para determinar la salud y el subsiguiente VRRP prioridad de un anfitrión. Sin embargo, a veces, los entornos más complejos requieren el uso de herramientas personalizadas, como secuencias de comandos de verificación de estado, para satisfacer sus necesidades. Afortunadamente, Keepalived también tiene la capacidad de ejecutar un script arbitrario para determinar la salud de un host. Puede ajustar el peso de la secuencia de comandos, pero voy a mantener las cosas simples para este ejemplo:una secuencia de comandos que devuelve 0 indicará éxito, mientras que una secuencia de comandos que devuelve cualquier otra cosa indicará que Keepalived la instancia debe entrar en estado de error.
El script es un simple ping al 8.8.8.8 favorito de todos. Servidor DNS de Google, como se ve a continuación. En su entorno, probablemente utilizará un script más complejo para realizar las comprobaciones de estado que necesite.
server1# cat /usr/local/bin/keepalived_check.sh
#!/bin/bash
/usr/bin/ping -c 1 -W 1 8.8.8.8 > /dev/null 2>&1
Notarás que usé un tiempo de espera de 1 segundo para ping (-W 1). Al escribir Keepalived verifique los scripts, es una buena idea mantenerlos livianos y rápidos. No desea que un servidor averiado siga siendo el maestro durante mucho tiempo porque su secuencia de comandos es lenta.
El Keepalived la configuración para un script de verificación se muestra a continuación:
server1# cat keepalived.conf
vrrp_script keepalived_check {
script "/usr/local/bin/keepalived_check.sh"
interval 1
timeout 5
rise 3
fall 3
}
vrrp_instance VI_1 {
state MASTER
interface eth0
virtual_router_id 51
priority 244
advert_int 1
authentication {
auth_type PASS
auth_pass 12345
}
virtual_ipaddress {
192.168.122.200/24
}
track_script {
keepalived_check
}
}
Esto se parece mucho a la configuración con la que has estado trabajando, pero el vrrp_script bloque tiene algunas directivas únicas:
interval:Con qué frecuencia se debe ejecutar el script (1 segundo).timeout:cuánto tiempo esperar para que regrese el script (5 segundos).rise:cuántas veces la secuencia de comandos debe devolverse correctamente para que el host se considere "bueno". En este ejemplo, el script debe regresar con éxito 3 veces. Esto ayuda a prevenir una condición de "flapping" donde una sola falla (o éxito) causa elKeepalivedEstado para cambiar rápidamente de un lado a otro.fall:cuántas veces la secuencia de comandos debe volver sin éxito (o expirar) para que el host se considere "en mal estado". Esto funciona como el reverso de la directiva rise.
Puede probar esta configuración forzando el error del script. En el siguiente ejemplo, agregué un iptables regla que impide la comunicación con 8.8.8.8 . Esto hizo que la comprobación de salud fallara y el VIP desapareciera después de unos segundos. Luego puedo eliminar la regla y ver cómo reaparece el VIP.
server1# iptables -I OUTPUT -d 8.8.8.8 -j DROP
server1# ip -br a
lo UNKNOWN 127.0.0.1/8 ::1/128
eth0 UP 192.168.122.101/24 fe80::5054:ff:fe82:d66e/64
server1# iptables -D OUTPUT -d 8.8.8.8 -j DROP
server1# ip -br a
lo UNKNOWN 127.0.0.1/8 ::1/128
eth0 UP 192.168.122.101/24 192.168.122.200/24 fe80::5054:ff:fe82:d66e/64
Un consejo rápido sobre scripts en Keepalived :Se pueden ejecutar como un usuario diferente además de root. Si bien no demostré eso en estos ejemplos, eche un vistazo a la página de manual y asegúrese de estar usando el usuario con menos privilegios posible para evitar cualquier implicación negativa de seguridad de su secuencia de comandos de verificación.
Guiones de notificación
He estado discutiendo formas de activar Keepalived respuestas basadas en condiciones externas. Sin embargo, probablemente también desee activar acciones cuando Keepalived transiciones de un estado a otro. Por ejemplo, es posible que desee detener un servicio cuando Keepalived ingresa al estado de copia de seguridad, o es posible que desee enviar un correo electrónico a un administrador. Keepalived le permite hacer esto con scripts de notificación.
Keepalived proporciona varias directivas de notificación solo para llamar a scripts en estados particulares (notify_master , notify_backup , etc), pero me voy a centrar en el simple notify ya que es la más flexible. Cuando un script en el notify se llama a la directiva, recibe cuatro argumentos adicionales (después de los argumentos que se pasan al propio script).
Enumerados en orden, estos son:
- Grupo o instancia:Indicación de si la notificación se activa por un
VRRPgrupo (no discutido en esta serie) o unVRRPparticular instancia. - Nombre del grupo o instancia
- Indique que el grupo o instancia está en transición
- La prioridad
Echando un vistazo a un ejemplo hace que esto sea más claro. El guión y Keepalived la configuración se ve así:
server1# cat /usr/local/bin/keepalived_notify.sh
#!/bin/bash
echo "$1 $2 has transitioned to the $3 state with a priority of $4" > /var/run/keepalived_status
server1# cat keepalived.conf
vrrp_script keepalived_check {
script "/usr/local/bin/keepalived_check.sh"
interval 1
timeout 5
rise 3
fall 3
}
vrrp_instance VI_1 {
state MASTER
interface eth0
virtual_router_id 51
priority 244
advert_int 1
authentication {
auth_type PASS
auth_pass 12345
}
virtual_ipaddress {
192.168.122.200/24
}
track_script {
keepalived_check
}
notify "/usr/local/bin/keepalived_notify.sh"
}
La configuración anterior llamará a /usr/local/bin/keepalived_notify.sh script cada vez que un Keepalived se produce la transición de estado. Dado que el mismo script de verificación está en su lugar, puede inspeccionar fácilmente el estado inicial y luego activar una transición:
server1# cat /var/run/keepalived_status
INSTANCE VI_1 has transitioned to the MASTER state with a priority of 244
server1# iptables -A OUTPUT -d 8.8.8.8 -j DROP
server1# cat /var/run/keepalived_status
INSTANCE VI_1 has transitioned to the FAULT state with a priority of 244
server1# iptables -D OUTPUT -d 8.8.8.8 -j DROP
server1# cat /var/run/keepalived_status
INSTANCE VI_1 has transitioned to the MASTER state with a priority of 244
Puede ver que los argumentos de la línea de comando corresponden a los que describí al principio de esta sección. Obviamente, este es un ejemplo simple, pero los scripts de notificación pueden realizar muchas acciones complejas, como ajustar las reglas de enrutamiento o activar otros scripts. Son una forma útil de realizar acciones externas basadas en Keepalived cambios de estado.
Conclusión
Este artículo cerró un Keepalived fundamental serie con algunos conceptos avanzados. Aprendiste a activar Keepalived cambios de prioridad y estado basados en eventos externos, como el estado del proceso, cambios en la interfaz e incluso los resultados de scripts externos. También aprendió cómo activar scripts de notificación en respuesta a Keepalived cambios de estado. Puede combinar dos o más de estos enfoques para crear un par de servidores Linux de alta disponibilidad que respondan a múltiples estímulos externos y garanticen que el tráfico siempre llegue a una dirección IP saludable que pueda atender las solicitudes de los clientes.
[ ¿Desea obtener más información sobre la administración del sistema? Realice un curso en línea gratuito:Descripción general técnica de Red Hat Enterprise Linux. ]